2026-04-24 18:22:00
2026-04-24 18:22:00
重庆大学团队投稿
智猩猩AI整理
生成式推荐正在成为推荐系统的重要方向。与传统推荐的排序式方法不同,这类方法开始直接生成商品对应的语义 ID,看上去已经从“选结果”走向了“生结果”。但一个关键问题仍未真正解决:当前大量方法虽然模型形态变了,训练目标却依然主要围绕下一物品预测展开,更容易利用最近几步行为中的局部模式,却不一定真正理解用户历史路径中的逻辑依赖、长期需求和潜在意图。换句话说,现有生成式推荐更擅长回答“下一个是什么”,却还缺少对“这条历史为什么会这样展开”的理解。
针对这一问题,重庆大学钟将、魏楷文等研究团队提出一种全新的训练框架Masked History Learning(MHL)。该方法在标准自回归下一物品预测之外,引入历史重建学习,让模型在预测未来的同时反过来补全被遮蔽的历史行为;同时结合熵引导遮蔽与三阶段课程学习,把训练重点从局部预测推进到路径理解。实验结果显示,MHL 在 Amazon Reviews 2014 的 Beauty、Toys and Games、Sports and Outdoors 三个数据集上均取得最优表现;以强基线 RPG 为参照,NDCG@10 分别提升了 13.5%、22.6% 和 21.1%。该成果已收录至ACL 2026 Main。

论文标题:From Past To Path: Masked History Learning for Next-Item Prediction in Generative Recommendation
论文链接:https://arxiv.org/abs/2509.23649
GitHub 代码仓库:https://github.com/CQU-MM-Intelligent-Lab/MHL
01 方法
这项工作的核心思路,可以概括成一句很直观的话:与其只让模型盯着“下一个商品”,不如进一步逼它理解“用户为什么会一步步走到这里”。 为此,MHL 保留了原本的下一物品预测任务,同时增加了一个辅助目标:从用户历史中遮住部分 item 或 token,再让模型把它们恢复出来。这样一来,模型训练时不只是顺着行为链往后猜,而是必须重新回到上下文中,理解这些历史片段为什么会一起出现、它们之间到底存在什么关系。研究团队在方法设计中明确把这两部分联合起来:一边做 next-item prediction,一边做 masked history reconstruction,让模型从“预测结果”走向“理解过程”。
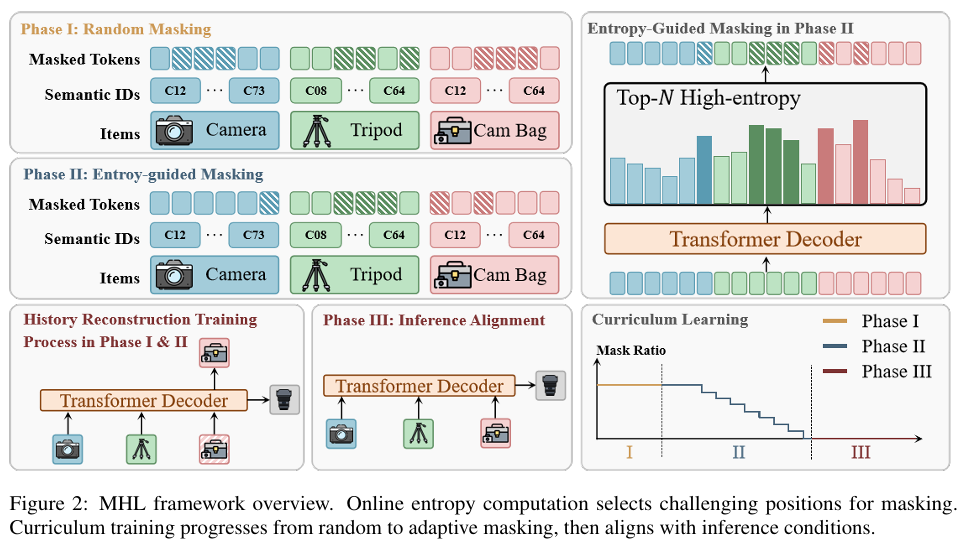
图1 MHL 整体架构
(1)预测的同时,还要重建历史
如果把传统生成式推荐类比成“看一句话前半句,猜最后一个词”,那么 MHL 更像是“把句子中间几个关键词擦掉,再让模型补回来”。后者显然更难,但也更有价值,因为模型不能只靠表面惯性往后接,而必须真正理解上下文。围绕这个目标,研究团队设计了三种不同粒度的 masking。
(i)Item-level masking 会直接遮住完整商品,更强调 item 与 item 之间的整体依赖;
(ii)token-level masking 只遮住商品内部的一部分语义 token,更强调细粒度语义结构;
(iii)mixed-level masking 则在两者之间随机切换,在整体语义理解与局部结构建模之间取得平衡。简单来说,这三种方式对应的是三种不同难度和不同粒度的训练题,目的都是让模型真正学会“从历史里找线索”。
(2)熵引导 Mask:优先遮住关键位置
但研究团队并没有停留在“加一个 mask 任务”上。因为用户历史里的信息密度并不均匀,有些行为只是普通过渡,有些行为才是真正暴露意图的关键节点。于是,MHL 进一步引入了 Entropy-Guided Masking。具体做法是:先让当前模型对未遮蔽序列做一次无梯度前向计算,估计每个位置的预测熵;熵越高,说明模型对这个位置越不确定,它也越可能是值得重点学习的位置。 最终,MHL 会优先遮蔽这些高熵位置,再要求模型把它们补回来。这个设计可以理解成“针对薄弱点强化训练”:随机 masking 像平均出题,而熵引导 masking 更像专门挑那些模型最没看懂、但又最关键的内容来反复训练。
(3)先懂历史,再学会生成
除此之外,研究团队还设计了三阶段课程学习,把“懂历史”和“会生成”接成了一条连续路径。第一阶段先用低比例随机 masking 预热,把模型训稳;第二阶段切换到熵引导 masking,并逐步降低 mask ratio,让模型从更强调历史理解,逐渐过渡到更强调未来预测;第三阶段再把 mask ratio 降到 0,只保留下一物品预测,使训练状态和推理状态完全对齐。也就是说,MHL 并不是简单往 loss 里塞一个辅助项,而是重新组织了模型的学习顺序:先学会理解历史,再带着这种理解去预测未来。 这正是它能够直接回应前面那个核心问题的地方。
02 评估
(1)主结果全面领先
实验部分,研究团队在 Amazon Reviews 2014 的Beauty、Toys and Games、Sports and Outdoors 三个子数据集上进行了系统验证,并对比了两大类方法:
(i) item ID-based 方法,如 GRU4Rec、SASRec、BERT4Rec 等;
(ii)semantic ID-based 方法,如 RecJPQ、VQ-Rec、TIGER、HSTU、RPG。
评测指标采用推荐任务中最常用的 Recall@5/10 和 NDCG@5/10。尤其值得注意的是,MHL 使用的 backbone 与 RPG 保持一致,推理阶段同样采用 graph-constrained beam search,因此两者的主要差异不在模型骨干,而在训练目标和训练策略本身。
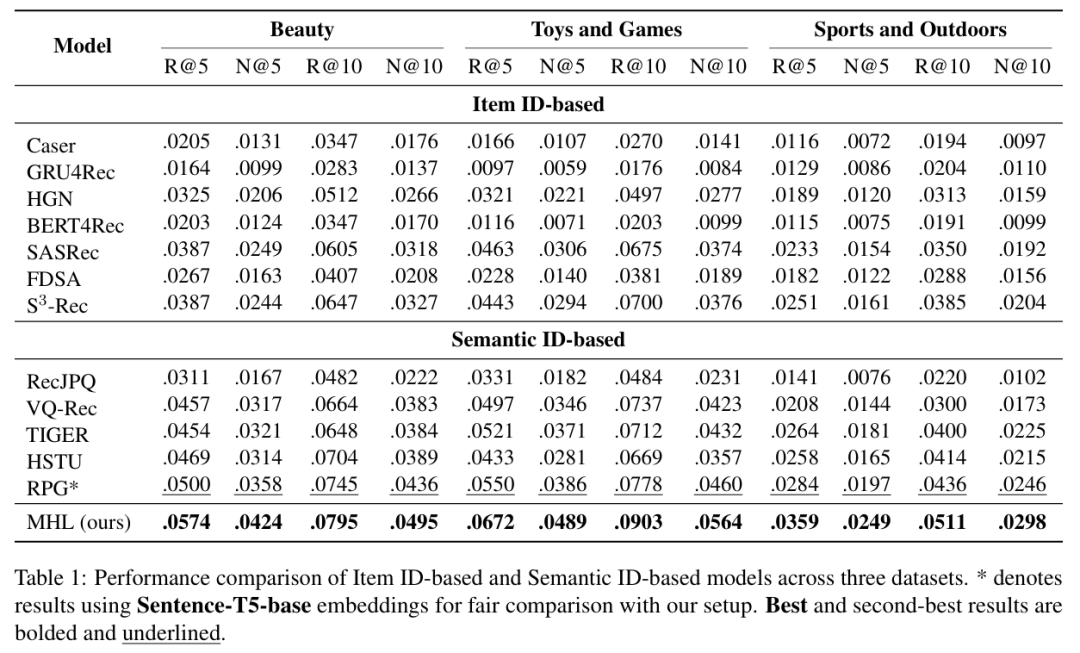
表1 MHL 与当前生成式推荐模型效果对比
主结果表明,MHL 在三个数据集上的核心指标都取得了最好结果。以 NDCG@10 为例,Beauty 上从 RPG 的 0.0436 提升到 0.0495,Toys and Games 上从 0.0460 提升到 0.0564,Sports and Outdoors 上从 0.0246 提升到 0.0298。如果换算成相对提升,分别约为 13.5%、22.6%、21.1%。这说明 MHL 的收益并不是局部、偶然的,而是在不同商品类别中都能稳定成立。更重要的是,这组结果说明:仅仅改变训练范式,不改 backbone,就足以带来显著性能提升。研究团队还进一步指出,相比 TIGER,MHL 在 Sports and Outdoors 上的 NDCG@5 提升达到 37.6%,在更复杂、更难抽象用户意图的场景中优势尤其明显。
(2)三部分设计缺一不可
除了总结果,这项工作的分析也比较完整。消融实验显示,不加 masking 的 direct inference 最弱;加入 masking 后整体更强;完整的 R→E→Inf 三阶段训练效果最好,说明 MHL 的收益并不是来自单一 trick,而是“历史重建 + 高熵采样 + 课程学习”三者共同作用的结果。
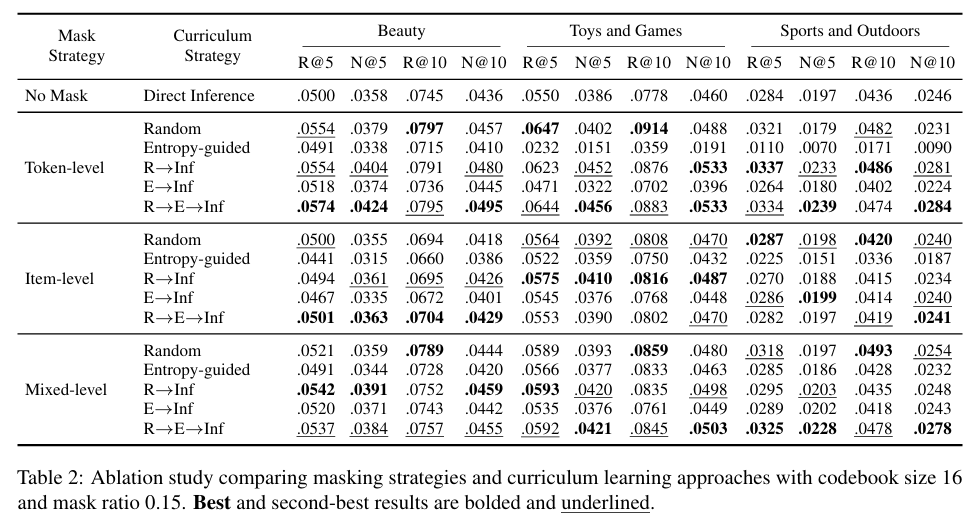
表2 MHL 采用不同课程设计效果对比
(3)不只对 semantic ID 有效
进一步地,研究团队还将该方法应用到由商品标题构成的原始文本 token 序列上,结果显示 NDCG@10 仍能分别相对提升 10.5%、8.8%、14.5%,说明它学到的并不只是 semantic ID 上的特定技巧,而是一种更底层的序列建模能力。
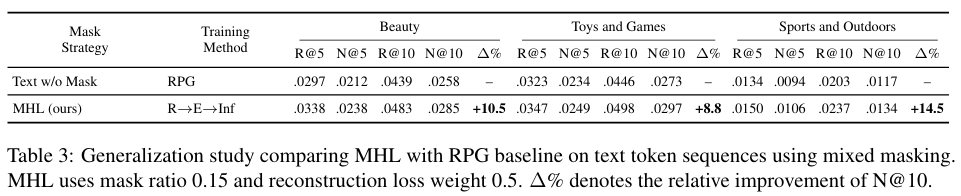
表3 在原始文本 token 序列上的泛化能力
(4)冷启动场景更能体现优势
冷启动分析和案例分析也支持这一点:当 item 本身交互较少,或者用户历史中混入局部噪声时,MHL 更能抓住整条路径背后的核心意图,而不是被表层共现带偏。
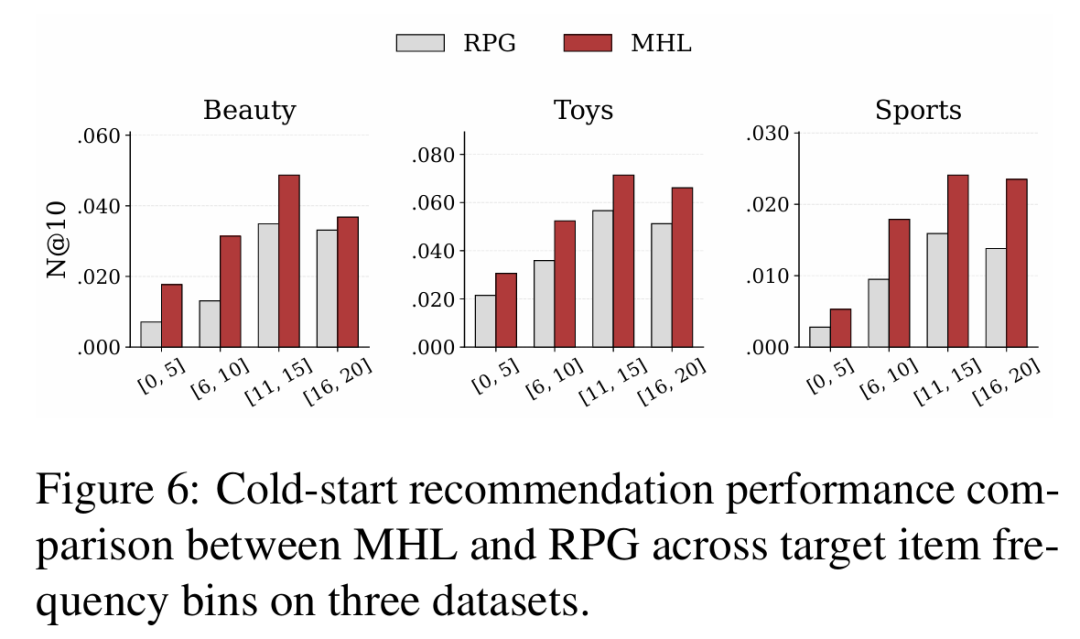
图2 MHL 与 RPG 在冷启动场景下的效果对比
03 总结
如果只把 MHL 看成“在生成式推荐里加一个 mask loss”,其实会低估这项工作的价值。它真正重要的地方在于,研究团队抓住了生成式推荐当前一个很关键却常被忽视的问题:推荐模型不应该只学习局部转移概率,还应该学习用户行为路径本身。
从这个角度看,这项工作的价值不只是“把指标又推高了一点”,更像是在修正生成式推荐的训练方向。未来的方法如果只继续沿着“更长 semantic ID、更强 decoder、更复杂 beam search”往前推,模型可能会越来越会生成,但不一定越来越懂用户。
真正重要的,也许是让模型在训练阶段就被迫回答几个更本质的问题:这段历史里哪些行为是关键的,它们为什么会一起出现,它们共同指向了什么更稳定的用户意图。而 MHL 给出的答案,就是通过有选择地遮住历史,再让模型把它补回来,让“理解过去”真正服务于“预测未来”。

 关注公众号
关注公众号