2026-04-24 16:19:00
2026-04-24 16:19:00
智猩猩AI整理
编辑:没方、宁宁
当前大型语言模型(LLM)在超长上下文处理场景中面临核心瓶颈:传统注意力机制的计算复杂度随序列长度呈二次增长,导致百万token级上下文推理时,计算量、KV缓存占用过高,难以兼顾性能与部署效率。 与此同时,长程任务的出现(从复杂的智能体工作流到大规模跨文档分析),使得支持超长上下文成为未来发展的关键。
为此,deepseek团队开发了 DeepSeek-V4 系列,包括拥有1.6T参数(49B激活参数)的 DeepSeek-V4-Pro 预览版和拥有284B参数(13B激活参数)的 DeepSeek-V4-Flash 预览版。通过架构创新,DeepSeek-V4 系列在处理超长序列的计算效率上实现了巨大飞跃。DeepSeek-V4发布同时,也公布了相应的技术报告。


论文标题:DeepSeek-V4:Towards Highly Efffcient Million-Token Context Intelligence
论文链接:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
01 架构与基础设施优化
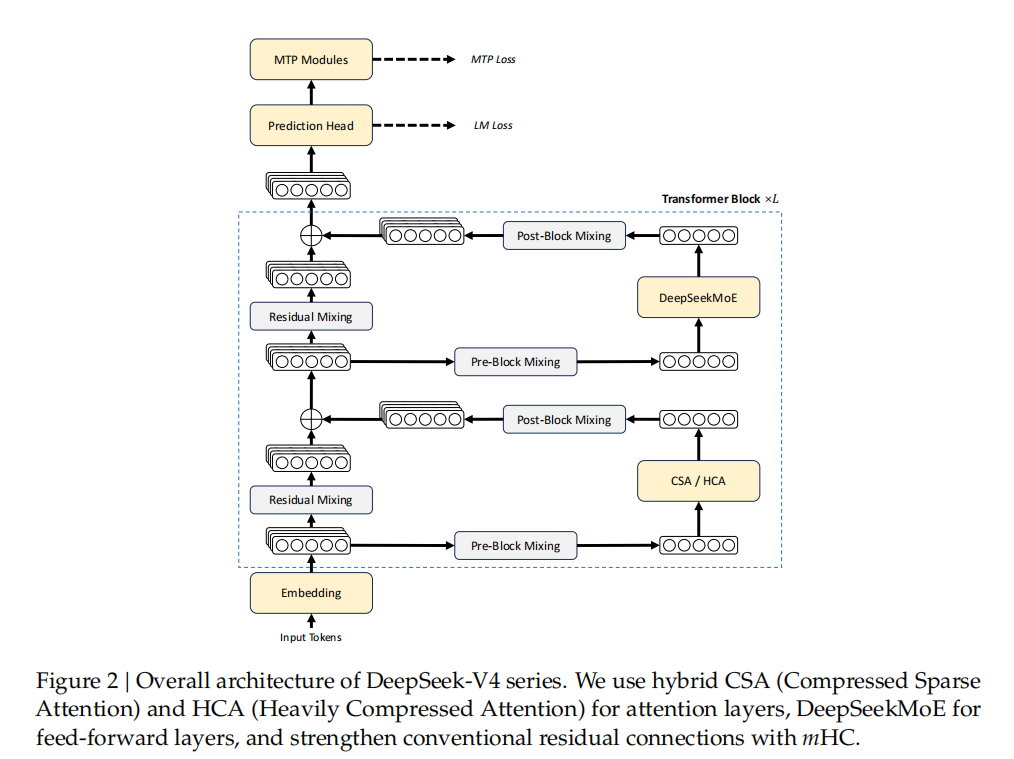
DeepSeek-V4 整体架构图
与 DeepSeek-V3 架构相比,DeepSeek-V4 系列保留了 DeepSeekMoE 框架和MTP(Multi-Token Prediction)策略,同时在架构方面引入了几项关键创新:
为了增强长上下文效率,研究团队设计了一种结合压缩稀疏注意力(CSA)和重度压缩注意力(HCA)的混合注意力机制。
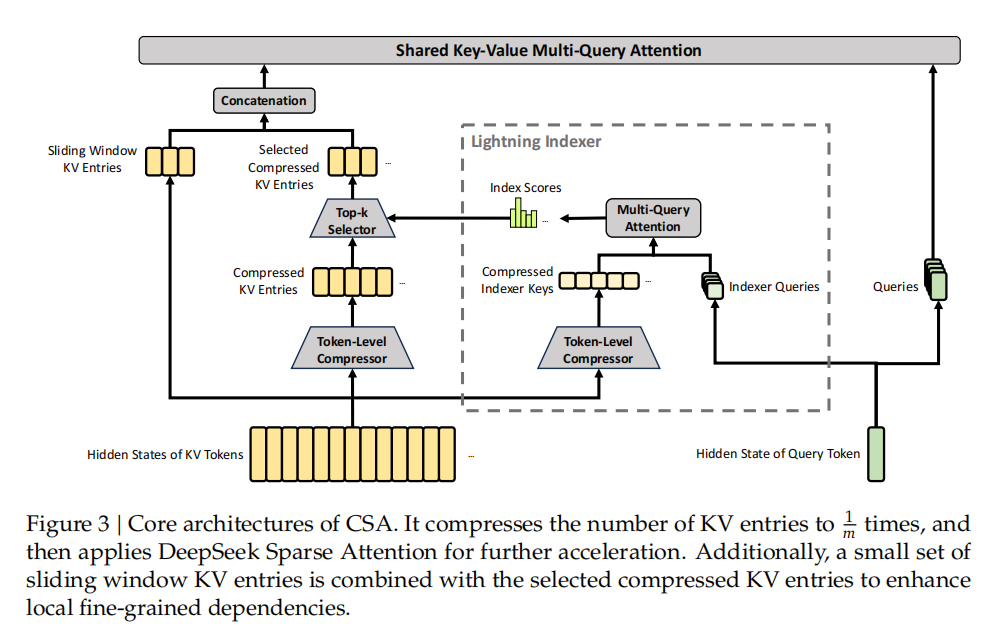
CSA混合注意力机制图
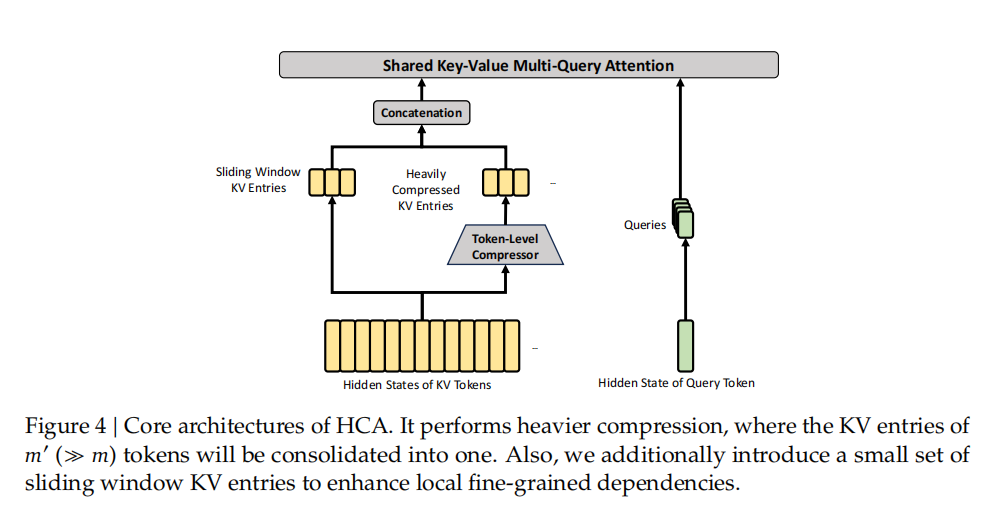
HCA 混合注意力机制图
CSA 沿序列维度压缩 KV 缓存,然后执行 DeepSeek 稀疏注意力(DSA);而 HCA 对 KV 缓存应用更激进的压缩,但保留稠密注意力。
为了增强建模能力,研究团队引入流形约束超连接(mHC)来升级传统的残差连接。此外,研究团队将 Muon 优化器引入 DeepSeek-V4 系列的训练中,从而实现了更快的收敛速度以及更好的训练稳定性。
为了实现 DeepSeek-V4 系列的高效训练和推理,以及提升开发效率,研究团队引入了多项基础设施优化:
细粒度专家并行(EP)
为解决MoE模型通过专家并行(EP)加速时,存在节点间通信复杂、对带宽和延迟性能要求高的问题,研究团队提出细粒度EP方案,将通信与计算融合到单个流水线内核(single pipelined kernel),以实现通信-计算重叠。

MoE 专家并行中的通信-计算重叠机制
研究团队已在英伟达 GPU 与华为昇腾 NPU 两大硬件平台上,对细粒度 EP 并行方案完成验证。相较于优质非融合基线方案,该方案在通用推理任务中可实现1.50~1.73 倍加速;在低延迟敏感场景下(RL rollouts 和高并发智能体服务),加速比最高可达1.96 倍。
引入 TileLang
采用领域特定语言 TileLang,兼顾开发效率与运行时性能。
确定性算子库
提供高效的批次不变(batch-invariant)和确定性算子库(kernel libraries),以确保训练和推理之间的逐位可复现性(bitwise reproducibility)。
FP4 量化训练
对 MoE 专家权重和索引器 QK 路径采用了 FP4 量化感知训练,以减少内存占用和计算量。
训练框架升级
对于训练框架,研究团队扩展了自动微分框架(autograd framework),增加了张量级检查点以进行细粒度的重计算控制。
同时,通过三项技术提升训练效率:对 Muon 优化器采用了混合 ZeRO 策略;利用重计算和融合算子实现了高性价比的 mHC计算;并采用两阶段上下文并行机制来管理压缩注意力。
异构缓存设计
对于推理框架,研究团队设计了一种带有磁盘存储策略的异构 KV 缓存结构,以实现高效的共享前缀重用。
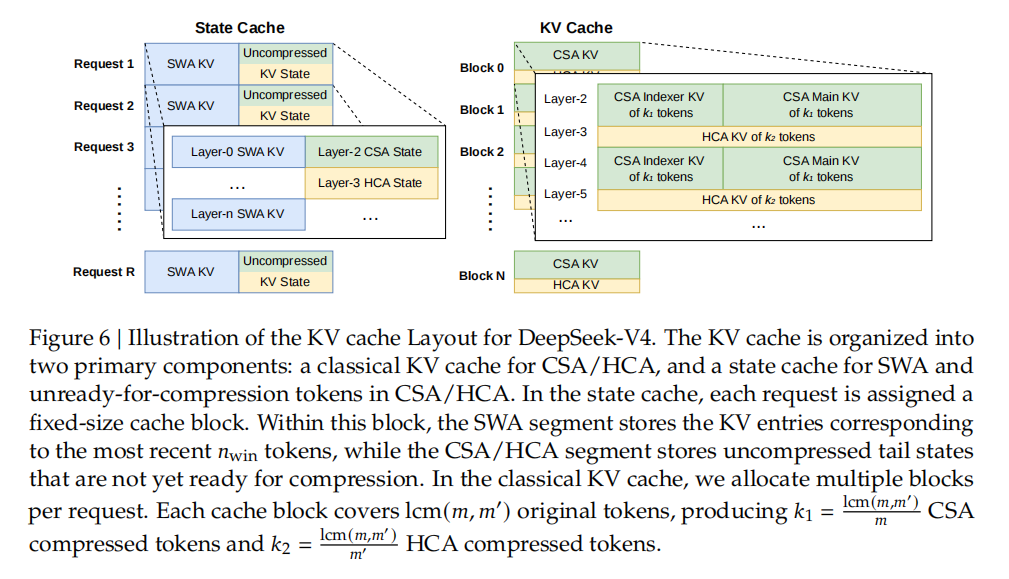
DeepSeek-V4 异构 KV Cache 布局
02 预训练与后训练流程
在完成架构与基础设施设计后,DeepSeek-V4 系列进一步通过大规模预训练与系统化后训练,大幅度增强模型能力。
预训练方面,DeepSeek-V4 首先在 DeepSeek-V3 数据基础上进一步扩充和筛选语料,重点提升数据多样性、质量以及长文档覆盖范围。数据来源覆盖网页、数学、代码、多语言内容,以及科学论文、技术报告等长文档材料,总规模超过 32T tokens。
训练设置上,DeepSeek-V4-Flash 训练 32T tokens,DeepSeek-V4-Pro 训练 33T tokens;序列长度从 4K 逐步扩展到 16K、64K,最终扩展到 1M,使模型在预训练后即可原生、高效地支持百万 token 上下文。
针对超大 MoE 模型训练中的稳定性问题,研究团队还采用了两类关键策略。
(i)预期路由(Anticipatory Routing),通过历史参数提前计算并缓存后续训练步骤所需的路由索引,缓解路由网络与主干网络同步更新可能带来的不稳定,从而降低 loss spike 风险。
(ii)SwiGLU Clamping,通过限制 SwiGLU 中线性分支和门控分支的数值范围,抑制 MoE 层中的异常值,进一步提升训练稳定性。
后训练方面,虽然训练流程在很大程度上沿用了 DeepSeek-V3.2 的模式,但研究团队做了一个关键的方法替换:完全用在线策略蒸馏(On-Policy Distillation,OPD)取代了混合强化学习阶段。
(1) 专家模型训练
每个专家模型先依次经过初始微调阶段,随后使用领域特定提示和奖励信号进行强化学习(RL)优化。 RL 阶段采用GRPO算法,超参数设置沿用之前的研究。在奖励模型设计上,DeepSeek-V4 对易验证任务采用规则验证器或测试用例;对难验证任务,则引入生成式奖励模型(GRM)评估策略轨迹,让 actor 网络同时具备生成与评价能力,以较少人工标注完成复杂任务的奖励建模。
研究团队在不同的强化学习(RL)配置下训练了多个专家模型,以开发出能够适应不同推理能力需求的模型。如表 2 所示,DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 均支持三种特定的推理努力模式。

对于每种模式,研究团队在 RL 训练过程中施加不同的长度惩罚和上下文窗口,这会导致推理过程中的输出 token 长度各不相同。为了整合这些不同的推理模式,研究团队采用了由 <think> 和 </think> 标记分隔的专用响应格式。此外,对于“Think Max”模式,研究团队在系统提示的开头添加了一条特定指令,以引导模型的推理过程,具体如表 3 所示。

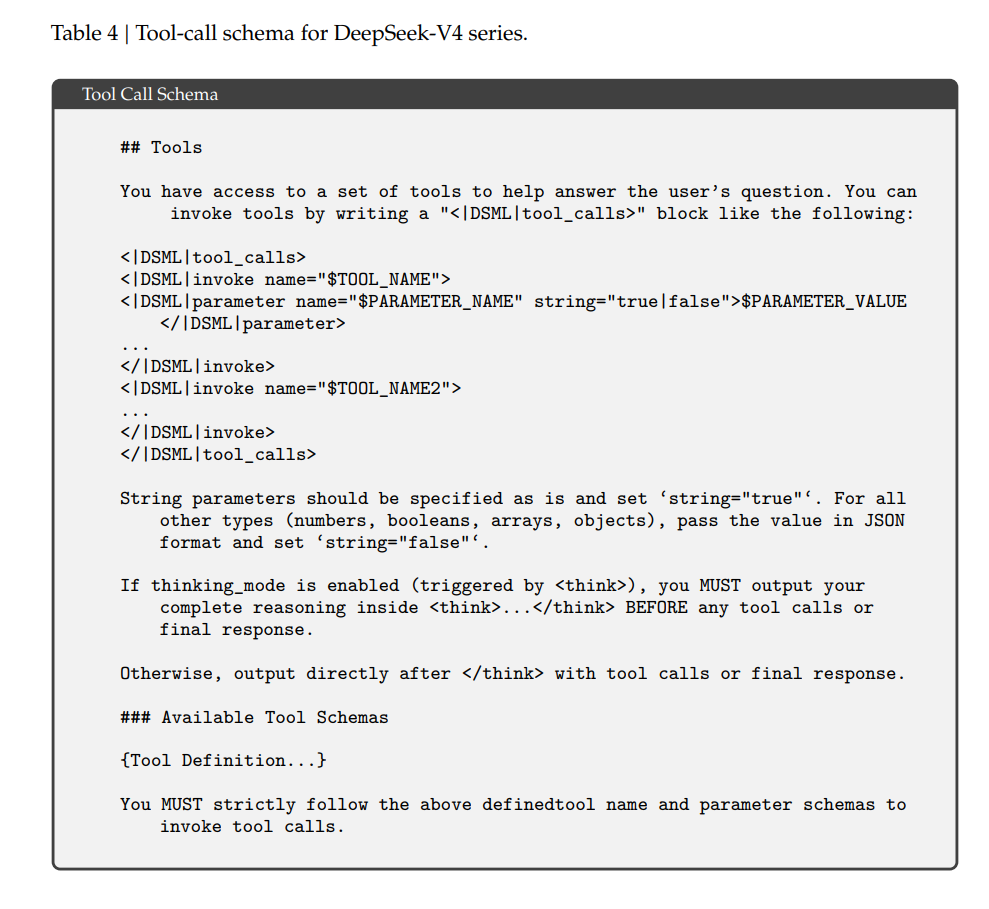
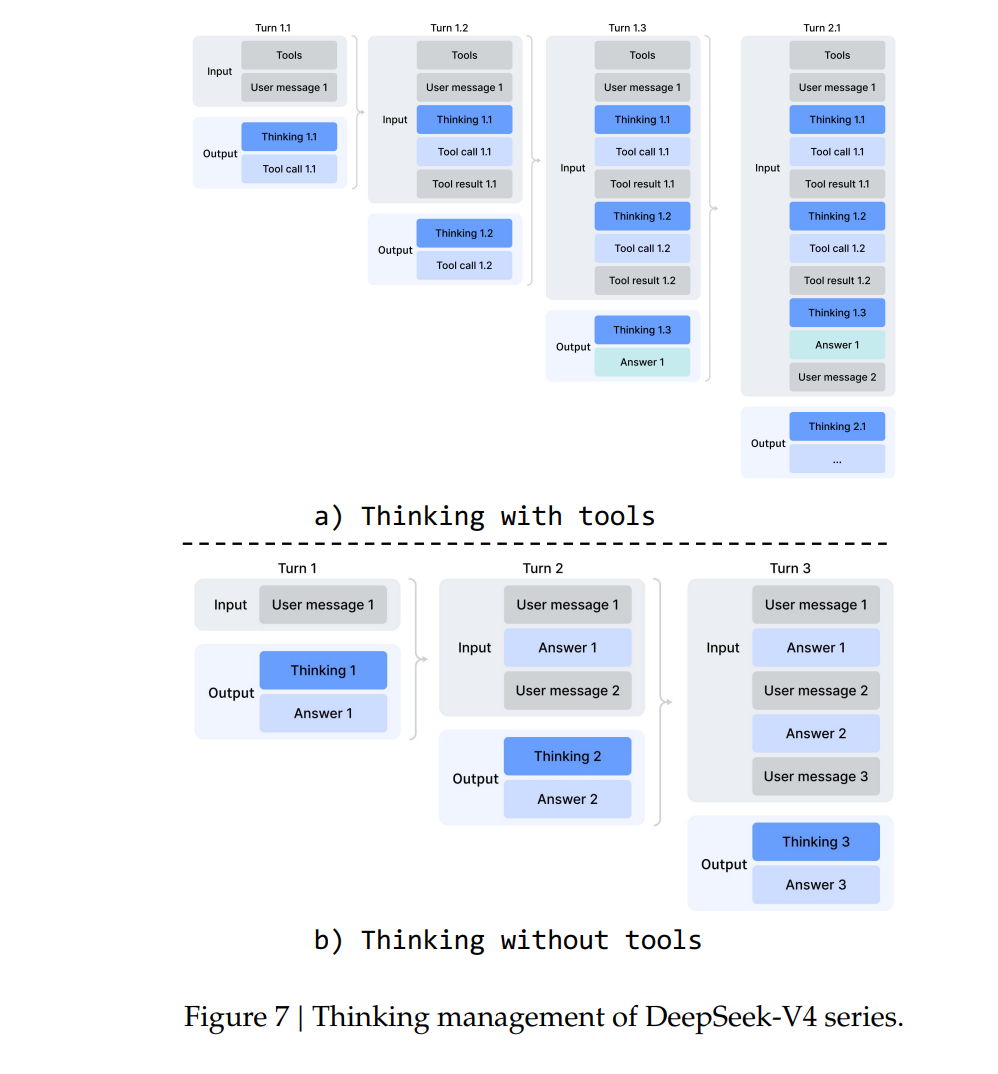
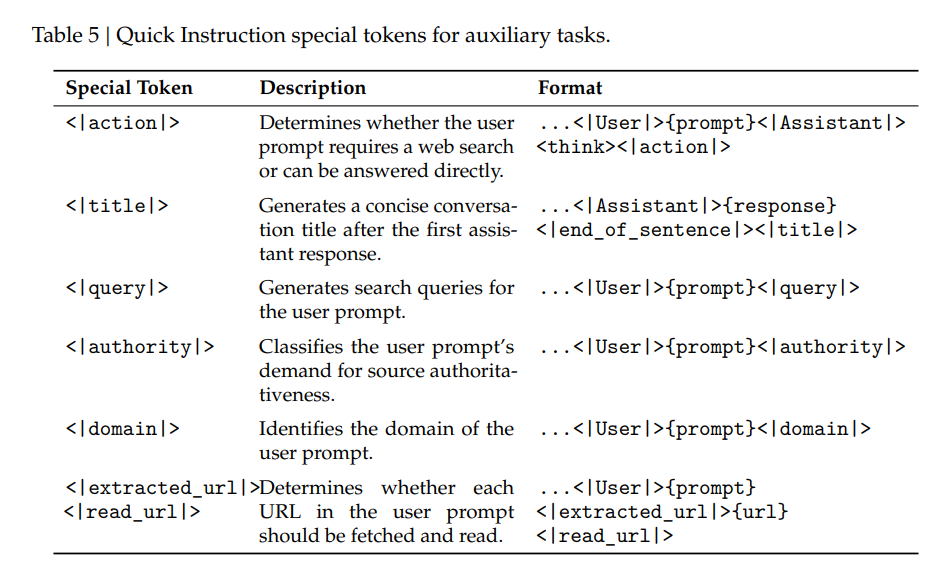
此外,研究团队还为DeepSeek-V4系列设计了新的工具调用模式(表4)、思考管理机制(图7)和快速指令(表5),用于降低检索、意图识别等辅助任务的延迟。
(2)On-Policy Distillation(OPD)
在通过专门的微调和强化学习训练了多个特定领域的专家模型之后,研究团队采用多教师在线策略蒸馏(multi-teacher On-Policy Distillation)将专家能力融合到最终模型。
在线策略蒸馏已成为一种高效的后训练范式,能够有效地将领域专家的知识和能力转移到统一模型中。这是通过让学生模型在其自身生成的轨迹上,学习教师模型的输出分布来实现的。
03 评估
实验部分主要围绕四类问题展开:基础模型是否更强,后训练模型是否具备开放模型领先水平,百万 token 长上下文是否真正有效,以及模型在真实任务中是否具备实用价值。
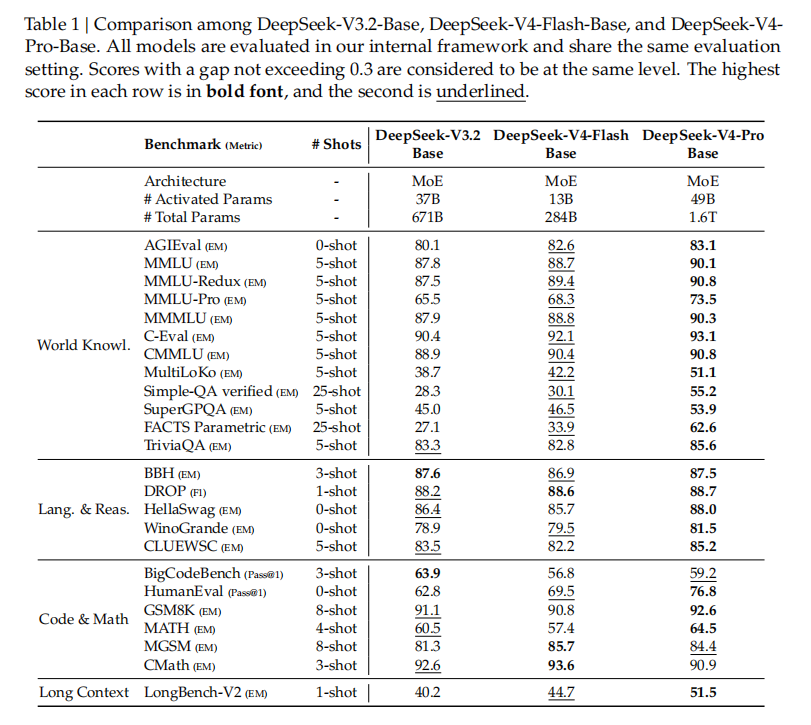
基础模型评测如表1所示,研究团队比较了 DeepSeek-V3.2-Base、DeepSeek-V4-Flash-Base 和 DeepSeek-V4-Pro-Base。
DeepSeek-V4-Flash 在参数和激活规模更小的情况下,已经在多数 benchmark 上超过 V3.2-Base;DeepSeek-V4-Pro-Base 则进一步提升,在推理、代码、长上下文和世界知识任务上形成更全面优势。
此外,V4-Flash 预训练 32T tokens,V4-Pro 预训练 33T tokens,二者预训练后即可原生支持 1M 长度上下文。
DeepSeek-V4 Base 模型能力对比
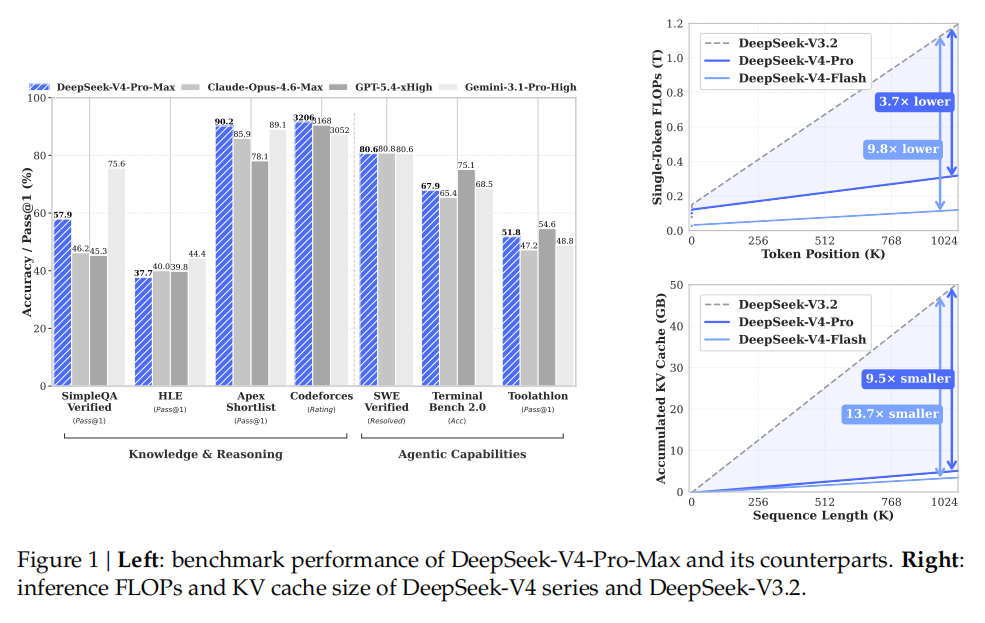
在标准 benchmark 上(图1所示),DeepSeek-V4-Pro-Max 是研究团队重点展示的版本。它在知识、推理、代码和 Agent 能力上相比此前开放模型有明显提升。
尤其在 SimpleQA、Chinese-SimpleQA 等知识评测中,V4-Pro-Max 超过领先开源模型;在推理任务中,通过增加 reasoning tokens,它相对 GPT-5.2 和 Gemini-3.0-Pro 表现更强,但与 GPT-5.4、Gemini-3.1-Pro 等最前沿闭源模型仍存在一定差距。
可以看出,DeepSeek-V4-Pro-Max 已经显著缩小与顶级闭源模型的距离。
DeepSeek-V4-Pro-Max 综合 benchmark 与长上下文效率对比
长上下文能力是本文最核心的实验方向。图 1 右侧展示了 DeepSeek-V3.2 和 DeepSeek-V4 系列的预估单 token 推理 FLOPs 和累积 KV cache大小。在 1M token 上下文的场景中,即使是激活参数数量更多的 DeepSeek-V4-Pro,其单 token FLOPs(以等效 FP8 FLOPs 衡量)仅为 DeepSeek-V3.2 的 27%,KV cache大小仅为 10%。
而激活参数量更少的 DeepSeek-V4-Flash 进一步拉满效率:在 1M token 上下文设置下,其单 token FLOPs 仅为 DeepSeek-V3.2 的 10%,KV cache大小仅为 7%。
另外,对于 DeepSeek-V4 系列,路由专家参数采用了 FP4 精度。虽然目前硬件上 FP4 × FP8 运算的峰值 FLOPs 与 FP8 × FP8 相同,但在未来的硬件上,理论上可以实现 1/3 的效率提升,这将持续释放 DeepSeek-V4 系列的性能潜力。
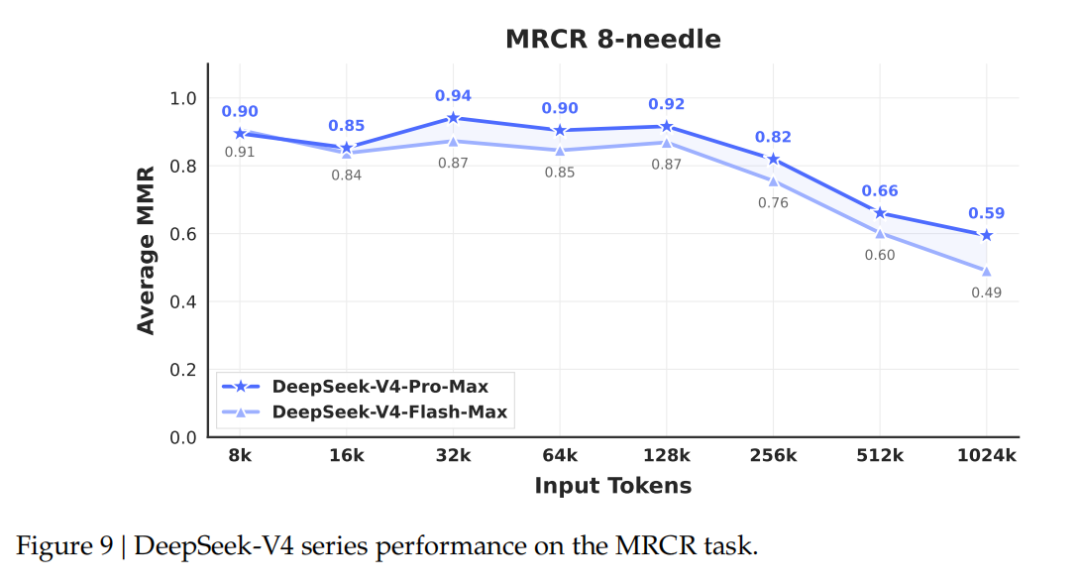
DeepSeek-V4 系列在 MRCR 长上下文任务上的表现
在真实任务上,研究团队进一步测试了中文写作、搜索、白领任务和代码 Agent。在搜索任务中,DeepSeek-V4-Pro 的 agentic search 相比传统 RAG 更具优势;研究结果显示,在总计 869 个搜索问答样本上,Agentic Search 胜率为 61.7%,RAG 胜率为 18.3%,平局为 20.0%。在复杂信息获取任务中,模型主动规划、调用工具和多步检索的能力,比一次性检索增强更适合处理复杂问题。
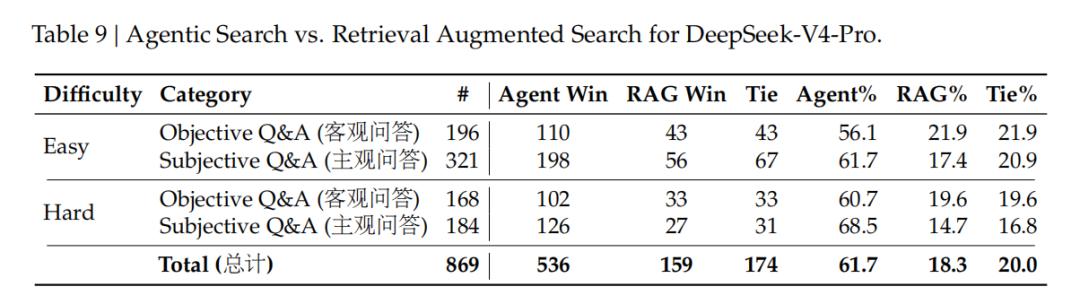
Agentic Search 与传统 RAG 的搜索问答对比
代码 Agent 方面,研究团队收集约 200 个内部研发任务,经过过滤后保留 30 个高质量任务作为评测集,覆盖功能开发、Bug 修复、重构和诊断等场景。结果显示DeepSeek-V4-Pro-Max 在 R&D Coding Benchmark 上达到 67% Pass Rate,高于 Claude Sonnet 4.5 的 47%,接近 Claude Opus 4.5 的 70%。这说明 DeepSeek-V4 不只是长上下文模型,也具备较强的工程任务执行能力。

DeepSeek-V4-Pro-Max 在内部研发代码任务上的表现
04 总结
为极致提升长上下文处理效率,DeepSeek‑V4 系列采用了突破性的架构设计。为控制研发风险,团队沿用了大量经过前期验证的成熟模块与优化技巧;这类方案虽效果可靠,却也导致整体架构相对复杂。在后续版本迭代中,研究团队将开展更系统、严谨的研究,提炼核心设计、精简架构,在不损失模型性能的前提下,让整体架构更加简洁规整。
与此同时,虽然 Anticipatory Routing 和 SwiGLU Clamping 已被证明能够有效缓解训练不稳定性,但其背后的原理仍未被充分理解。研究团队将积极研究训练稳定性的基础问题,并加强内部指标监控,目标是采用更加原则性和可预测的方法来实现大规模稳定训练。
除MoE与稀疏注意力架构外,研究团队还将积极探索全新维度的模型稀疏化方向(例如稀疏度更高的嵌入模块),在不削弱模型能力的前提下,进一步提升计算与内存使用效率。研究团队也会持续研究低延迟架构与底层系统优化技术,优化长上下文部署与交互响应速度。
研究团队充分认可长周期、多轮智能体任务的价值与落地意义,并将持续深耕该方向迭代优化。研究团队也在努力将多模态能力整合到模型中。
最后,研究团队将持续优化数据筛选与数据合成方案,稳步提升模型的综合智能水平、鲁棒性与通用落地能力,以适配日趋多元的业务场景与任务需求。

 关注公众号
关注公众号