2026-04-13 18:37:00
2026-04-13 18:37:00
智猩猩AI整理
编辑:没方
你是不是也被智能体的记忆障碍逼疯过?
昨天教它的流程、上周导入的文档、反复强调的规则,转头就忘。每次对话都像重新培训,用户总被迫当 “人肉提示词工程师”,重复调教、反复校对,精力全耗在帮 AI 回忆上,效率大打折扣。
于是,大家把希望寄托在 RAG 上——既然记不住,那就“去搜”。
可问题是,搜得到 ≠ 想得起。
传统RAG本质上只是一个“临时查资料”的工具:要么依赖关键词匹配,容易漏掉真正语义相关的内容;要么只靠向量相似度,又常常抓不住精准的规则和关键字段。
更要命的是,它只是把零散的文本片段临时拼进上下文,既没有形成结构化的知识沉淀,也没有留下可追溯的证据链。
Agent每次都像“临时翻书”,而不是真正把知识“记住”。
再加上向量检索本身的不稳定、上下文窗口的硬性限制、历史信息无法长期累积。Agent用得越久,反而越乱,始终停留在“一次性工具”的阶段。
最近,Y Combinator总裁Garry Tan开源了GBrain,这是专为OpenClaw、Hermes等Agent设计的“个人知识大脑”。它不是单纯依赖临时上下文或单一 RAG 查询,而是以 Markdown 仓库作为唯一真相源,结合 Postgres 和 pgvector 的混合检索引擎,构建了一个可持续读写、人机共管、自动整理的长期记忆系统。GBrain能够实现“读前查脑、用后写脑、夜间巩固(dream cycle)”,让知识像雪球一样越滚越大,Agent越用越聪明。该项目在github上已收获6.9k Stars。
项目链接:
https://github.com/garrytan/gbrain
01 项目介绍
GBrain 是面向 AI 智能体的开源个人知识记忆系统,定位是 Agent 的 “外置永久大脑”,把散落在 Markdown、Obsidian、会议纪要、邮件里的知识,都变成能被智能体高效调用的结构化记忆库。
GBrain 并非要替代 OpenClaw / Hermes的原有记忆,而是与它们形成互补的三层记忆架构,让智能体同时拥有长期知识、运行状态与实时上下文。
GBrain:负责存储人物、公司、交易、会议、观点、原创思考等客观事实与通用认知,是智能体的长期世界知识库。
Agent Memory:负责存储偏好、决策、运行配置、行为规则等业务状态信息。
Session Context:自动维护当前对话内容,提供即时交互上下文。
GBrain 核心设计理念如下:
(1)Compiled Truth 和 Timeline 双层结构
每个 Markdown 页面分为当前最佳理解(Compiled Truth)和时间线(Timeline )证据两部分,分别存放“最新结论”与“历史证据”,让知识既可查询又可追溯。人类能直接编辑Markdown,改完gbrain sync就自动同步,真正做到了“人机共管”。
(2)混合检索
支持向量搜索、关键词搜索以及RRF融合,兼顾语义理解与精确匹配,不遗漏关键信息。检索机制如下:
Query: "when should you ignore conventional wisdom?"|多查询拓展(Claude Haiku)"contrarian thinking startups", "going against the crowd"|+-------+-------+| |向量检索 关键词检索(HNSW (tsvector +cosine) ts_rank)+-------+-------+| ||RRF Fusion: score = sum(1/(60 + rank))|
四层去重机制(4-Layer Dedup)1、每页只保留最优文本块2、余弦相似度 > 0.853、类型多样性(上限 60%)4、单页文本块数量上限|过时提醒(精炼结论比最新时间线内容更旧)|返回最终结果(3)智能分块
GBrain 会根据内容类型,采用三种文本分块策略:
递归分块(适用于时间线、批量导入):采用 5 级分隔符层级结构(段落、行、句子、从句、词语)。以 300 词为文本块,保留 50 词重叠区。速度快、效果稳定、无信息丢失。
语义分块(适用于精炼结论内容):对每个句子单独生成向量嵌入,计算相邻句子的余弦相似度,通过Savitzky-Golay平滑法识别主题边界。若识别失败则自动回退到递归分块。在智能分析场景下效果最优。
LLM 引导分块(适用于高价值内容,按需启用):先预分割为 128 词的候选片段,再通过 Claude Haiku 在滑动窗口中识别主题转变。每个窗口支持 3 次重试。成本最高,但效果最佳。
(4)丰富实体
当会议、邮件、推文、链接等新信号到来时,智能体首先自动识别其中的实体(人物、公司、观点等), 然后先查记忆库,带着完整上下文进行回应, 接着把新信息写入gbrain,更新相关页面,并同步索引供下次使用。
每完成一次这样的读-写-循环,知识库就真正增加了一份积累。 一次会议后,智能体自动丰富了某人的个人页面。下次这个人再次出现时,智能体已经拥有了丰富上下文,再也不用从零开始。
没有这套循环的智能体,永远只能靠陈旧或临时的上下文回答问题。而搭载了 GBrain 的智能体,每一次对话都在变得更聪明。
(5)夜间巩固(dream cycle)
夜间定时任务(cron)自动扫描所有对话、补充缺失的实体、修复错误的引用、整理记忆。像人类睡眠时大脑巩固记忆一样,让知识真正“长”起来。
02 使用方法
(1)环境准备
零配置启动(PGLite):
执行 gbrain init 即可创建一个本地嵌入式 Postgres 记忆库。无需注册账号、无需独立服务器、无需 API 密钥。关键词检索可直接使用,后续可再补充 API 密钥以开启向量检索与 LLM 相关功能。
生产级扩展(Supabase):
当本地存储无法满足需求时,可通过 gbrain migrate --to supabase 将所有数据一键迁移至托管的 Postgres 数据库。
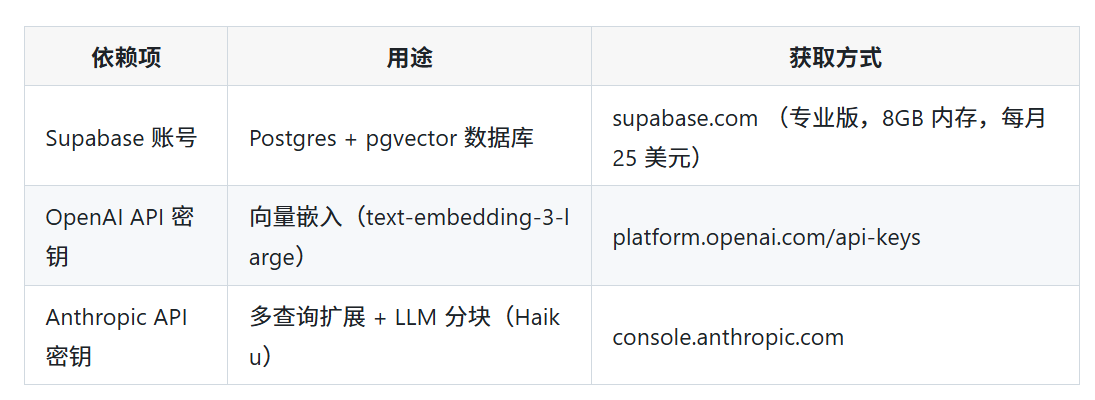
将 API 密钥配置为环境变量:
export OPENAI_API_KEY=sk-...export ANTHROPIC_API_KEY=sk-ant-...gbrain init --supabase
时配置。OpenAI 与 Anthropic SDK 会自动从环境变量中读取密钥。无 OpenAI 密钥:检索仍可使用(仅支持关键词检索,无向量检索)
无 Anthropic 密钥:检索仍可使用(无多查询扩展、无 LLM 分块)
(2)使用
GBrain 可与任意 AI 智能体、MCP 客户端配合使用,也可独立运行。
① OpenClaw或 Hermes
将此仓库( https://github.com/garrytan/gbrain)克隆到智能体文件系统中,这是文档、技能、升级脚本和使用方案的核心目录。
后续升级命令:git pull origin main && bun install
将下面这段配置复制到 OpenClaw、Hermes 或任意支持持久化的 AI 智能体中。智能体会自动阅读文档、完成部署,并向你索要 API 密钥。整个过程约 30 分钟。
INSTALL:
git clone https://github.com/garrytan/gbrain.git ~/gbrain && cd ~/gbrain curl -fsSL https://bun.sh/install | bash export PATH="$HOME/.bun/bin:$PATH" bun install && bun link Verify: gbrain --version (If gbrain is not found, restart your shell or add the PATH export to your shell profile.)
API KEYS — ask the user for these:
export OPENAI_API_KEY=sk-... # required for vector search export ANTHROPIC_API_KEY=sk-ant-... # optional, improves search quality Save to shell profile or .env. Without OpenAI, keyword search still works. Without Anthropic, search works but skips query expansion.
SET UP THE BRAIN:
gbrain init # PGLite, no server needed Verify: gbrain doctor --json # all checks pass
The user's markdown files (notes, docs, brain repo) are SEPARATE from this tool repo. Ask the user where their files are, or create a new brain repo: mkdir -p ~/brain && cd ~/brain && git init
Read ~/gbrain/docs/GBRAIN_RECOMMENDED_SCHEMA.md — set up the MECE directory structure (people/, companies/, concepts/, etc.) inside the user's brain repo, NOT inside ~/gbrain.
gbrain import ~/brain/ --no-embed # import markdown files gbrain embed --stale # generate vector embeddings gbrain query "key themes across these documents?"
GO LIVE — read and permanently adopt these docs from ~/gbrain/:
docs/GBRAIN_SKILLPACK.md — the full agent playbook. Save to your memory: brain-first lookup on every message, entity detection, back-linking. This changes how you behave permanently.
Set up recurring jobs using your platform's scheduler (crontab, OpenClaw cron, Railway cron, or a process manager): - Live sync (every 15 min): gbrain sync --repo ~/brain && gbrain embed --stale - Auto-update (daily): gbrain check-update --json (tell user, never auto-install) - Dream cycle (nightly): read docs/guides/cron-schedule.md for the full protocol — entity sweep, citation fixes, memory consolidation. This is what makes the brain compound. Do not skip it. - Weekly: gbrain doctor --json && gbrain embed --stale
docs/GBRAIN_VERIFY.md — run all 6 verification checks. #4 (live sync actually works) is the most important.
INTEGRATIONS — run gbrain integrations list. Each recipe in ~/gbrain/recipes/ is a self-contained installer: it tells you what credentials to ask for, how to validate, and what cron to register. Ask the user which integrations they want (email, calendar, voice, Twitter). Set up the ones they have credentials for. Verify: gbrain integrations doctor (after at least one is configured)
UPGRADE: cd ~/gbrain && git pull origin main && bun install②独立 CLI 命令行工具
git clone https://github.com/garrytan/gbrain.git && cd gbrain && bun install && bun linkgbrain init # 本地记忆库,2秒就绪gbrain import ~/notes/ # 为笔记建立索引gbrain query "what themes show up across my notes?"③MCP 服务端(Claude Code、Cursor、Windsurf 等)
GBrain 通过标准输入输出公开了30 个 MCP 工具。将以下配置添加到 MCP 客户端配置:
Claude Code (~/.claude/server.json):
{ "mcpServers": { "gbrain": { "command": "gbrain", "args": ["serve"] } }}配置后,智能体将拥有 get_page、put_page、search、query、add_link、traverse_graph、sync_brain、file_upload 等共计 30 余项工具。
仅工具还不够,智能体需要执行策略。阅读 GBRAIN_SKILLPACK.md,并将相关内容粘贴到智能体的系统提示词或项目指令中。
技能包会告诉智能体何时、如何使用各项工具:响应前先查阅记忆、学习后写入记忆、每条消息都识别实体、为所有内容建立反向链接。
skills/ 目录下的 Markdown 文件为独立指令集,可直接复制到智能体上下文。
完整步骤请参考:
https://github.com/garrytan/gbrain?tab=readme-ov-file#start-here
03 从“短时响应”迈向“长期智能”
GBrain 的出现不仅是工具升级,更标志着 AI 智能体从“短时响应”向“长期智能”迈出关键一步。
当前大多数 AI Agent 会话结束即忘、记忆碎片化、知识无法沉淀,这阻碍了智能体的复利成长。
而 GBrain 将记忆基建化、知识结构化、智能自治化。它把用户日志、文档、对话等构建成长期可读写的知识库,让 Agent 在每次对话前调取上下文,结束后写入新信息,并通过自动整理不断自我增强。

 关注公众号
关注公众号