2026-04-14 12:38:00
2026-04-14 12:38:00
智猩猩AI整理
编辑:宁宁
长上下文已经成为大模型能力竞争中的关键方向。无论是长文档问答、多轮对话、代码仓库理解,还是复杂检索,模型都越来越依赖对超长序列的处理能力。但问题在于,长上下文训练的代价一直很高:(i)序列长度增加会显著推高显存占用与计算开销;(ii)高质量长文本语料也并不容易规模化获取。这一问题对端侧小模型尤为突出,因为训练阶段一旦发生数据分布切换,还可能带来明显的能力回退。
在这种背景下,Meta Reality Labs 团队提出了 Short Data, Long Context,聚焦一个关键问题:学生模型即便未真正见过长文档、只在超长窗口中接触大量拼接短文本,能否仍获得长上下文检索能力。研究团队给出的答案是肯定的。该工作从 RoPE 机制出发,指出教师模型中的位置扰动会在前向传播中逐层传递并最终反映到输出 logits 上,学生模型则可通过 logit-based knowledge distillation 吸收这些隐式位置信号,实现长距离检索能力迁移。实验结果表明,phase-wise 的 RoPE base 缩放策略效果最佳,KD 显著优于 CE;进一步分析还发现,长上下文扩展并非简单记住更远位置,而是主要表现为与远距离位置关系相关的部分维度发生定向适配,为小模型低成本获得长上下文检索能力提供了一条值得重视的新路径。

论文标题:Short Data, Long Context: Distilling Positional Knowledge in Transformers
原文链接:https://arxiv.org/pdf/2604.06070v1
01 方法
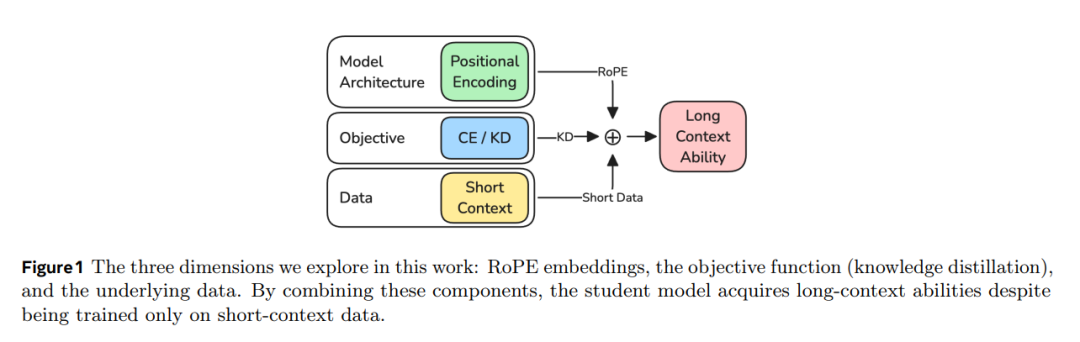
(1) 两阶段训练:窗口拉长了,但数据仍然很短
研究团队采用教师—学生蒸馏框架。教师模型是具备强长上下文能力的 Llama-4 Scout,学生模型是一个约 1.1B 参数的小模型。训练分为两个阶段:第一阶段使用 2048 tokens 的短上下文进行预训练;第二阶段将上下文窗口扩展到 128k tokens,继续训练。
但最关键的设定在于:第二阶段虽然窗口很长,训练数据却依然不是长文档。研究团队将许多短文档打包进同一个 128k 序列中,文档之间用 EOS 分隔,并使用 attention mask 阻止跨文档注意力。这意味着不同短文档之间在语义上彼此隔离,唯一仍然以全序列形式存在的信号,主要就是位置编码。
这一步设计非常重要。因为它等于人为排除了“学生通过长文本语义学习长能力”的解释,把问题聚焦到一个更核心的层面:学生学到的长上下文能力,究竟是不是来自位置知识迁移。
(2)方法核心:RoPE 不是背景板,而是知识迁移的入口
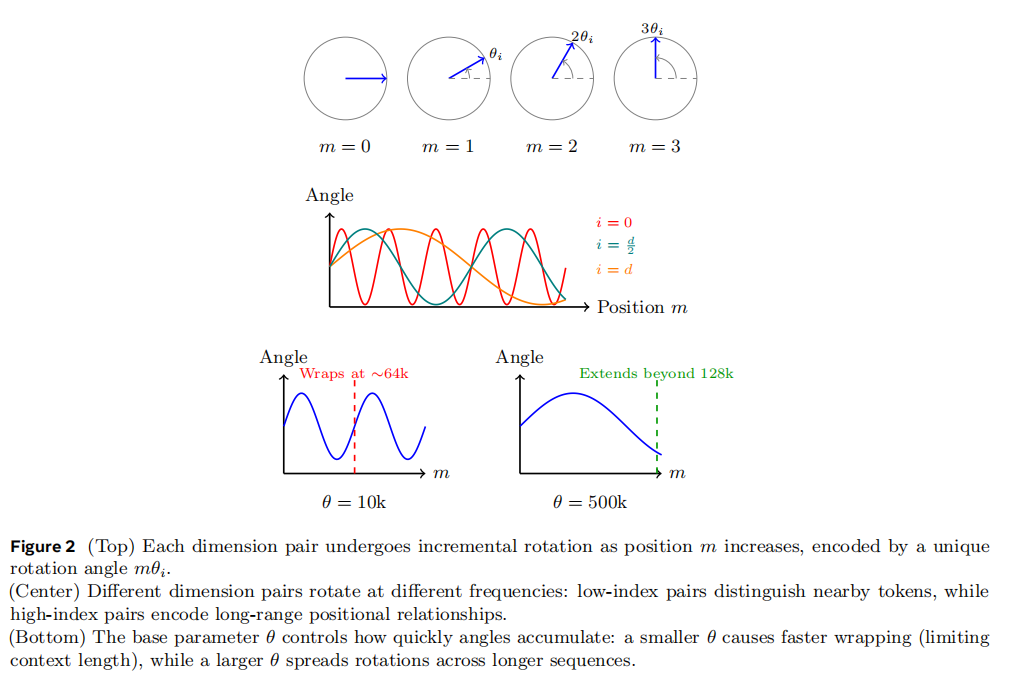
研究团队将机制解释建立在 RoPE 上。RoPE 并不是把位置直接加到 token embedding 上,而是通过旋转 query 和 key,让 attention 的点积自然携带位置信息。不同维度对对应不同频率:低索引维度更擅长近距离位置区分,高索引维度更负责长距离位置关系建模。θ 越大,旋转“展开”越慢,模型越能区分更远的位置。具体见图2。
基于这一点,研究团队比较了三种 θ 设置:全程固定 10k、全程固定 500k,以及分阶段缩放的 10k→500k。研究团队的判断是,短上下文阶段用较小 θ,更有利于充分利用旋转谱;长上下文阶段再切换到更大的 θ,则能避免高位置出现过快绕回,从而提升远距离位置区分能力。研究团队最终将这种策略概括为:在不同训练阶段最大化 RoPE 旋转谱的有效利用。
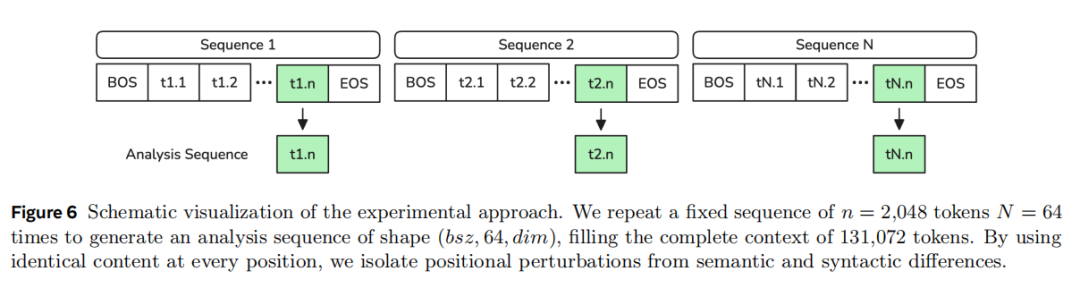
(3) 关键实验设计:用重复序列“逼出”纯粹的位置效应
为了证明教师 logits 中确实包含位置信息,研究团队设计了一个很巧妙的实验:把一个固定的 2048-token 文本块重复 64 次,正好填满完整长窗口,如图6所示。由于 64 个块的语义和语法内容完全一致,因此不同块之间若出现 hidden state 或输出分布差异,就只能归因于位置,而不能归因于内容。
在这个设定下,研究团队依次记录 embedding、RoPE 前后的 query hidden state、最终隐藏状态以及输出 logits,追踪位置扰动如何在教师模型内部传播。研究团队还进一步验证了输入 token、embedding 以及 RoPE 之前的 query state 在 64 个重复块之间基本保持一致,这说明后续出现的差异确实主要来自位置编码,而不是文本内容。
这不只是在报告 benchmark 分数,而是在回答一个更底层的问题:蒸馏过程到底把什么东西传给了学生。
02 实验设置及结果分析
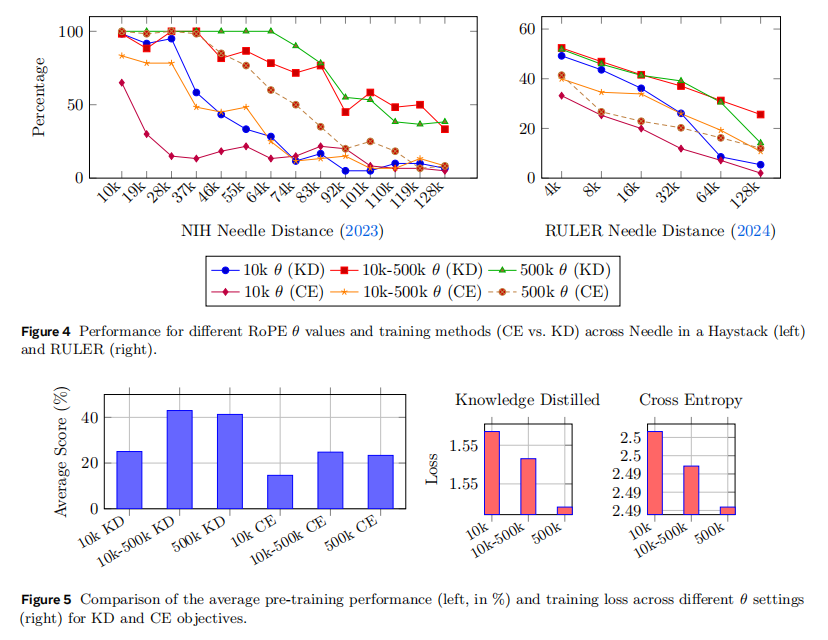
(1) 第一组结果:分阶段 RoPE 最优,KD 明显优于 CE
研究团队先比较了三种 θ 设置下,KD 模型与普通交叉熵训练模型在 Needle-in-a-Haystack 和 RULER 两类长上下文检索基准上的表现。结果很清楚:固定 10k 效果最弱,固定 500k 更强,而分阶段 10k→500k 的方案平均表现最好。与此同时,KD 在所有 θ 配置下都优于 CE,不仅长上下文检索成绩更高,训练 loss 也更低。如图4、5所示。
这组结果说明了两点。
第一,RoPE 的 base 参数不能简单一刀切,阶段感知式设置更合理。
第二,学生模型的长上下文能力并不是单靠把窗口拉长就能自然长出来;在同样吃 packed short-context data 的前提下,教师模型提供的蒸馏信号确实带来了额外收益。
(2) 第二组结果:位置扰动会一路传播到输出 logits
最有解释力的实验,是对位置扰动传播路径的分析。实验观察到:输入 token、embedding、以及 RoPE 之前的 query state,在 64 个重复块之间基本一致;一旦经过 RoPE,不同位置上的 hidden state 立即出现差异,而且这种差异会随着层数增加被不断放大。
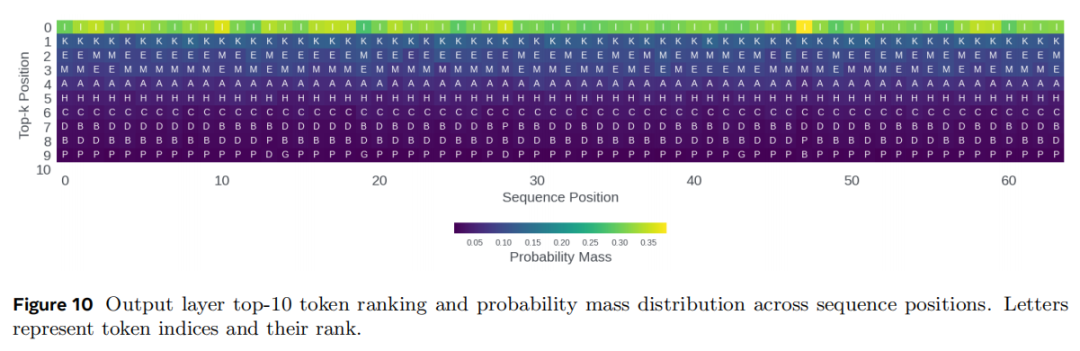
更关键的是输出层。研究团队发现,虽然不同位置上的 top-10 token 集合整体相近,但它们的概率质量和排序会发生系统性波动,如图10所示。也就是说,教师模型的输出分布并不只编码语义信息,还编码了位置相关信息。
研究团队据此给出核心判断:蒸馏目标本身是位置敏感的。学生通过拟合教师 logits,不只是学到了“下一个 token 应该是什么”,也学到了“这个 token 在什么位置时应当呈现怎样的分布”。这也正是为什么没有真正见过长文档的学生模型,仍然能够获得更强长上下文检索能力的关键原因:长上下文教师已经把位置知识编码进了输出分布,而知识蒸馏把这部分信号传递给了学生模型。
(3) 第三组结果:模型不是在记位置,而是在修“位置维度”
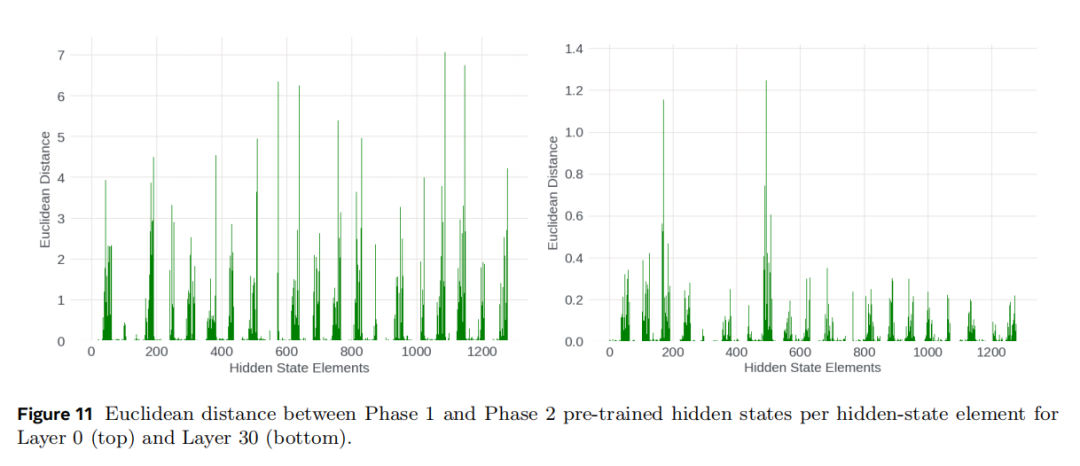
研究团队比较了短上下文阶段与长上下文阶段两个 checkpoint 的 hidden state 变化。结果显示变化最大的不是序列后半部分那些“更远的位置”,而是某些特定的 hidden-state 维度区间,如图11所示。尤其是高索引维度对,也就是与低频 RoPE 分量、长距离位置关系更相关的部分,变化最显著。相反,沿着序列位置方向看,并不存在“越靠后变化越大”的单调趋势。
这意味着,模型获得长上下文能力的方式,并不是记住某些固定绝对位置,而是针对性地更新了一部分与远距离位置编码最相关的内部表示维度。研究团队将其概括为:长上下文扩展是 dimension-specific 的,而不是 position-specific 的。
这其实很有启发性。它说明长上下文扩展不一定需要对整套表示体系“大修大补”,更像是在一小块关键 positional subspace 上完成了定向强化。
03 总结
从结果层面看,研究团队证明了一个很有现实价值的事实:即便训练数据主要还是短文本,只要教师具备长上下文能力,学生模型仍可能通过知识蒸馏获得更强的长距离检索能力。
从机制层面看,研究团队进一步给出了一条比较完整的解释链:
RoPE 引入位置扰动 → 扰动在教师模型中逐层传播并放大 → 输出 logits 呈现位置相关差异 → 学生通过 logit-based KD 学到这些隐式位置信号 → 长上下文扩展主要体现在特定位置维度的定向更新上。
这条链路的价值,在于它为资源敏感场景下的小模型训练提供了一个新思路:长上下文检索能力并不一定只能依赖大规模长文语料和昂贵长序列预训练,也可以通过更精细的蒸馏目标设计来迁移。对端侧模型、轻量模型、成本敏感部署来说,这是一条非常值得重视的路线。不过需要注意,当前结论主要建立在单一 teacher-student 配置和 NIH、RULER 这类检索型基准上,机制分析也仍以相关性证据为主。

 关注公众号
关注公众号