2026-04-29 11:25:00
2026-04-29 11:25:00
淘宝直播团队投稿
智猩猩AI整理
人物与物体交互(Human-Object Interaction, HOI)视频生成可以形式化为:给定一张人物参考图、一张物体(商品)参考图、一段文本 prompt(可选音频),要求模型合成一段人物与物体进行自然交互的视频。该任务在电商直播、数字广告、虚拟营销等场景具有直接的应用价值——用户无需真实拍摄,即可得到可发布的人-物展示内容。
虽然近期以 DiT 为骨干的视频扩散模型(Sora、Kling 等)已经在外观保真度与运动自然性方面取得显著进步,但当交互进入 手-物近距离接触 时,生成质量仍存在系统性问题。结合研究团队在业务数据上的观察以及若干先验工作(Geometry Forcing、MoGAN 等)的结论,可以将失败模式归结为敏感区域的结构性崩塌和物理接触违规两类。
其根本原因在于:主流方案只在 RGB 像素层面监督,模型只能从外观纹理中反推几何关系,而没有显式获得人体结构与手-物空间关系的先验。
为此,阿里巴巴淘宝直播技术团队联合清华大学提出面向人-物交互视频生成的方法 CoInteract,提出了空间结构化协同生成和人体感知 MoE 两个核心机制来解决人物交互视频生成中的物理不一致问题。相关论文已公开至 Huggingface Daily Paper 并取得了日榜第二,周榜第四的排名。

论文标题:CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
论文链接:https://huggingface.co/papers/2604.19636
项目链接:https://xinxiaozhe12345.github.io/CoInteract_Project/
GitHub:https://github.com/luoxyhappy/CoInteract
01 方法
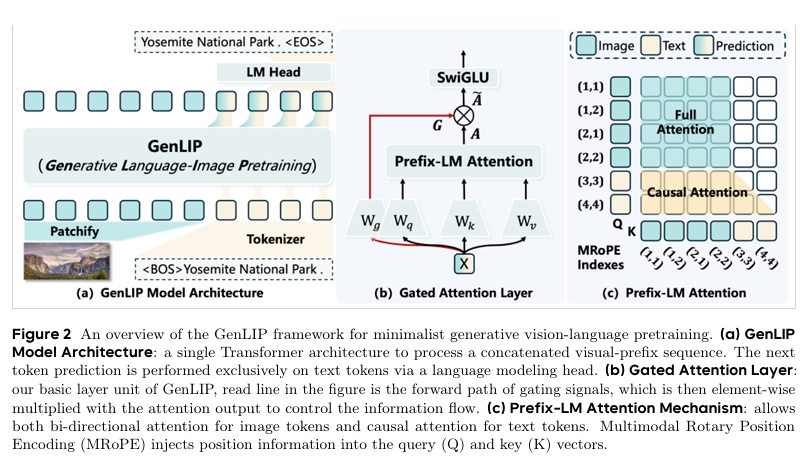
如图 1 所示,CoInteract 以人物参考图、物体参考图、文本 prompt 及可选音频为条件,端到端训练,不依赖任何后处理或修复模型。

图1:CoInteract 概览与生成范式对比
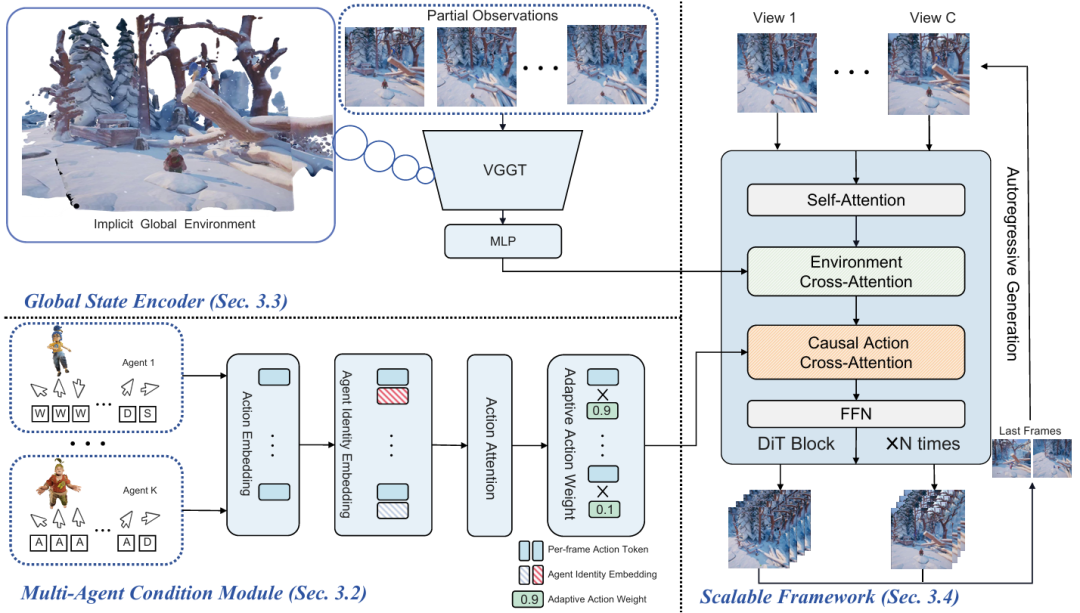
CoInteract 整体架构如图 2 所示,研究团队围绕两个彼此正交的不足提出了两个模块:
针对 "缺乏结构先验",提出双流协同生成(Dual-Stream Co-Generation),在共享 DiT 上并行建模 RGB 流与辅助 HOI 结构流;
针对 "高频区域容量不足",提出人体感知 MoE(Human-Aware MoE),在 FFN 层为手部、面部、基础区域引入区域化专家。
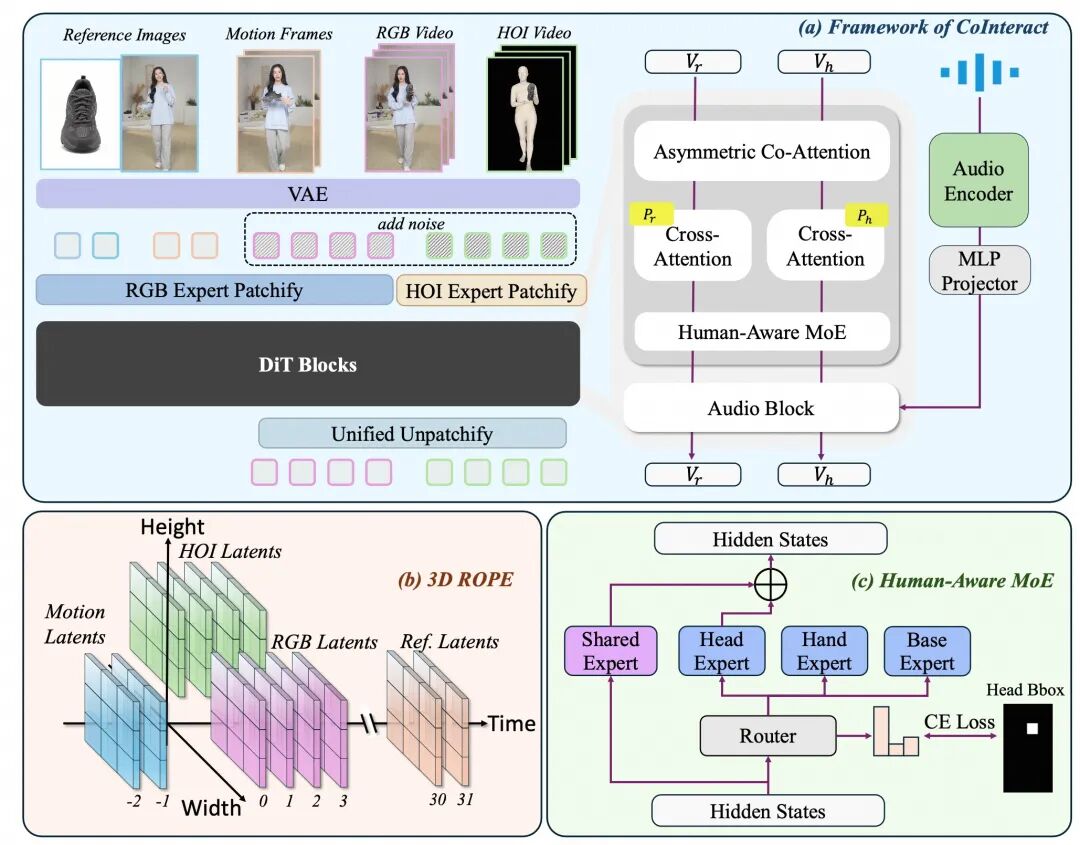
图2:CoInteract 整体框架
1. 双流协同:在 DiT 内部对齐 RGB 与 HOI 结构
研究团队在 RGB 视频流之外并行一条 HOI 结构流,其监督信号由人体姿态骨架、手部关键点、物体分割掩码融合而成,显式反映了交互的空间关系。两条流复用 DiT 主体参数,仅通过 stream-specific 的调制参数加以区分,从而在保持容量的同时共享表征空间。
为了让两条流在同一注意力机制下建立清晰的空间对应,研究团队使用统一的 3D 旋转位置编码(3D RoPE):
空间对齐。两条流沿宽度维度拼接,分别分配非重叠的水平坐标区间(RGB: ,HOI: ),高度与时间索引保持一致。由于 RoPE 以相对位置度量距离,模型可自发学习跨流的像素级对应。
时序因果性。历史运动帧被赋予负时间索引 ,置于当前生成窗口之前,约束生成过程沿时间单向推进。
参考锚定。静态的人物与商品参考图被映射至较远的时间位置,使模型将其视为全局身份锚点,而非邻近帧的短时上下文。
2. 非对称协同注意力:训练用双流,推理"免费"
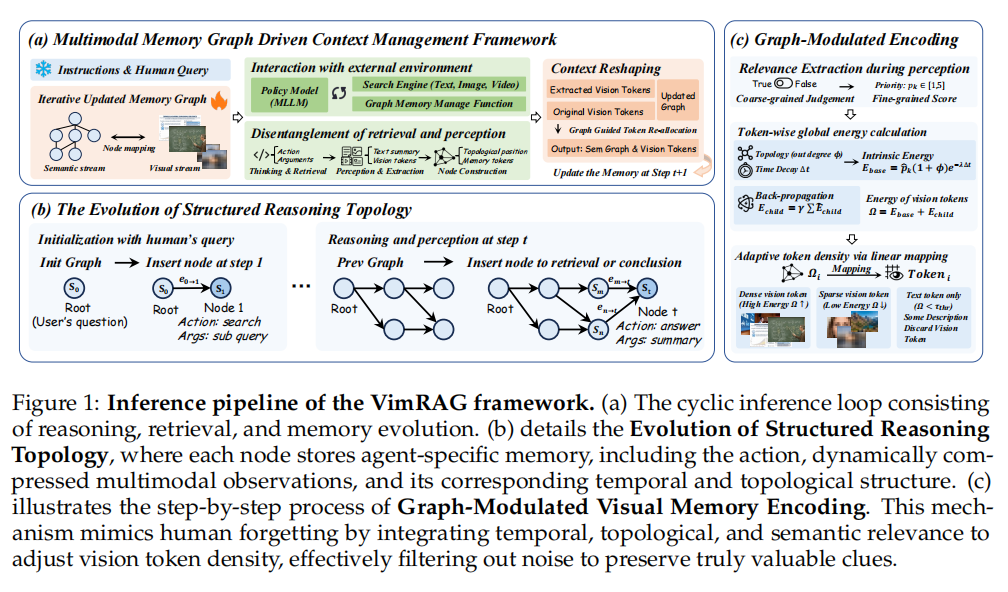
直接在推理时保留 HOI 分支会导致 token 数量翻倍、计算显著膨胀。为使推理阶段仅保留 RGB 流而不损失结构先验,研究团队提出了两阶段的非对称协同注意力(Asymmetric Co-Attention)训练策略,如图 3 所示:
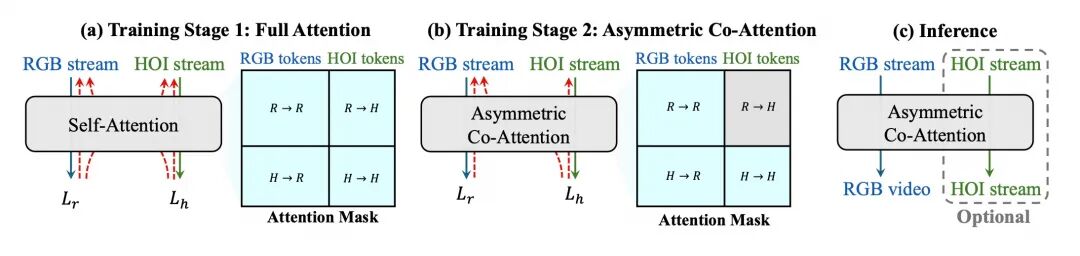
图3 两阶段非对称协同注意力训练策略
全注意力耦合。RGB 与 HOI 两流之间采用标准的双向自注意力,使模型先行学习外观与结构之间的全局耦合。
非对称注意力掩码。 和 分别为 RGB 和 HOI 流的 token 集合,掩码定义为:
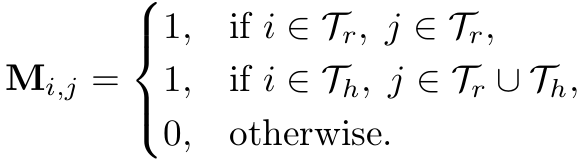
即 RGB query 只能访问 RGB token,HOI query 可以访问两流全部 token。
这一设计在训练与推理之间形成了一个不对称的梯度-计算通路:在前向层面,RGB 流可独立完成计算,HOI 分支在推理时可安全移除;而在反向层面,HOI 流的 flow-matching 损失 仍能经由 HOI ← RGB 的 cross-attention 通路回传至共享的 DiT 参数。
由于这部分参数同样被 RGB 流复用,结构监督信号便以隐式方式沉淀到 RGB 生成器中。推理阶段只需保留 RGB 流,额外开销可忽略。
3. 人体感知 MoE:为结构敏感区域分配区域化容量
结构先验解决了 "知不知道交互该长什么样" 的问题,但手部和面部对高频细节的需求仍对 FFN 容量提出额外挑战。研究团队将 DiT 的 FFN 层替换为由四个专家组成的 MoE 结构:
Shared Expert:沿用原 DiT FFN,承担通用特征处理;
Head Expert:轻量 FFN(hidden dim = 256),专注面部高频细节;
Hand Expert:专注手指关节和握持姿态;
Base Expert:处理躯干与背景区域。
空间监督路由。为避免路由学习对 DiT 主干表征形成干扰,研究团队在 hidden states 进入 router 前施加 stop-gradient:
路由监督来自预先提取的手部与面部 bounding box——即以 token 的空间位置是否落入相应区域作为标签 ,通过交叉熵损失引导 router 完成区域化分派:
整个 MoE 仅使推理成本提升至 1.04×,却在结构敏感区域提供了更具针对性的表征容量。
4. 训练目标
CoInteract 的总体训练损失由三部分组成:
其中
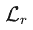 和
和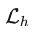 分别是 RGB 流和 HOI 流的 flow-matching 损失,
分别是 RGB 流和 HOI 流的 flow-matching 损失,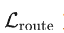 为路由监督项。
为路由监督项。 值为 1。
值为 1。5. HOI 结构数据的自动化构建

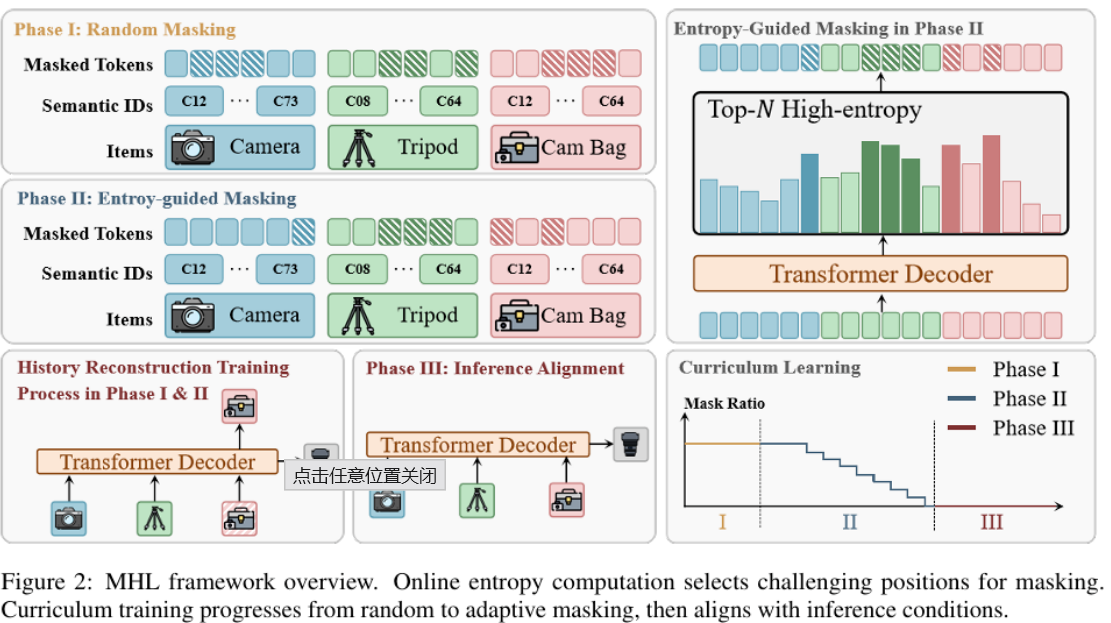
图4:HOI 结构数据自动构建流程
HOI 结构监督的可得性是方法落地的前提。研究团队构建了一条全自动的预处理流水线:
人体姿态与几何提取:采用 DWPose 提取二维全身关键点,SAM3D-body 获取 3D body mesh;
物体分割:先由 Grounding DINO 给出产品边界框,再用 SAM2 得到像素级掩码;
接触合理性过滤:以手部关键点与物体掩码之间的空间距离为依据,剔除接触不合理的样本;
HOI 结构图合成:将骨架、关键点、物体掩码融合渲染为统一的结构表示,作为 HOI 流的训练目标。
02 评估
1. 与现有方法的定量对比
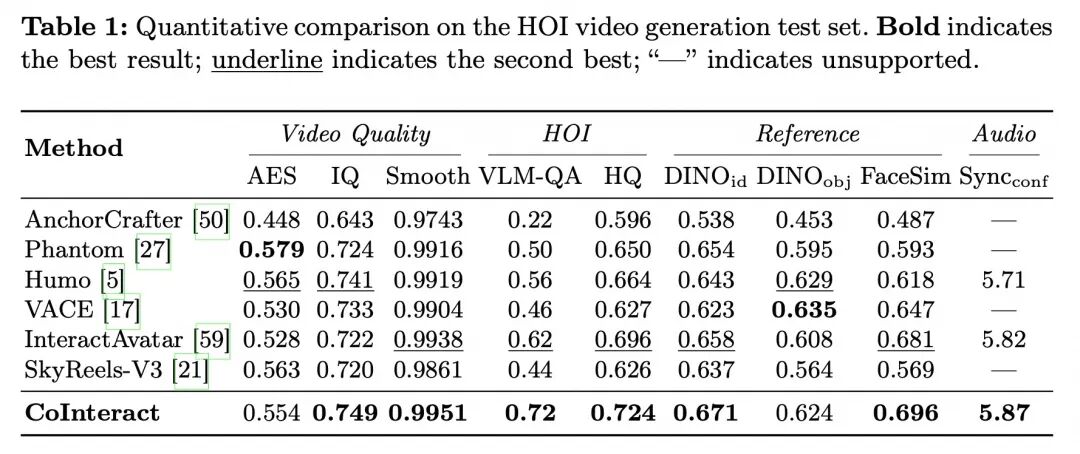
研究团队在同一评测协议下,将 CoInteract 与 InteractAvatar、AnchorCrafter、Phantom、SkyReels、VACE 等代表性方法进行比较,结果见表 1。综合来看,CoInteract 在美学得分(AES)、综合画面质量(HQ)、物体一致性(DINOobj)、面部相似度(FaceSim)、音画同步(Sync)等多数指标上取得最优结果;其中与交互合理性直接相关的 VLM-QA 达到 0.72,较次优方法的 0.54 有明显提升。
2. 与现有方法的定性对比
如图 5 所示,CoInteract 在不同场景中均能持续生成具有连贯手部姿态、自然物体抓取行为以及忠实于提示信息的视频。

图5:与现有方法的定性对比(放大可查看手部细节)
3. 用户研究
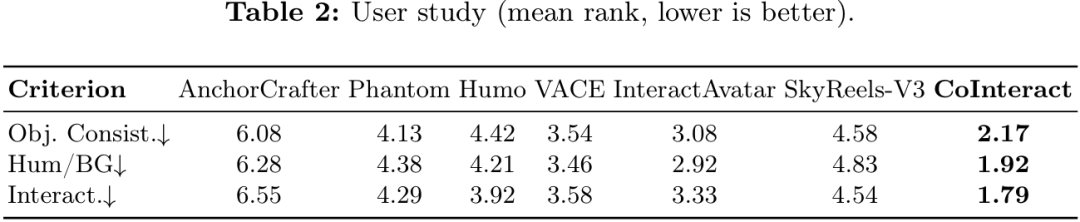
研究团队邀请评估者对 7 种方法进行盲测排名(越低越好),如表 2 所示。CoInteract 在三个维度上均取得最优排名,其中交互合理性的领先幅度较大,与方法的设计目标一致。

 关注公众号
关注公众号