2026-05-08 20:15:00
2026-05-08 20:15:00
智猩猩AI整理
编辑:林夕
多模态大模型想要看懂图像、读懂文字,核心在于视觉编码器。过去很长一段时间,CLIP、SigLIP这类对比学习范式占据主导。它们把图文预训练变成了配对任务,判断图像和文本是否匹配,相似拉近、不相似推开,存在与大模型生成式目标不匹配的问题。这套思路在检索、分类上很稳,却和MLLM的真实需求错位。
只做全局对齐的视觉编码器,往往只抓住图像大意,却丢失了可生成、可推理、可追问的细粒度视觉信息。
后来的生成式方法有所改进,在视觉编码器后接入文本解码器,像CapPa、AIMv2这类编码器-解码器结构,让模型能够生成图像描述。但问题依然存在,语言预测由解码器主导完成,ViT仅被间接优化,视觉模型始终没有真正参与到语言生成的核心过程中。
针对这些痛点,字节跳动联合北京交通大学、南洋理工大学提出生成式语言-图像预训练方法GenLIP,让ViT像一个语言模型一样,直接根据图像内容来“说话”,预测文本单词。实验显示,GenLIP仅用8B预训练数据,就显著超越了40B数据规模训练的SigLIP2,在OCR类任务上平均提升5.9个百分点,整体综合指标ALL AVG提升3.7个百分点,以更少的数据实现更强的多模态理解能力。

论文标题:Let ViT Speak: Generative Language-Image Pre-training
论文链接:https://arxiv.org/pdf/2605.00809v1
github地址:https://github.com/YanFangCS/GenLIP
01 核心创新
GenLIP采用极简单的Transformer架构,训练一个ViT直接"说话",全程仅用自回归语言建模目标,让ViT直接从视觉Token预测文本Token,彻底抛弃对比损失、双塔结构与额外文本解码器,天然适配多模态大模型的生成范式。
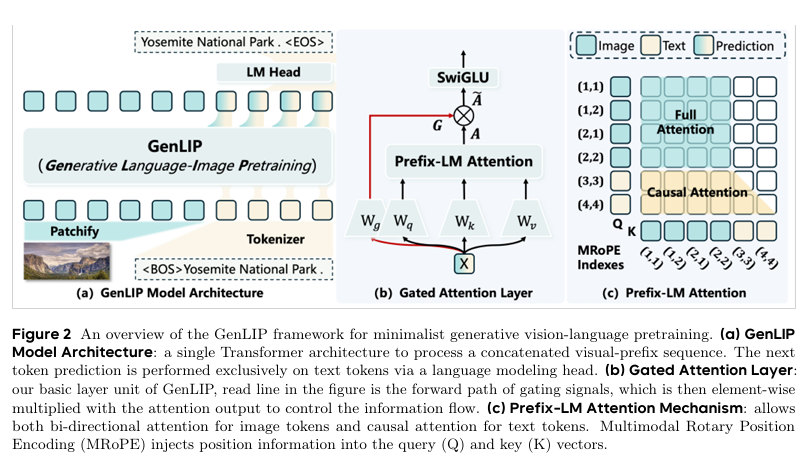
(一)整体架构
模型以图像-文本对为基本输入单元。图像经卷积补丁嵌入拆分为视觉Token序列,文本经Qwen3分词器得到语言Token序列,按视觉在前、文本在后拼接为统一输入序列:
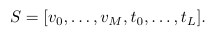
模型架构采用单一Transformer编码器,搭配模态专属嵌入层、Prefix-LM注意力机制、层归一化与语言建模头。为适配多模态序列建模,研究做两处关键改进:
一是使用多模态旋转位置编码MRoPE替代图像绝对位置嵌入,精准编码序列位置信息;
二是采用Prefix-LM注意力,视觉Token执行双向注意力以充分捕捉全局视觉信息,文本Token执行因果注意力契合LLM生成特性。
训练仅使用单一自回归语言建模损失,仅对文本Token执行下一个Token预测,直接建模图像条件下文本生成概率,使视觉编码器与MLLM生成范式天然对齐。作为视觉编码器使用时,丢弃分词器与语言建模头,提取最后层归一化视觉特征,经两层MLP投影即可接入LLM,Prefix-LM注意力退化为标准全注意力专注视觉建模。
(二)门控注意力
在Prefix-LM注意力机制范式下,首个视觉Token可被所有后续文本Token单向关注,模型会自发将全局视觉信息过度压缩至少量视觉Token中,进而引发注意力分布极端失衡。
该问题会直接诱发训练不稳定、损失尖峰震荡,同时造成视觉表征性能退化;训练过程中还会出现显著的注意力下沉现象,致使图像细粒度视觉特征大量流失、训练波动进一步加剧。
针对上述缺陷,GenLIP引入门控注意力机制,以逐Token动态调控跨模态信息流,约束文本端过度聚焦个别视觉Token的行为,有效保留视觉特征的空间多样性,同时平稳训练过程、收敛训练波动。
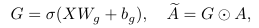
下图展示了有无门控注意力时,第一个Token在不同网络层的注意力得分变化。无门控机制时模型出现明显注意力下沉,首个视觉Token 吸收大量注意力权重,ImageNet-1K线性探测准确率下降约8个点,加入门控后注意力分布更均匀,判别与生成性能同步提升。
(三)两阶段预训练策略
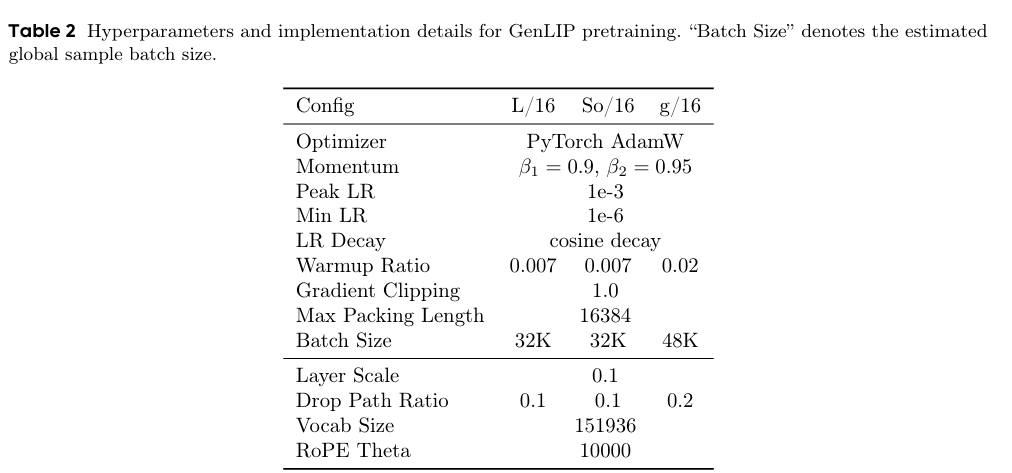
第一阶段(固定分辨率预训练):在Recap-DataComp-1B上以224×224固定分辨率完成80亿样本训练,学习基础视觉–语言对齐表征。
第二阶段(原生宽高比适配):在Infinity-MM、BLIP3o-Long-Caption上采用原生宽高比输入,将视觉Token数量控制在16–1024。

02 实验结果分析
实验基于LLaVA-NeXT框架,以CLIP、SigLIP、SigLIP2、AIMv2、OpenVision2为基线模型,采用冻结视觉编码器、仅微调 LLM的评估协议,搭配Qwen2.5-1.5B/7B大语言模型,在Doc&OCR、General VQA、Caption 三大类14项基准上全面评测,并通过消融实验验证核心设计有效性。
(一)SOTA对比
主实验结果显示,GenLIP在三种规模下均超越使用40B样本预训练的SigLIP2等基线。Qwen2.5-1.5B设置下,GenLIP-g/16的ALL AVG达65.2,较SigLIP2提升3.7分。
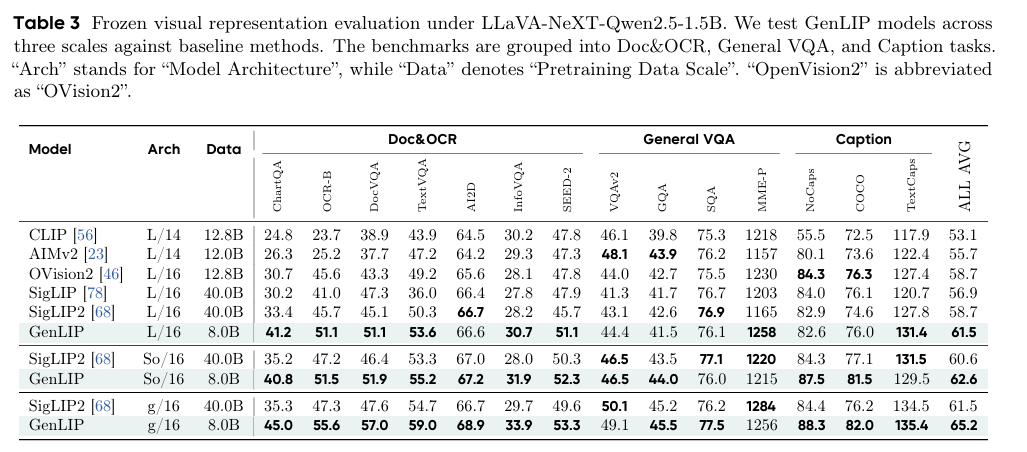
扩展至Qwen2.5-7BLLM,趋势保持一致,So/16与g/16尺度整体平均分分别领先2.4、4.7 分,Doc&OCR任务持续领跑。
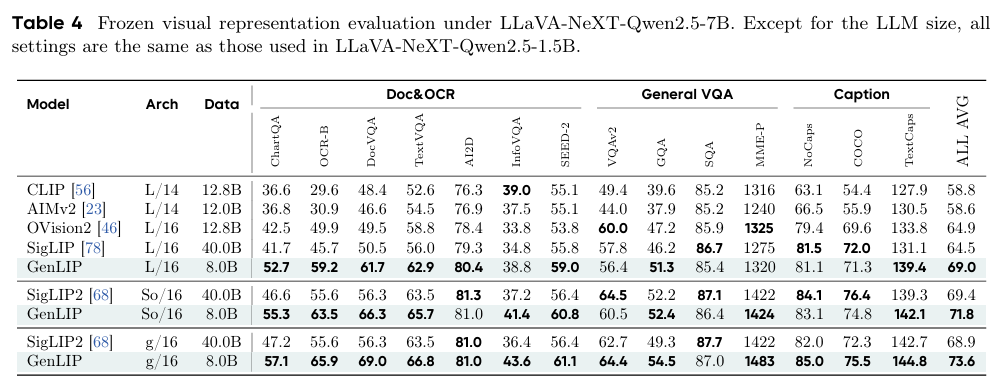
标准LLaVA-NeXT全微调设置下,GenLIP在576、729两种Patch预算下,ALL AVG分别达68.5与70.3,Doc&OCR任务优势显著,验证其在实际MLLM部署中的实用性。
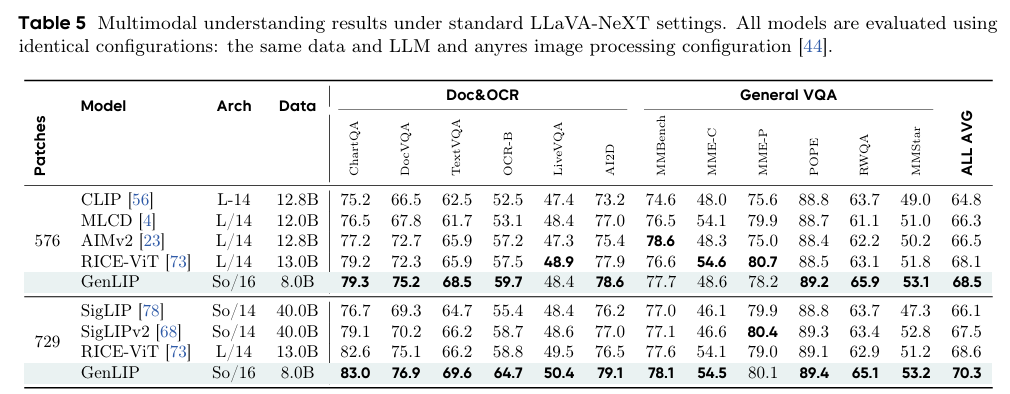
(二)可扩展性验证
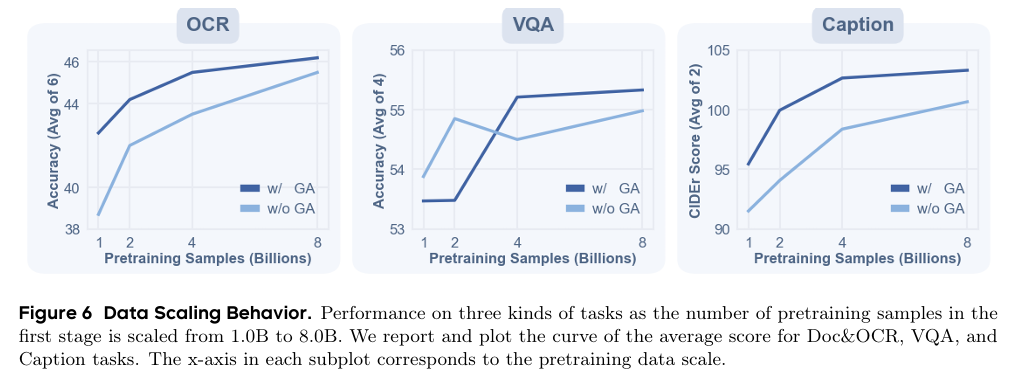
数据可扩展性方面,预训练样本从1B增至8B,GenLIP在OCR、VQA、Caption任务上持续提升,4B至8B阶段增益趋缓,门控注意力在全数据尺度均带来稳定提升,低数据域优势更明显。
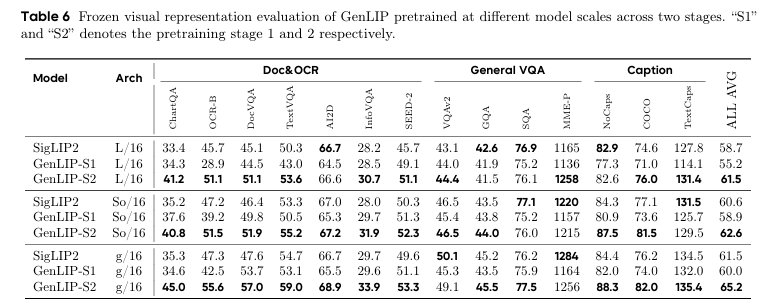
两阶段训练中GenLIP随规模增大性能稳步提升,g/16版本在Doc&OCR任务上优势最明显,证明合适的模型容量能强化视觉表征学习。
(三)消融实验
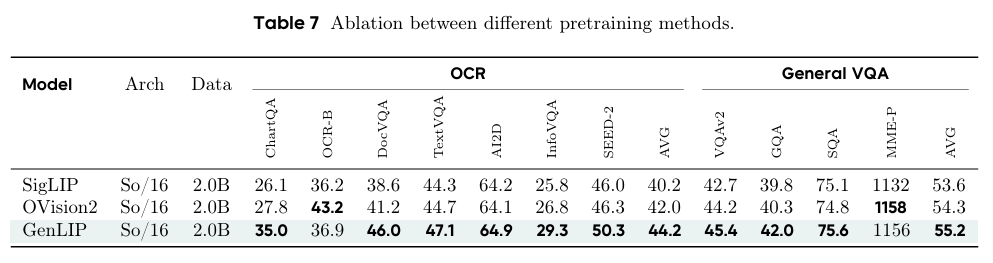
同等2B数据预算下,GenLIP在多数OCR与VQA任务上超越SigLIP与 OpenVision2,ALL AVG 分别高出1.6与0.9分,仅OCRBench略低于 OpenVision2,验证其极高的数据效率。
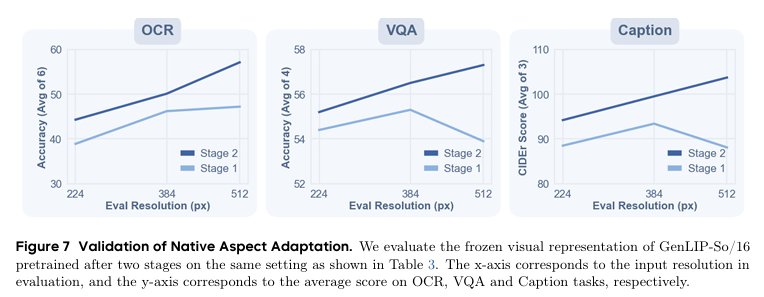
原生宽高比适配实验显示,第二阶段训练后模型在224至512多分辨率评估中,OCR、VQA、描述任务得分全面优于第一阶段,高分辨率下提升更显著,证明原生比例处理能保留更多细节信息,适配细粒度视觉理解需求。
(四)判别性能力实验
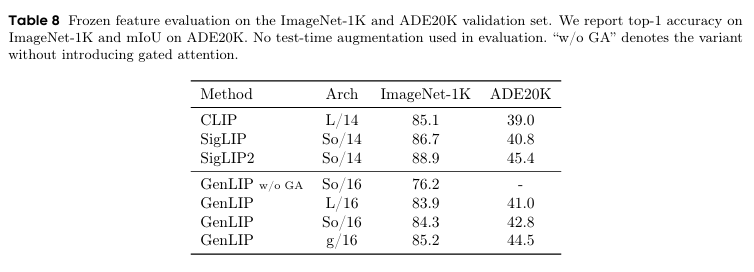
判别能力测试中,GenLIP在无显式视觉监督下,于ImageNet-1K分类与ADE20K语义分割任务表现可观,g/16尺度模型ImageNet-1K top-1精度达85.2,ADE20K mIoU为44.5,超越同尺度CLIP与SigLIP,证明生成式预训练可学习优质判别性视觉特征。
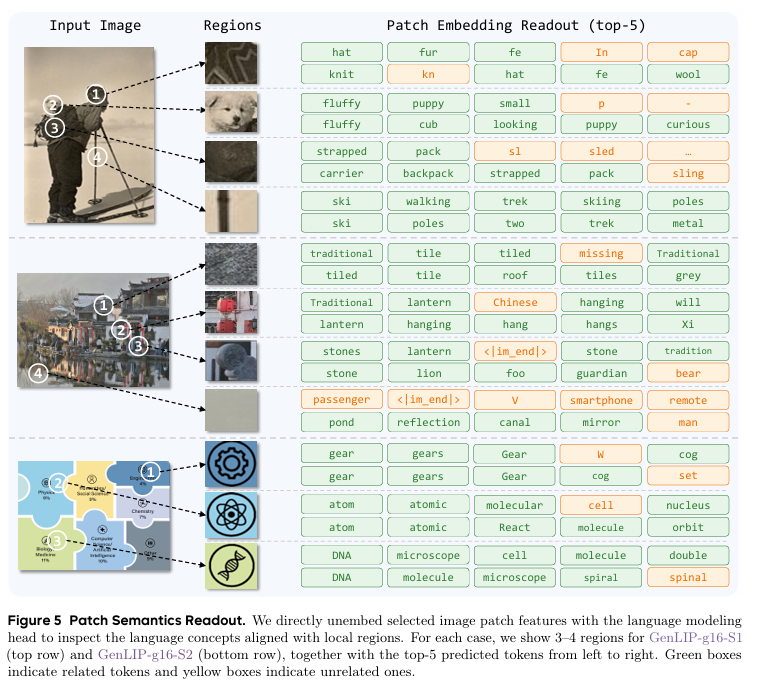
(五)生成能力与Patch语义实验
GenLIP采用生成式预训练,可直接基于图像完成文本生成,并将局部图像Patch 映射为文本Token,直观验证视觉-语言的细粒度对齐效果。
在图像描述生成实验中,模型可输出流畅、语义准确的描述语句。第二阶段原生分辨率适配后,生成内容细节更丰富;随模型规模提升,目标识别更精准,大模型能正确区分易混淆物体,小模型则易出现类别错误。

在Patch语义读出实验中,模型无需额外监督,即可将局部图像区域解码为对应语义词汇,如帽子、背包、建筑构件等,实现局部视觉与语言的自发对齐。经过第二阶段训练,语义匹配准确度与相关性显著提升,无关预测大幅减少。
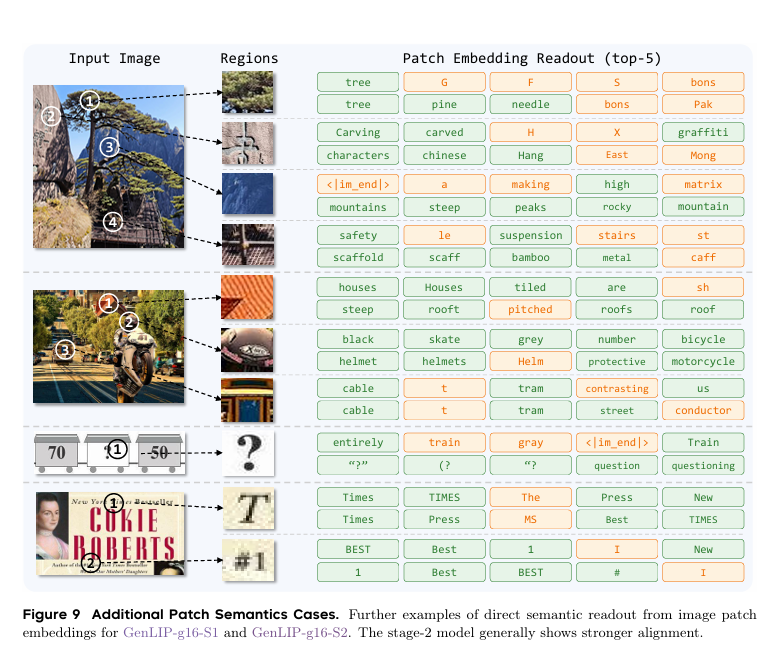
在OCR密集场景下,GenLIP未经过专门训练即可完成发票、几何图形、微小文字的识别与结构理解,大模型在长数字、表格、细小组件上表现更稳定,整体具备较强的细粒度图文理解能力。

03 结论
GenLIP以单Transformer架构与单一自回归生成目标,实现极简高效的视觉语言预训练,解决了现有方法架构冗余、目标不匹配、优化间接的问题,兼具简洁性、数据高效性与强可扩展性。仅用8B预训练样本,即可在Doc&OCR、General VQA、Caption等任务上超越大语料预训练的基线,原生宽高比适配进一步强化细粒度感知能力,为 MLLM 视觉编码器的研发提供了更直接、高效的技术路径。

 关注公众号
关注公众号