2026-04-20 19:57:00
2026-04-20 19:57:00
智猩猩AI整理
编辑:汐汐
4月8日,Anthropic发布了Claude Mythos,该模型在网络安全、系统性泛化、深度推理等前沿任务上展现出惊人能力。然而,Anthropic除了发布指标对比和一份长达245页的论文之外,并未透露更多的模型细节。
短短十余天后,4月19日,22岁的开发者Kye Gomez基于公开文献与模型行为,推断并发布了Claude Mythos的理论复刻版开源项目OpenMythos。该项目并非Claude Mythos的模型泄露,而是一个从公开论文和社区假设中逆向重建的完整实现。
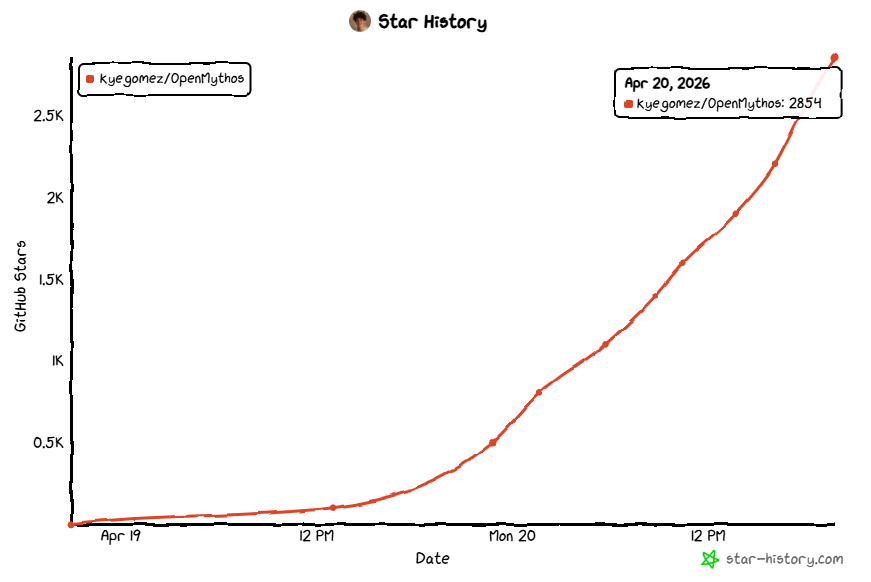
项目开源仅仅2天就已经超2.9k Stars了。
项目地址:https://github.com/kyegomez/OpenMythos
01 OpenMythos:
核心思想与项目架构
一、OpenMythos的架构来源
OpenMythos的设计直接源于Mythos System Card中的公开描述以及社区早期关键推测。
4月15日,用户@yuekun_yao发帖,怀疑Claude Mythos可能是一个Looped Transformer,并发布了论文。

4月16日,那个曾经第一时间把泄露的Claude Code源码重写的用户@realsigridjin阅读该论文后,同样也认为Mythos并非简单堆叠更多的层,而是通过同一组权重在单次前向传播中循环多次实现有效深度。


此外,项目还参考了多篇相关工作,如下图所示。

这些社区分析和论文文献等共同构成了OpenMythos的理论基础。开发者Kye Gomez明确强调,项目完全不涉及任何模型权重泄露,而是基于理论的架构重建。

二、OpenMythos的核心思想与项目架构
OpenMythos的核心思想其实就是一句话,“模型的能力不仅仅取决于参数量,更取决于推理的循环深度”。

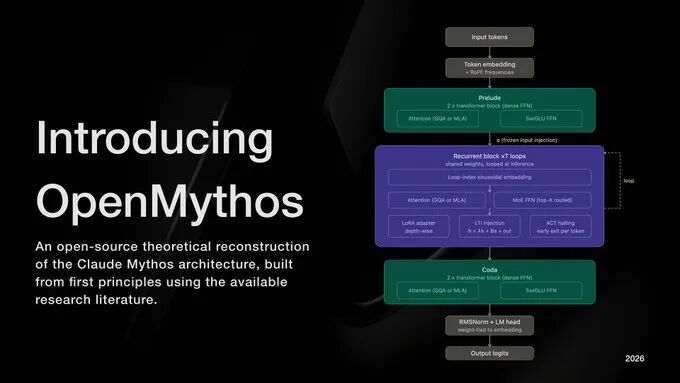
这个项目采用了Recurrent-Depth Transformer架构,整个模型分为3个模块,分别是Prelude、Recurrent Block和Coda。

Prelude:标准 Transformer 块,执行一次,完成初始编码;
Recurrent Block:核心循环模块;
Coda:最终标准 Transformer 块,完成输出。
循环块内部,OpenMythos主动吸收了DeepSeek在MoE和注意力机制上的高效设计,采用稀疏MoE前馈网络,该稀疏MoE前馈网络作为DeepSeekMoE的变体,包含大量细粒度路由专家与少量共享专家,仅激活top-k子集;注意力机制支持MLA或GQA,极大降低KV缓存开销。
同时引入深度自适应LoRA与自适应计算时间(ACT)机制,让不同循环深度实现“计算路径差异化”。
该项目770M参数的循环模型在相同的训练数据上可以匹敌1.3B的标准模型。

三、快速下载并上手使用
可以通过如下命令安装:
pip install open-mythos#uv pip install open-mythos通过如下方式快速上手使用:
import torchfrom open_mythos.main import OpenMythos, MythosConfig
attn_type = "mla" # or "gqa"
base = { "vocab_size": 1000, "dim": 256, "n_heads": 8, "max_seq_len": 128, "max_loop_iters": 4, "prelude_layers": 1, "coda_layers": 1, "n_experts": 8, "n_shared_experts": 1, "n_experts_per_tok": 2, "expert_dim": 64, "lora_rank": 8, "attn_type": attn_type,}
if attn_type == "gqa": cfg = MythosConfig(**base, n_kv_heads=2)else: cfg = MythosConfig( **base, n_kv_heads=8, kv_lora_rank=32, q_lora_rank=64, qk_rope_head_dim=16, qk_nope_head_dim=16, v_head_dim=16, )
model = OpenMythos(cfg)total = sum(p.numel() for p in model.parameters())print(f"\n[{attn_type.upper()}] Parameters: {total:,}")
ids = torch.randint(0, cfg.vocab_size, (2, 16))logits = model(ids, n_loops=4)print(f"[{attn_type.upper()}] Logits shape: {logits.shape}")
out = model.generate(ids, max_new_tokens=8, n_loops=8)print(f"[{attn_type.upper()}] Generated shape: {out.shape}")
A = model.recurrent.injection.get_A()print( f"[{attn_type.upper()}] Spectral radius ρ(A) max: {A.max().item():.4f} (must be < 1)")完整训练脚本(FineWeb-Edu 3B 模型)也已开源,支持单卡 / 多卡 torchrun 启动。
02 循环深度+MoE:不用无休止地增加参数量
OpenMythos 发布后,许多开发者和技术爱好者以及吃瓜群众都围了上来。
开发者账号Cryptopia长文分析Mythos的这一架构对于对齐、安全研究的冲击。

例如,有开发者质疑称,光是路由开销就会毁掉所有理论上的效率提升。
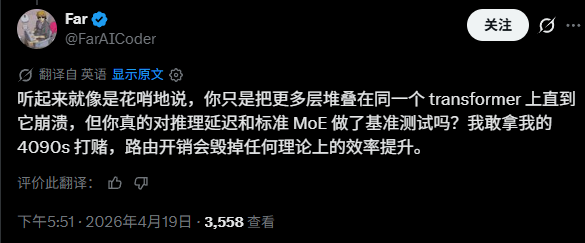
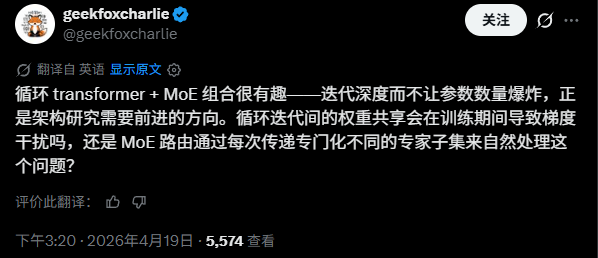
同样的,还有开发者认为使用循环transformer+MoE的组合非常有意思。但是仍然疑问会不会出现梯度干扰等问题。
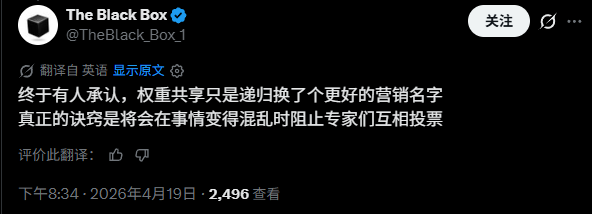
有用户觉得,所谓“权重共享”不过是递归的另一个名字,而关键实际在于别让专家互相投票。
另外还有开发者分析表示,“与其无休止地增加参数,这种方法把reasoning作为推理阶段发生的事情,而不用在训练阶段塞进一个巨型模型”。

03 “高效推理”新思路:开源社区“第一性原则”的惊人潜力
此前Mythos虽然已经公开了System Card,但是因为训练资料、数据比重、细节等所有内容全部闭源,所有用户都只能隔靴搔痒。而OpenMythos仅仅用了两周,将循环深度transformer变成了消费级GPU也能跑起来的PyTorch实现。
对于模型推理来说,以770M就能追上1.3B参数量模型的这种强度,明确告诉业界这种架构是高效推理的新思路。
毕竟理论复刻总是因为存在各种闭源导致的信息不对称和各种细节确实,无论在后续的测试中能够完全复现Mythos论文中描述的所谓“系统性泛化”等各项表现,它都以亮眼而纯粹的方式,诠释了开源社区的强大能力。
不依赖Anthropic内部的代码或权重,从最基础的公开信息和根本原理出发,重新推导并构建出了整个架构,这就是OpenMythos的“第一性原则”。

 关注公众号
关注公众号