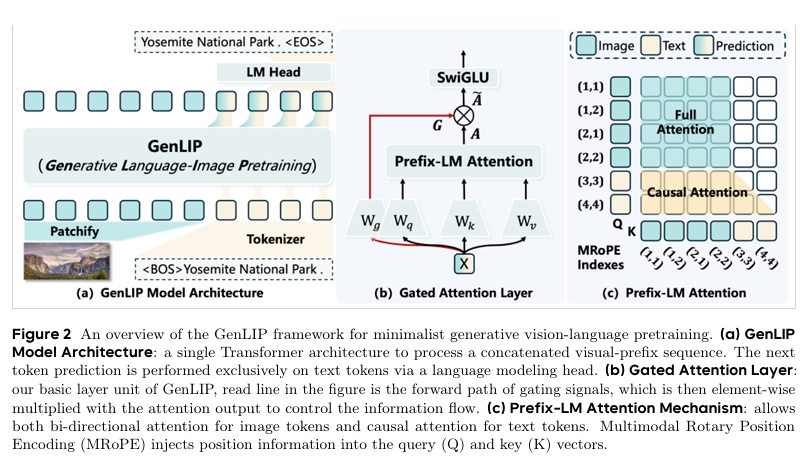
2026-05-05 07:58:00
2026-05-05 07:58:00
智猩猩AI整理
编辑:六六
视频世界模型在模拟环境随用户或智能体动作而变化的动态过程方面已取得显著成功。这类模型通常被设计为动作条件下的视频生成模型,利用历史帧与当前动作来预测未来帧。
然而,现有方法大多局限于单智能体场景,难以捕捉真实世界中多智能体系统所固有的复杂交互行为。
针对这一不足,香港大学 & Sreal AI 联合提出用于可扩展的多智能体多视角视频世界建模的统一框架 MultiWorld。MultiWorld 既能对多个智能体实施精确控制,又能保持不同视角之间视觉内容的一致性。该框架引入多智能体条件模块(MACM)来提升多智能体的可控性,并采用全局状态编码器(GSE)确保跨视角观测的一致表达。
MultiWorld 支持灵活扩展智能体数量与视角数量,并通过并行合成不同视角的视频来实现高效率运行。在多人游戏环境与多机器人操作任务上的实验结果表明,MultiWorld 在视频保真度、动作跟随能力以及多视角一致性方面均优于现有基线方法。

论文标题:MultiWorld: Scalable Multi-Agent Multi-View Video World Models
论文链接:https://arxiv.org/pdf/2604.18564
01 方法
给定初始视角与每帧动作,MultiWorld 可在多人视频游戏及多机器人操作场景中生成动作可控且多视角一致的视频,如图 1 所示。
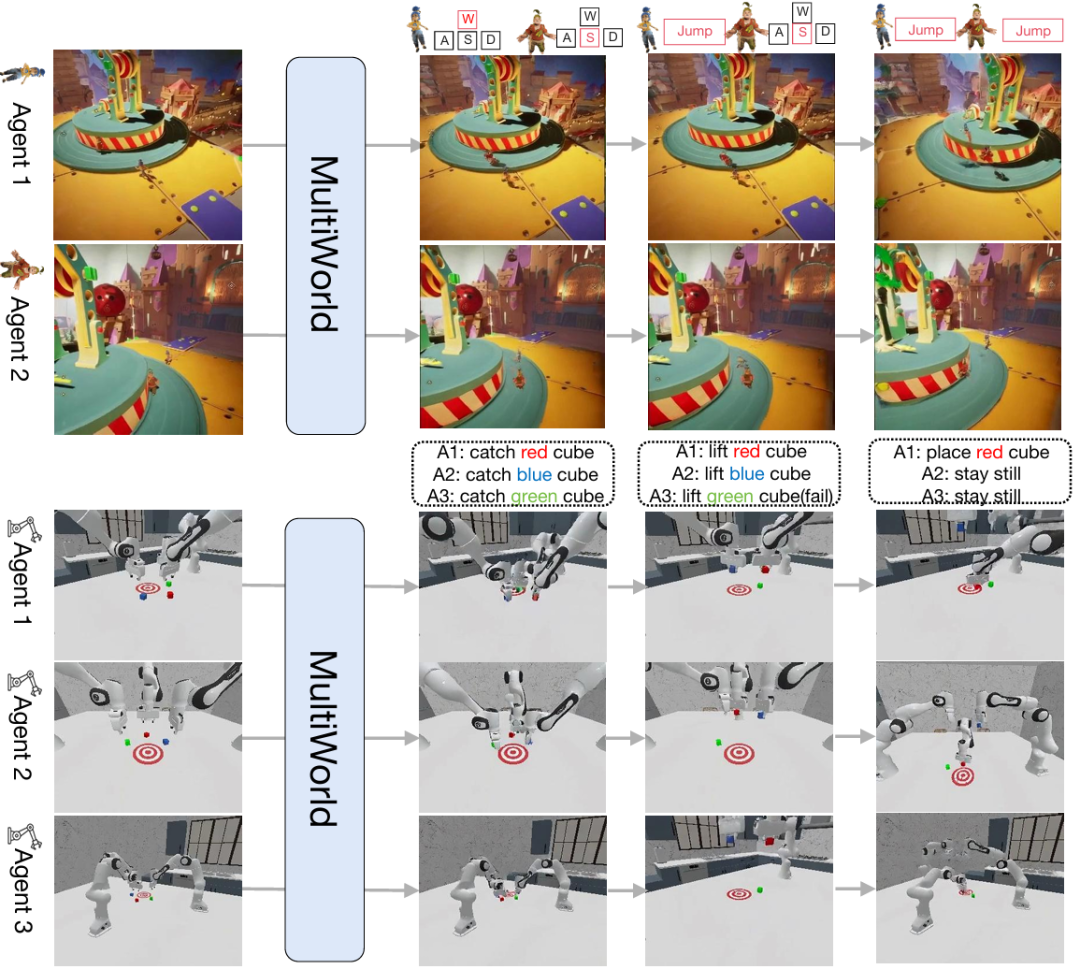
图 1 MultiWorld 生成多智能体、多视角视频。
1. 骨干网络
可以把“多智能体、多视角世界模拟”这个任务拆开来看:总共有 个相机视角,每个视角都需要单独生成一段视频。生成时,每个视角不仅要看自己拍到的画面,还要知道当前所有智能体的动作。
整个问题变成了 个独立的“图像+动作→未来视频”的生成任务。虽然各视角的视频是分开生成的,但它们的背后共享同一个全局环境状态,因此可以并行合成,互不干扰。
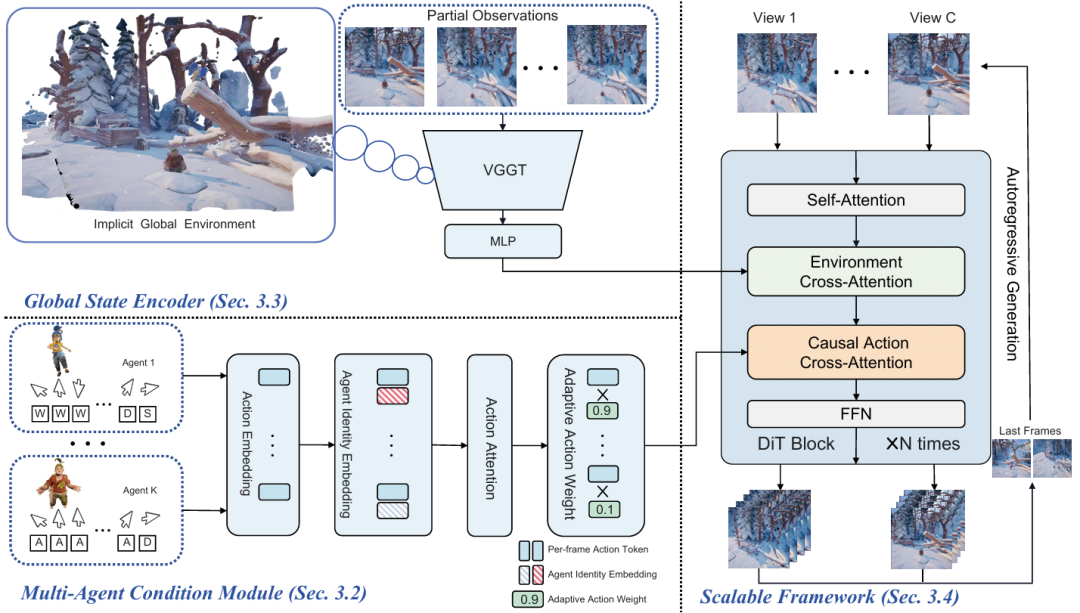
图 2 MultiWorld 的流程图。
模型本身基于流匹配(Flow Matching, FM)搭建,主干网络采用 Transformer 架构。假设系统中有 个智能体和 个相机视角,两者互不绑定,各自独立。
针对每个相机视角 ,利用流匹配来拟合未来视频帧的条件分布。从均匀分布 中采样时间步 ,从标准正态分布 中采样噪声,带噪观测与目标速度分别定义为:
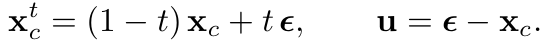
为强制时序因果性,如图2所示,对动作交叉注意力施加逐帧的因果掩码。这确保了第 帧的视频标记仅关注来自第 0 至第 帧的动作,从而避免未来信息泄露,并支持稳定的长时程自回归生成。
2. 多智能体条件模块
智能体身份嵌入(AIE)。为支持可变数量的智能体,采用旋转位置嵌入(Rotary Position Embedding)来计算智能体身份嵌入。
通过在智能体维度上应用 AIE,打破了多智能体动作空间的对称性。随后采用自注意力块来建模智能体间的交互。
自适应动作加权(AAW)。 优先考虑活跃智能体而非静态智能体。该机制通过一个多层感知机(MLP)实现,为每个动作标记预测自适应加权因子。动作标记与其对应的加权因子相乘后求和,形成统一的表征,最后经因果交叉注意力注入 DiT 主干网络。
通过动态缩放每个智能体的动作嵌入,模型能够更有效地聚焦于那些驱动环境变化的动态智能体。
3. 全局状态编码器
为实现视角一致性,视频世界模型需要维护全局环境信息,并基于该信息预测新帧。此外,需要具备三维感知能力的全局环境信息以确保三维一致性。
研究团队采用预训练的端到端的三维重建基础模型 VGGT 作为所提全局状态编码器(Global State Encoder, GSE)的主干网络,用于提取具有三维感知能力的环境状态。
给定多个输入视角,VGGT 生成当前全局环境状态的隐式表征,这些表征可被重建为三维场景,并通过多层感知机(MLP)融合为一个紧凑的全局表征。该设计具有三方面优势:
通过共享的全局表征提升多视角空间一致性;
通过将多视角信息压缩为统一的三维感知全局环境状态,支持任意数量的视角;
通过并行生成支持不同视角的高效预测。
4. 可扩展框架
MultiWorld 框架可扩展至任意数量的智能体与相机视角。
智能体数量扩展通过 AIE 实现。为每个智能体分配相对身份嵌入以表示其关系,该嵌入可外推,故智能体增多时性能基本不降。
相机视角扩展通过 GSE 实现。将多视角模拟拆为多个共享同一全局状态的单视角生成任务,GSE 把各视角观测压缩成该状态,因此输入视角数量不影响模型稳定性。
这种拆解还允许同时生成不同视角视频,推理延迟几乎不随视角数增加。双视角下,并行生成比顺序生成快约 1.5 倍。
此外,通过自回归方式模拟多视角视频块,并定期更新全局环境状态。通过将最新的观测迭代地反馈至全局状态编码器(GSE),全局环境状态得以持续更新。这样即使生成的总时长超过训练上下文长度的两倍,视频质量也只有很小的下降。
5. 数据集
在视频游戏数据集中,以 60 fps 的帧率从游戏 ItTakesTwo 中记录了 500 小时的真实玩家数据。经过预处理,仅保留 100 小时动作清晰且相机运动稳定的片段。该工作最终得到一个大规模多玩家数据集,具有高视觉质量,原始分辨率 2560×1440,包含超过 2100 万帧。
对于机器人数据集,使用 RoboFactory 构建了一个多机器人操作数据集,涵盖涉及 2 至 4 个智能体的多个任务。
02 评估
1. 定量结果分析
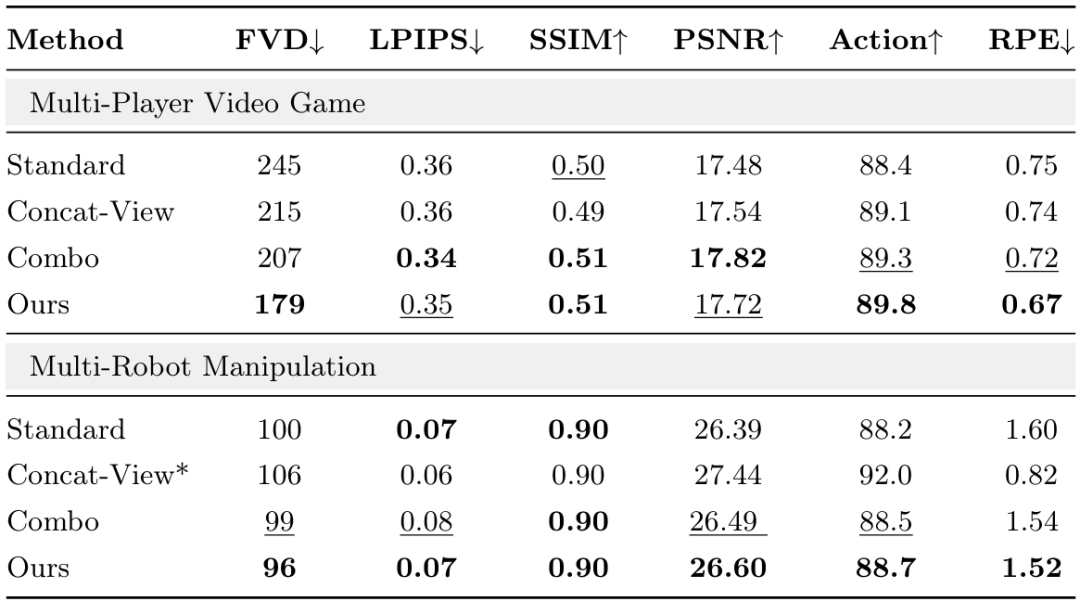
在多玩家视频游戏和多机器人操作数据集上,将所提模型与最先进方法进行比较。评估结果证明了 MultiWorld 框架在视频游戏和机器人操作场景中的有效性与泛化能力。结果报告于表 1 中,性能提升也表明该框架的各个模块能够良好协作并产生更优结果。
表 1 不同多视角条件策略在机器人操作与多玩家视频游戏两个场景上的比较。所提出的 MultiWorld 方法在大多数指标上取得了最佳性能。加粗数值表示最优结果,下划线数值表示次优结果。
2.定性结果分析
图 3 提供了定性比较结果,以说明所提方法的优势。与标准基线模型、Concat-View 以及 COMBO 相比,所提方法实现了更精确的动作跟随能力和更好的多视角一致性。红色方框突出显示了对比方法中的失败案例,包括不准确的动作执行、智能体消失以及多视角不一致。MultiWorld 能够生成遵循给定动作的视频,其最终状态与真实情况几乎一致。

图 3 多玩家视频游戏中多智能体多视角视频生成的定性比较。
多机器人故障轨迹模拟。机器人模拟需要能生成故障轨迹的世界模型。故障轨迹难采集且有损坏机器人的风险,MultiWorld 通过增强轨迹数据来模拟故障。图 4 展示了其在多机器人操作中模拟故障轨迹的能力——既生成合理的成功协作,也捕捉真实的故障模式。

图 4 多机器人故障轨迹模拟。
长时程视频生成。MultiWorld 原生支持自回归长时程生成,在图 5 中,三个机器人按顺序堆叠立方体,流畅无碰撞。生成视频长度可达训练窗口的 2 倍而不降质,4 倍仅轻微损失。

图 5 多机器人操作任务中的长时程视频生成。
综上所述,MultiWorld 能够模拟具有不同属性的多智能体、多视角环境。该模型在生成过程中精确遵循动作控制,模拟智能体与环境之间的交互,同时保持物理一致性与多视角一致性。

 关注公众号
关注公众号