2026-04-10 11:24:00
2026-04-10 11:24:00
智猩猩AI整理
编辑:六六
生成式图像超分辨率(SR)最近有多火?几乎离不开大号文本到图像(T2I)扩散模型的加持——动辄在亿级图文数据上预训练,再微调适配到SR任务上。效果固然惊艳,但一个问题始终存在:SR 本质上是一个以低分辨率图像为条件的高质量复原任务,真的需要绕这么大一圈吗?
最新研究给出了否定答案。香港理工大学联合OPPO研究团队提出了 VOSR——一个纯视觉、无需任何图文多模态预训练的生成式超分辨率框架。VOSR所需的训练成本不到主流 T2I 类 SR 方法的十分之一,却在多步和单步设定下都能达到相当甚至更好的感知质量,结构更忠实、幻觉更少——无论是合成数据还是真实场景。成果相关论文已被 CVPR 2026 接收。

论文标题:VOSR: A Vision-Only Generative Model for Image Super-Resolution
论文链接:https://arxiv.org/pdf/2604.03225
01 方法
给定低分辨率(LR)图像,超分辨率旨在恢复出感知真实且与输入一致的高分辨率(HR)图像。与文本到图像生成不同,超分辨率纯以视觉为条件。基于此,构建了纯视觉生成式超分辨率框架 VOSR,整体流程如图 1(a) 所示。
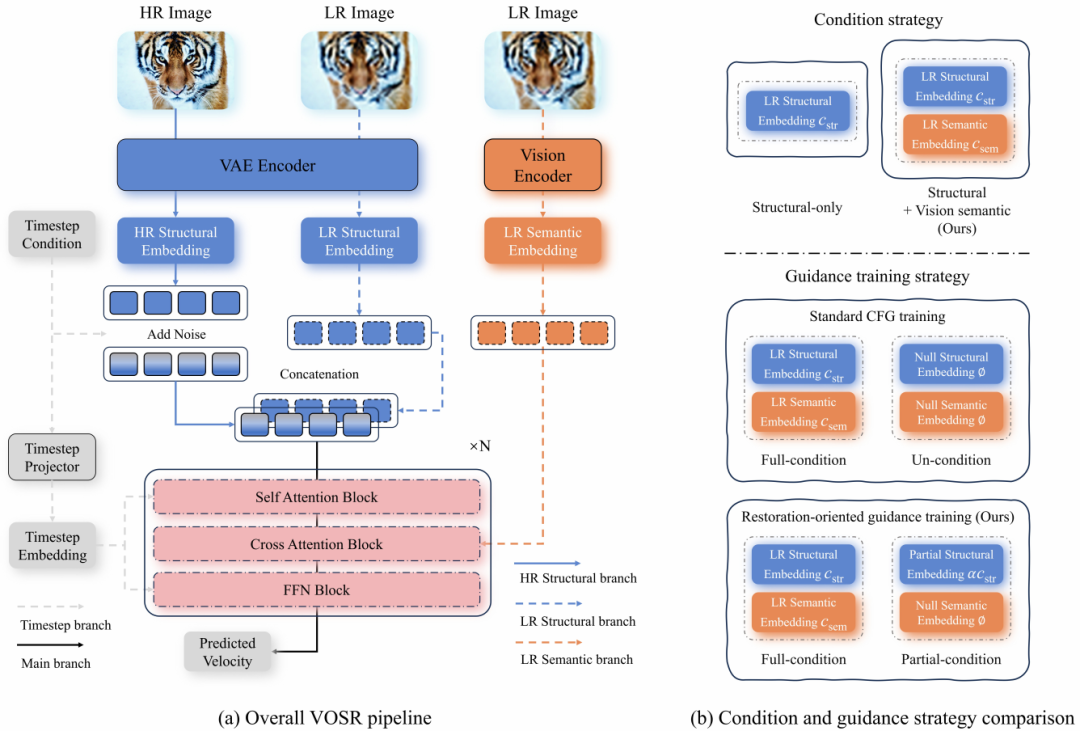
图 1 VOSR 方法概述。
1. 视觉语义条件
现有纯视觉生成式超分辨率模型主要依赖低分辨率输入的结构线索,但在严重退化下,单一结构条件因观测存在多种可能的高分辨率重建而引发语义歧义。为此,VOSR 采用双分支设计,融合低分辨率结构与语义信息。
结构分支使用与高分辨率图像相同的 VAE 编码器对低分辨率图像编码,获得结构条件以保留空间内容;同时,预训练视觉编码器提取语义条件。该语义条件完全源于视觉领域,不同于文本或文本对齐表示,更适用于细粒度复原。
去噪主干为 DiT,输入含噪高分辨率潜在变量与时间步嵌入。结构条件以空间对齐的潜在条件注入,语义条件通过交叉注意力引入以提供高层上下文。由此,结构特征保持空间保真度,语义特征解决细节合成中的歧义性,从而在纯视觉领域内引入高层语义,避免超分辨率中采用文本或文本对齐的条件。
2. 面向复原的引导
在定义视觉条件后,进一步探讨如何引导生成过程,以产生感知真实且与输入一致的复原结果。
标准 CFG(图 1(b))在文本到图像生成中有效,但对超分辨率并不合适:完全移除低分辨率输入后,辅助分支需学习通用生成,条件分支单独负责输入一致性,角色分离使优化困难。
为此,将无条件分支替换为部分条件分支,保留弱化结构线索并丢弃语义引导。
两分支均以输入为锚定,差异反映更强结构与语义引导的效果。训练时随机采样条件模式,优化目标为:
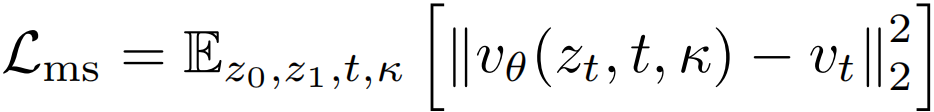
测试时应用引导:
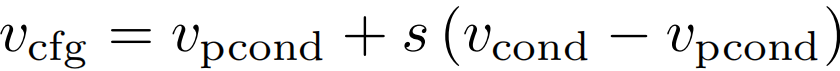
辅助分支仍以弱化输入为条件,引导方向从弱锚定移向强锚定。s 增大增强输入一致性,s 减小允许更大细节生成空间。
3. 面向高效推理的单步蒸馏
多步 VOSR 模型虽复原质量良好,但迭代采样开销较大。为此,将其蒸馏为单步学生模型,同时保留教师模型中的视觉语义条件与面向复原的引导。蒸馏仅改变采样效率,不改变复原的公式化形式。
在多种单步蒸馏变体中,基于递归一致性的方法在超分辨率任务中表现最佳,能在感知质量与结构保真度之间取得良好平衡。由此,VOSR 在保持多步教师模型面向复原特性的同时,实现了高效的单步推理。
02 评估
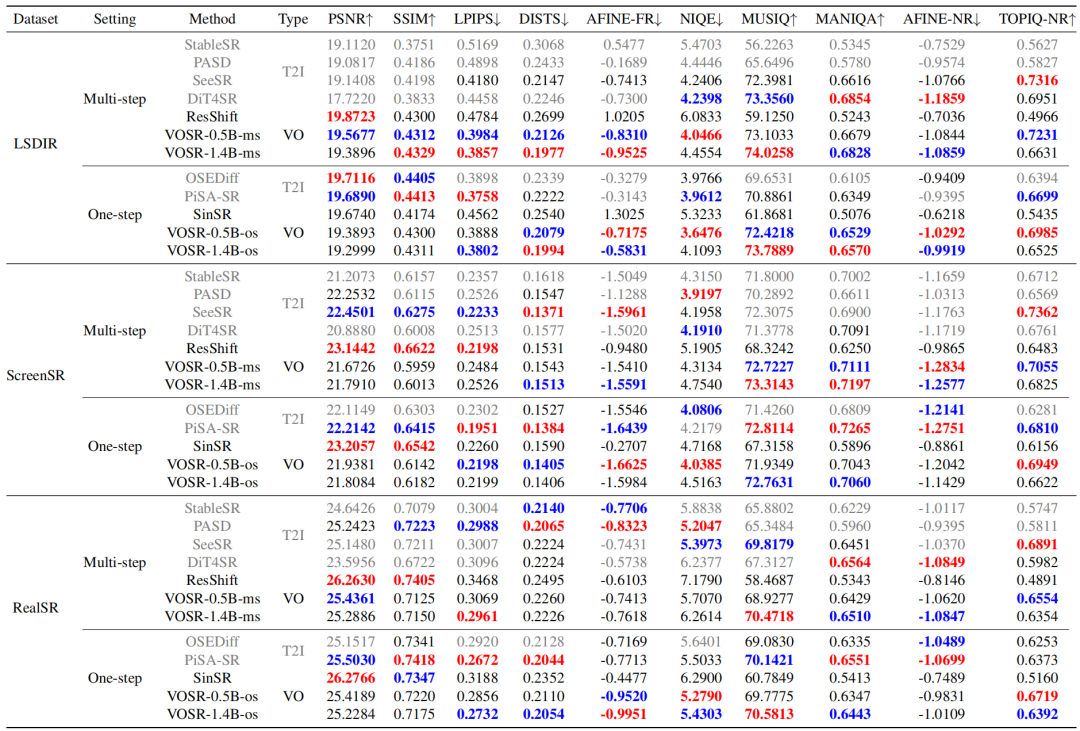
1. 定量比较
对于失真保真度,在 YCbCr 色彩空间的 Y 通道上报告 PSNR 和 SSIM。对于基于参考的感知质量,使用 LPIPS、DISTS 和 AFINE-FR。对于无参考感知质量,报告 NIQE、MUSIQ、MANIQA、AFINE-NR 和 TOPIQ-NR。
如表 1 所示,VOSR 持续优于先前的纯视觉方法,并与强大的基于 T2I 的方法保持竞争力,尤其在感知指标上表现突出。
在 LSDIR 上,VOSR-1.4B-ms 在多步设置下取得最优的 LPIPS、DISTS、AFINE-FR 和 MUSIQ,VOSR-0.5B-os 在单步设置下取得最优的 NIQE、AFINE-NR 和 TOPIQ-NR。
在真实世界基准 ScreenSR 和 RealSR 上,VOSR 在感知质量上表现强劲,且单步模型仍具竞争力。与 ResShift、SinSR 等纯视觉方法相比,VOSR 在保持失真保真度的同时显著提升感知质量。
表 1 在 LSDIR、ScreenSR 和 RealSR 上的定量结果。方法按多步(ms)与单步(os)设置进行分组。T2I 和 VO 分别表示基于文本到图像的方法与纯视觉方法。最佳结果和第二佳结果分别以粗体红色和粗体蓝色高亮显示。
2. 定性比较
定性比较结果如图 2 所示,VOSR 在多步与单步设置下均能更清晰、保真地恢复精细结构(如桥梁塔缆)和字符细节,而对比方法存在过度平滑、恢复不全或字形错误等问题。该优势源于 VOSR 面向复原的设计:采用以低分辨率输入为锚定的密集视觉语义,而非 T2I 生成空间中的粗糙文本对齐语义,从而在保持结构保真度的同时增强细微局部细节。实验证明,纯视觉、面向复原的框架可在超分辨率的感知质量与保真度之间实现良好平衡。

图 2 在 RealDeg 的 Cf/0020.png 和 ScreenSR 的 010.png 上进行的多步(上图)与单步(下图)超分辨率视觉比较。
3. 复杂度比较
如表 2 所示,在固定输出分辨率 512×512 下,VOSR 在多步设置中显著快于基于 T2I 的方法,且参数量更少;在单步设置中,两个 VOSR 变体推理时间仅约 0.095 秒,快于 OSEDiff,与 PiSA-SR 相当且参数量更小。综合表明,VOSR 在模型大小与推理速度之间实现了良好权衡。
表 2 在 512×512 输入上的复杂度比较。运行时在 A100 GPU 上以批大小为 1、FP16 精度进行测量。

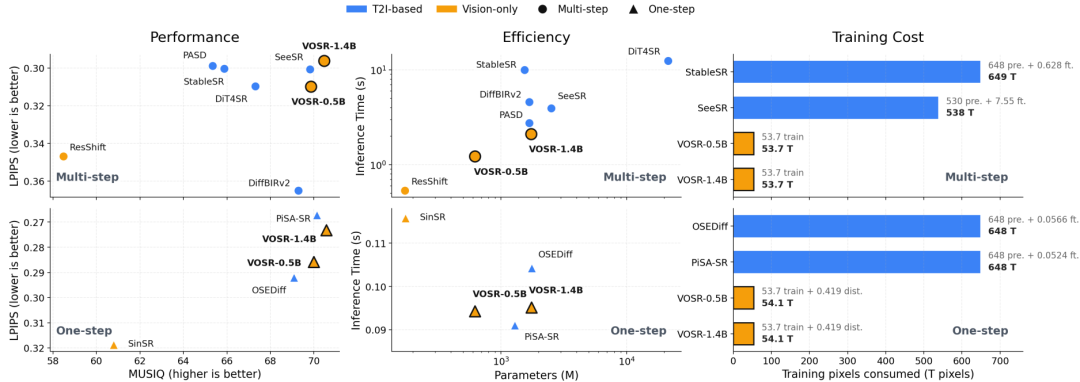
图 3 VOSR 与现有生成式超分辨率方法在性能、效率与训练成本方面的比较。蓝色与橙色分别表示基于T2I的方法与纯视觉方法,圆形与三角形分别表示多步模型与单步模型。
如图 3 所示,性能在 RealSR 上评估,效率在 512×512 分辨率下使用官方代码库测量。VOSR 在多步与单步设置下均能达到优于或媲美多数基于 T2I 的超分辨率方法的感知质量,同时显著优于先前的纯视觉方法。其多步变体的效率远高于现有基于 T2I 的方法,单步变体与近期单步 T2I 系统相当。以训练所消耗的总像素数衡量,VOSR 所需训练成本仅为代表性基于 T2I 的超分辨率方法的十分之一左右。

 关注公众号
关注公众号