2026-04-11 10:06:00
2026-04-11 10:06:00
智猩猩AI整理
编辑:六六
近期,HunyuanImage 3.0、Qwen Image 及 Seedream 系列等大规模扩散模型在文生图与图文编辑领域大放异彩,但其动辄数十亿的参数和迭代去噪过程,使其难以在普通设备上高效运行。
为突破这一瓶颈,业界开始探索适合移动端的轻量化扩散模型。然而,现有方案大多仅支持生成,缺乏编辑能力。
字节跳动团队提出 DreamLite——一个参数量仅 0.39B 的统一紧凑扩散模型,在单个网络中同时支持图像生成与编辑。同时,DreamLite是首个面向移动部署、实现“生成+编辑”一体化的端侧模型。

论文标题:DreamLite: A Lightweight On-Device Unified Model for Image Generation and Editing
论文链接:https://arxiv.org/pdf/2603.28713
项目主页:https://carlofkl.github.io/dreamlite/
01 方法
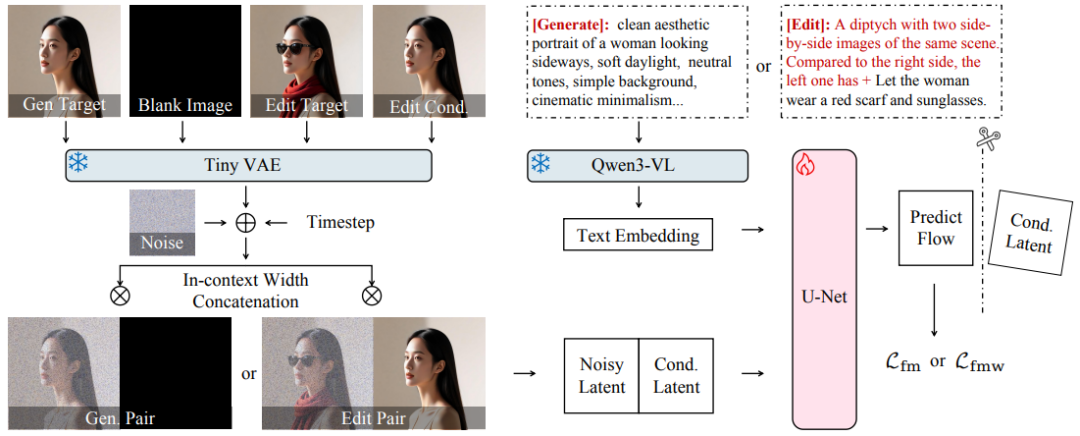
图 1 DreamLite 架构概述。
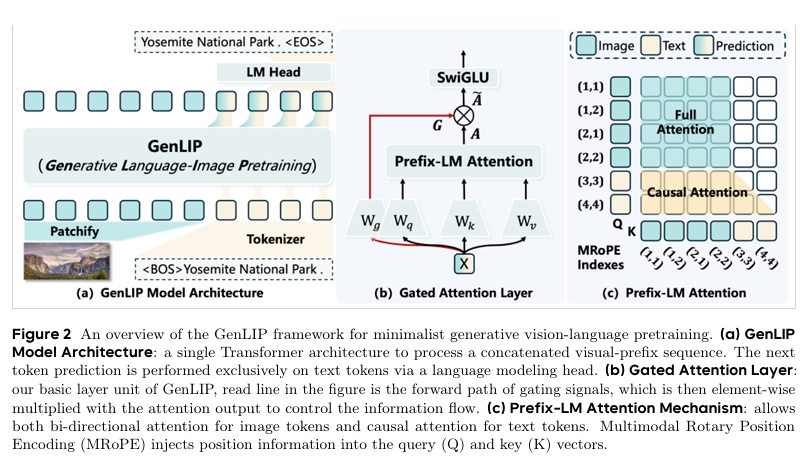
如图 1 所示,DreamLite 架构包含三个主要模块:U-Net 骨干网络、变分自编码器(VAE)和文本编码器。为支持统一的图像生成与编辑功能,进一步引入了上下文条件机制。
1. 变分自编码器
采用潜在扩散框架,并选用极轻量级的 TinyVAE 实现端侧高效部署。该 VAE 仅含 2.5M 参数,通过 8 倍下采样将图像编码为 4 通道潜表示,以支持高效训练与推理。
2. 紧凑型 U-Net
以效率为首要设计目标,基于 SnapGen 的移动高效 T2I 架构,对 U-Net 骨干网络进行浅层化与窄化处理:Transformer 块数量大幅缩减,通道维度相应降低,潜在样本分辨率设为 128×128。此外,采用以下关键优化措施:
移除高分辨率阶段的自注意力层,以降低复杂度;
采用扩展可分离卷积(深度卷积与逐点卷积)替代标准卷积;
在前馈网络中设置合理的隐藏通道扩展比;
使用单 KV 头的多查询注意力,减少计算与内存开销;
进行阶段对齐,并添加 QK-RMSNorm 与轻量文本投影器。
如图 2 所示,上述的逐步优化成功将 2.5B 参数的基线模型压缩为 389M 参数的高效骨干网络,显著降低了 FLOPs,同时保持了生成性能。
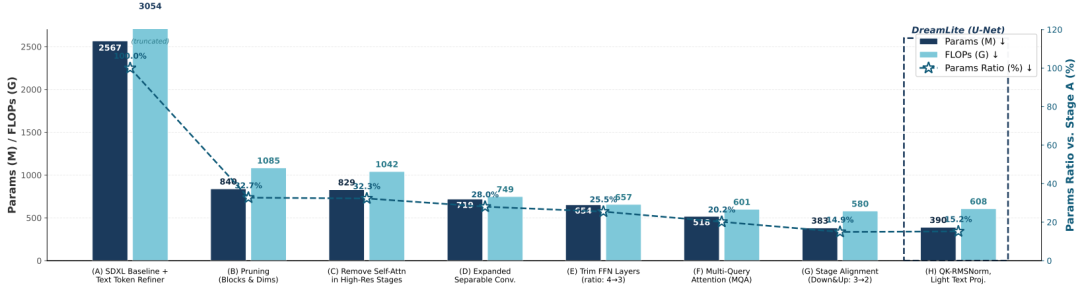
图 2 DreamLite 的架构演进过程。计算 U-Net 的参数数量与 GFLOPs。
3. 文本编码器
采用 Qwen3-VL-2B,凭借其强大的视觉语言理解能力,准确解析复杂用户指令并处理多模态输入,从而实现输入指令与生成内容间的精确语义对齐。
4. 上下文范式
研究团队提出将 U-Net 扩展为上下文条件框架,在输入层面统一图像生成与编辑任务。
如图 1 所示,将目标图像与条件图像的潜变量沿空间维度水平拼接,构建双面板输入,其中左侧为目标输出,右侧为视觉条件。拼接后的潜变量直接送入 U-Net。
对于生成任务,条件面板设为空白(全黑图像),表示无视觉条件;对于编辑任务,则使用源图像作为条件。这样的设计使模型无需额外模块即可从生成扩展至编辑,天然适配统一框架。
02 预训练阶段
为确保稳定收敛,研究团队提出任务渐进式联合预训练方案:在 T2I 预训练与联合训练之间引入编辑预训练阶段,以对齐视觉条件与生成潜空间,减轻任务干扰。
1. T2I 预训练
采用流匹配目标训练 DreamLite 作为标准 T2I 扩散模型。训练采用渐进分辨率策略,从低分辨率逐步提升至高分辨率,并结合多尺度训练、特定噪声采样及动态时间偏移,为后续阶段建立强生成先验。
2. 编辑预训练
T2I 预训练后,激活上下文条件机制,在配对编辑数据上继续训练,以使视觉条件与生成潜空间对齐,实现基于条件图像与编辑指令的生成。
此阶段同样采用流匹配损失。针对编辑区域通常较小、易被背景梯度淹没的问题,参照 UniWorld-V1,引入前景强调掩码对损失进行重加权。
3.统一预训练
在 T2I 与编辑数据的混合数据上进行统一联合训练,以整合生成先验与指令跟随能力,使单一参数集同时支持两种任务。
为减少任务冲突,在文本提示前添加 [Generate] 和 [Edit] 作为轻量路由信号,引导模型动态切换行为。由此,DreamLite 在无需额外参数的前提下实现了统一架构下的鲁棒生成与编辑。
03 后训练阶段
任务渐进式联合预训练为生成与编辑任务建立了坚实基础,但数据高方差导致模型行为不稳定。为此,采用监督微调(SFT)与强化学习(RL)两阶段后训练策略。
监督微调:SFT 的主要目标是通过将模型暴露于精心整理的高质量数据分布来精炼其行为。利用约 0.5M 高质量样本进行微调,以提升模型的真实感与指令遵循能力。
强化学习:为进一步使 DreamLite 与人类偏好对齐,采用基于人类反馈的强化学习(RLHF)。针对生成与编辑任务分别使用 HPSv3 与 EditReward 奖励模型,持续提升感知质量与指令遵循能力,使紧凑模型超越先前移动扩散基线。
少步蒸馏:后训练虽保证高质量,但需数十步去噪,难以满足实时移动应用需求。为此,采用分布匹配蒸馏(DMD)将采样压缩至 4 步,且不损失视觉质量。
04 评估
1. 定量结果
图像生成性能:所有图像均在 1024×1024 分辨率下生成以保证公平比较。表 1 和表 2 详细列出了参数数量、各分项得分以及 GenEval 和 DPG 基准上的整体性能。需要注意的是,SnapGen 系列由于未开源,省略了各分项得分。尽管如此,DreamLite(0.39B)取得了具有竞争力的性能,可与参数规模近 10 倍的模型相媲美。
表 1 GenEval 基准上的评估结果。
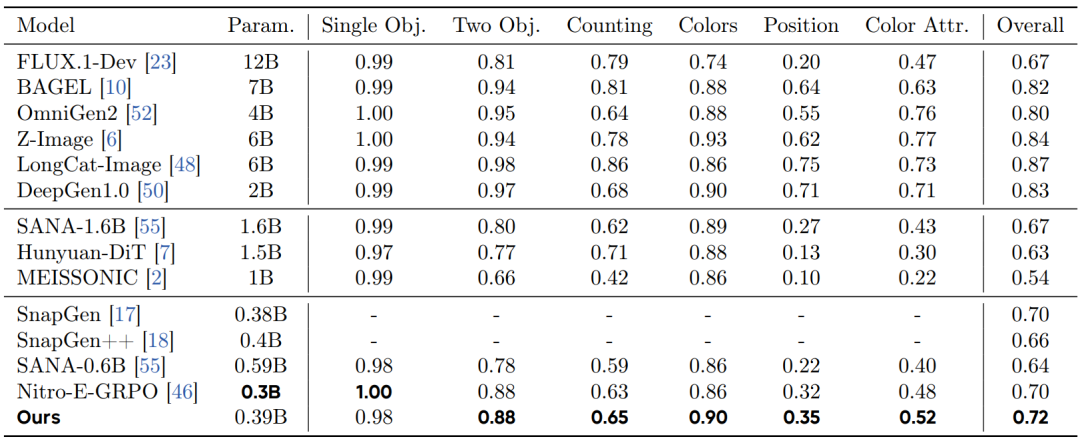
表 2 DPG 基准上的评估结果。
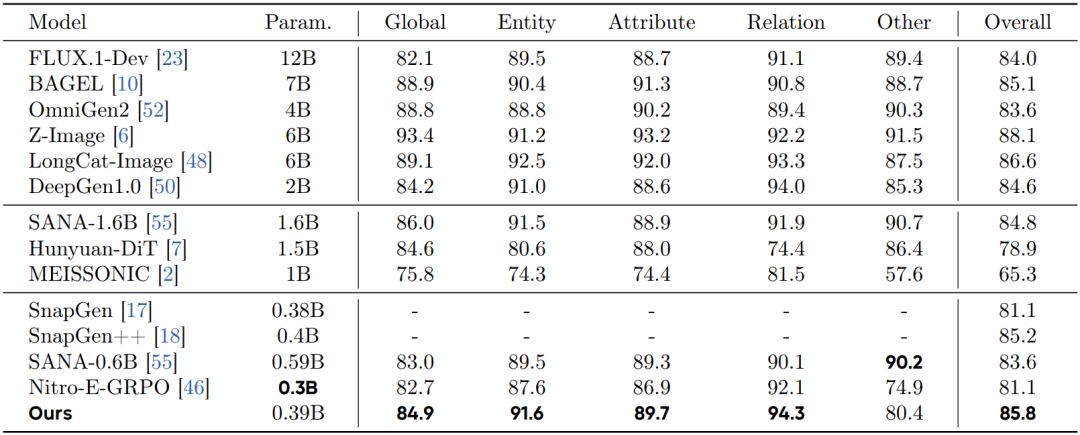
图像编辑性能:据现有文献所知,DreamLite 是首个在模型规模显著低于 0.5B 参数的情况下成功实现端侧图像编辑任务的模型。表 3 总结了 ImgEdit 基准上的模型规模、各分项得分及整体性能。DreamLite 在所有轻量级模型中达到了最先进水平。
表 3 ImgEdit 基准上的评估结果。
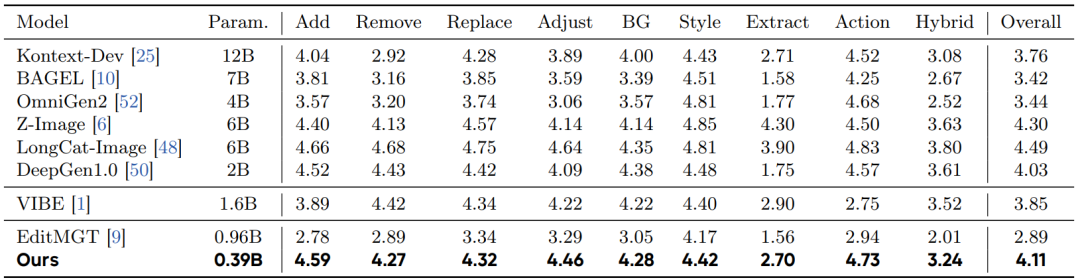
2. 端侧部署
为评估 DreamLite 的实际部署性能,在小米 14(骁龙 8 Gen3)与 vivo X100(天玑 9300)上进行实测。采用 W8A8 量化的 U-Net 骨干网络,分辨率 1024×1024,采样 4 步。
运行时优化:标准 Qwen3-VL 文本编码器(约 2B 参数)是主要延迟瓶颈。因此,将常用提示(如风格化或预定义编辑任务)的嵌入预计算并预置在设备上以实现即时交互。
性能分析:如表 4 所示,骁龙 8 Gen3 上 U-Net 单步推理仅 103.84ms,总生成/编辑时间约 0.42s(不含 VAE)。加上 VAE 解码(约 22ms)与系统开销,端到端耗时接近 1s。图 5 展示了生成(左)与编辑(右)结果。
表 4 DreamLite 各组件在 1024×1024 分辨率下的端侧推理延迟(毫秒)。
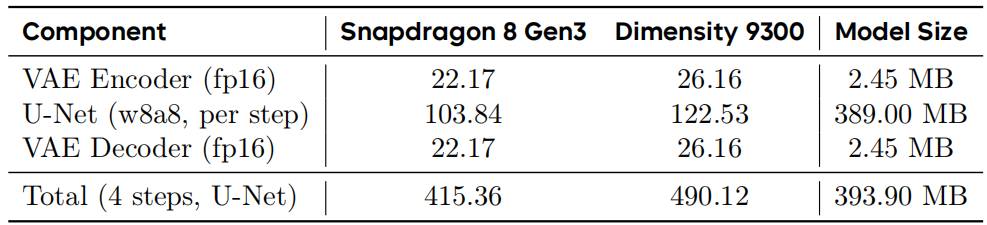

图 5 DreamLite 在移动设备上的生成与编辑示例。

 关注公众号
关注公众号