2026-04-19 12:00:00
2026-04-19 12:00:00
智猩猩AI整理
编辑:没方
在 AI4Science 场景里,科技文献从来不只是“搜一下论文”这么简单。对研究者来说,真正耗时的往往是筛选、比对、引用追踪、证据组织与研究串联;对智能体来说,这件事情更加关键,Claude Code 等越来越多的 Agent 已经开始进入科研辅助、代码辅助和知识工作流。
换句话说,科技文献检索不再只是一个搜索工具问题,而是一个同时涉及基础设施、算法与应用系统的问题。
为此,中科大研究团队开源了一整套面向科技文献场景的搜索与智能体能力套件。
围绕这个方向,研究团队正在沿着两条路线同时推进:
一条是
Human-centric,让研究者真正把科技文献搜索用起来;
图 1:Lewen-Agent / 学术乐问
已经面向真实研究者提供科技文献检索体验。
另一条是
Agent-centric,让 Agent 真正把科技文献检索能力调起来。
图 2:学术鲁班正在承接科研Skills 的管理、分发与平台化扩展。
01 Human-centric 与 Agent-centric:一套体系,两条主线
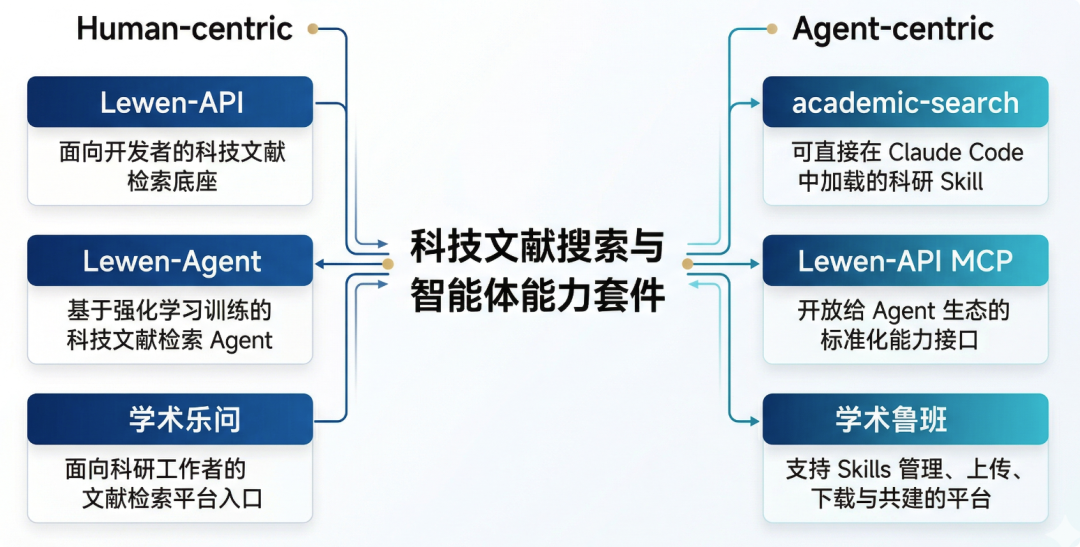
研究团队在同时为“人”和“Agent”建设科技文献能力生态。
在 Human-centric 这条线上,Lewen-API 提供了面向开发者的科技文献能力底座,Lewen-Agent 和 学术乐问则把这些能力交给真实研究者使用。
在 Agent-centric 这条线上,academic-search 已经成为可直接在 Claude Code 中一键使用的科研 Skill,Lewen-API MCP 也将继续向 Agent 生态开放,学术鲁班则承担起 Skills 管理、上传、下载与共建的平台角色。
academic-search GitHub:https://github.com/ustc-ai4science/academic-search
Lewen-API GitHub:https://github.com/ustc-ai4science/Lewen-API
Lewen-API Docs:https://ustc-ai4science.github.io/Lewen-API/
Lewen-Agent GitHub:https://github.com/ustc-ai4science/Lewen-Agent
Lewen-Agent / 学术乐问:https://lewen.bdaa.pro/
学术鲁班:https://luban.bdaa.pro/
02 基建:把科技文献检索做成既能给人用、也能给 Agent 调的底座
如果把整套能力视为一个系统,首先需要解决的是底座问题。
Lewen-API 正是在这一层承担科技文献检索基础设施的角色:它面向科研场景统一了论文对象、检索对象与引用关系,支持语义检索、关键词过滤以及引用/被引用关系建模。
在技术上,系统采用 SQLite + FTS5 + Qdrant + BGE-M3 + RRF 的组合:前者负责轻量稳定的稀疏检索与元数据管理,后者提供向量语义检索能力,并通过 RRF 融合多路结果。
当前已覆盖约 300 万篇论文元数据与 3000 万条引用关系,形成了可复用的科研检索底座,并计划进一步通过 MCP 对外开放以支持 Agent 生态。
与之相对应,academic-search 则代表了另一种同样重要的“基建”:它是一个面向科技文献场景封装好的 Skill。
在 Agent 时代,Skills 的价值并不只是“教模型一句提示词”,而是把某个任务域的规则、策略、脚本、接口与资源组织成可以被直接加载和复用的能力单元。academic-search 正是在做这件事。它把学术搜索从泛化网页浏览提升为可供 Agent 直接调用的科研能力模块,而且已经可以直接在 Claude Code 中一键使用。
一个提供底层检索基础设施,一个提供面向 Agent 的任务能力封装,前者让科技文献能力可服务于系统,后者让科技文献能力可服务于智能体。
与此同时,academic-search 与 figure-plot 也已经成为当前鲁班平台上的代表性科研 Skills,共同构成面向科研工作流的能力样板。
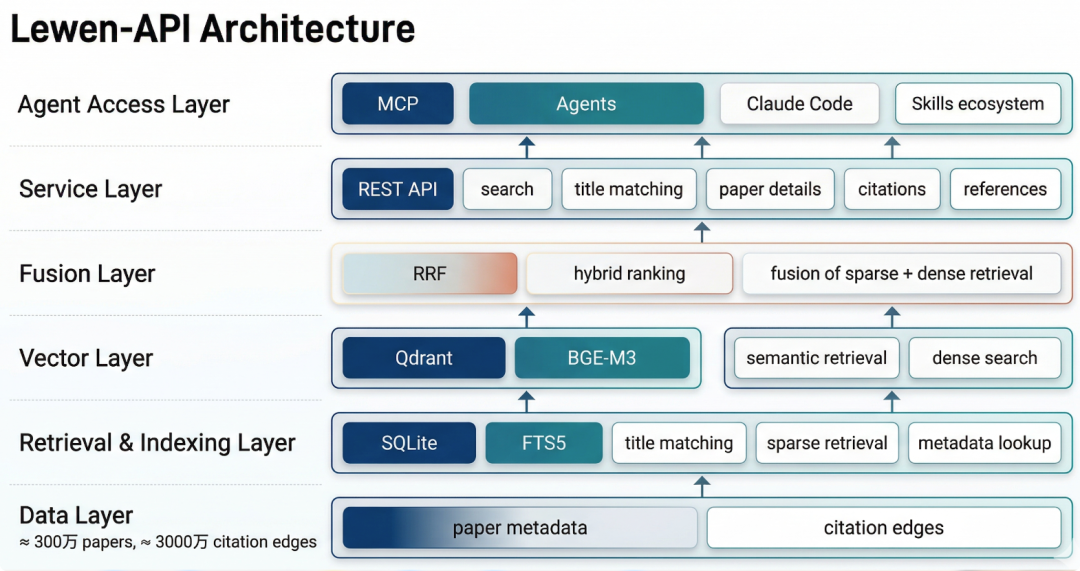
图 3:Lewen-API 从数据层、检索层、向量层到 API / MCP 接入层,
构成科技文献场景的底层基础设施。
03 算法创新:让学术搜索 Agent 从执行流程,变成自主决策
有了底层能力之后,下一个问题就变成了:一个学术搜索 Agent 究竟应该怎样“工作”?
传统的学术搜索 Agent 往往更像一个固定工作流。它们可以根据预设流程调用搜索、扩展、总结等步骤。
但真正困难的科技文献搜索,本质上并不是把几个步骤串起来,而是一个多轮决策问题:搜什么、扩什么、什么时候停、下一步往哪里走。
研究团队从算法层面提出 PaperScout:强化学习训练的学术搜索 Agent。
PaperScout 的核心价值,在于把学术搜索从固定 workflow 推进到自主决策过程。
它不再把搜索看成简单的“执行一组工具”,而是把科技文献检索建模为一个需要持续判断、持续更新策略的过程。
与之配套提出的 PSPO,则把优化目标真正落到 sequence-level 的多轮 Agent 行为上,而不只是 token-level 的局部输出。这套算法创新的重点是要智能体学会在什么时候继续 search、什么时候值得 expand、什么时候应该收束,并且把这些选择真正转化成更好的科技文献检索结果。
更重要的是,PaperScout 并没有停留在论文层面。Lewen-Agent 正是基于 Lewen-API 和 PaperScout 构建的科技文献检索 Agent,这意味着算法成果并不是孤立存在的研究原型,而是已经进入实际系统,开始服务真实的科技文献场景。
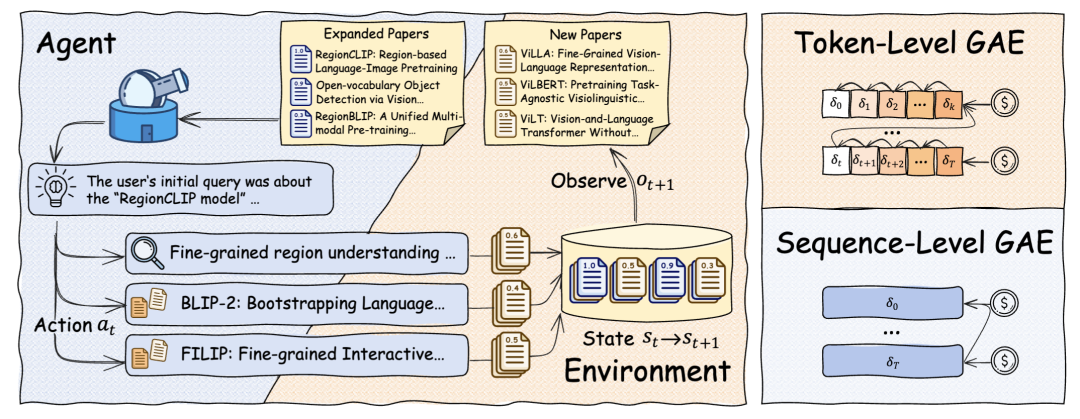
图4:PaperScout + PSPO 把学术搜索 Agent
从固定流程执行推进到自主决策。
04 智能体应用:把科技文献能力真正带进研究工作流
如果说基建解决的是“能力从哪里来”,算法解决的是“能力如何更聪明”,那么应用层解决的就是“能力如何真正进入研究者日常工作”。
在这一层,Lewen-Agent / 学术乐问承担的是面向研究者的科技文献检索 Agent。它基于Lewen-API + PaperScout 构建,已经部署在 lewen.bdaa.pro。底层检索能力和 Agent 决策能力第一次被真正组织成可供研究者直接体验、直接使用的科技文献服务。算法和 API 已经开始变成可进入科研工作流的实际系统。
另一方面,学术鲁班是一个面向科研场景的 Skills 平台,当前已经包括 academic-search、figure-plot 等代表性科研 Skills,并支持 Skills 管理、上传、下载。未来,鲁班将继续向科技文献平台演进,逐步加入论文阅读、论文写作等更多能力,也欢迎更多用户把自己的 Skills 提交到平台里,共同扩展科研工作流的能力边界。
研究团队想做的,不只是一个“会查论文”的工具,而是一套真正能进入研究工作流、同时面向研究者与 Agent 演化的科技文献能力系统。

 关注公众号
关注公众号