2026-05-03 08:02:00
2026-05-03 08:02:00
智猩猩AI整理
编辑:林夕
大模型交互智能体逐步落地,超长对话成为主流场景。用户普遍期望模型能够记住数小时乃至更久的对话历史,理解事件间时序、因果与人物关联,并给出逻辑连贯、贴合上下文的回应。然而,现有记忆架构难以兼顾强时序与多跳推理能力与低计算开销,成为制约长期交互体验的核心瓶颈。
针对这一行业痛点,浙江大学和蚂蚁团队联合提出了一种面向大模型长时序行为的分层结构化记忆框架StructMem,以时序事件为单元,实现接近扁平记忆的效率与媲美图记忆的推理能力。相较于主流记忆方案Mem0,StructMem在LoCoMo基准上取得76.82%的最优性能,总Token消耗仅为Mem0的1/18,API调用次数仅为Mem0的1/11,幻觉率低至2.36%,远低于传统记忆方法。

论文标题:StructMem: Structured Memory for Long-Horizon Behavior in LLMs
论文链接:https://arxiv.org/pdf/2604.21748
01 方法
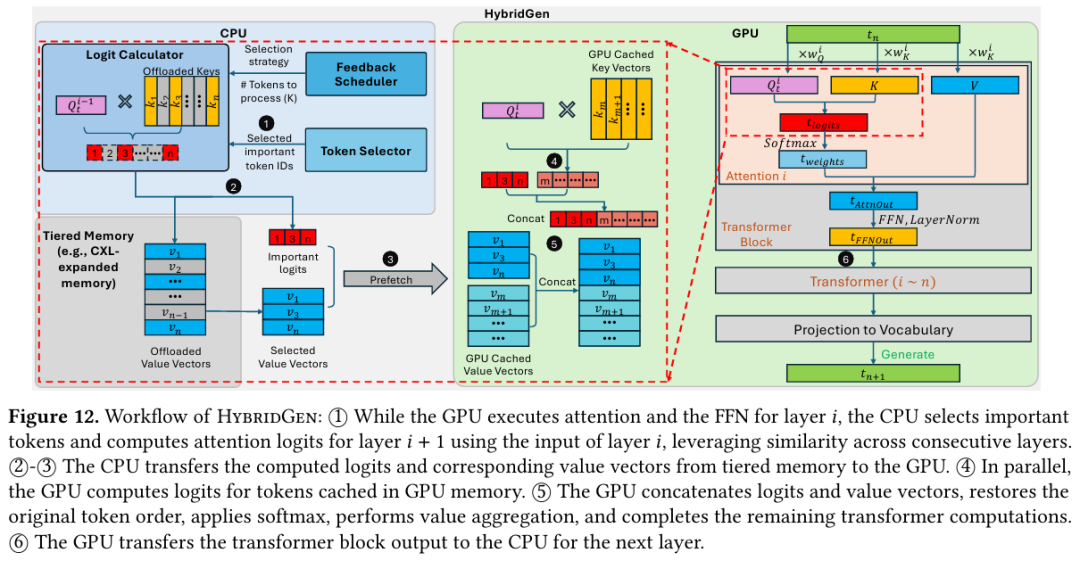
StructMem的整体流程包括:双视角提取、时序锚定存储、周期性跨事件合成、以及面向查询的检索回答,采用层次化记忆架构,通过事件级绑定与跨事件整合双层结构协同工作,既保留完整时序与关系上下文,又避免图结构的高昂构建开销,在长时序对话中实现推理能力与效率的统一。
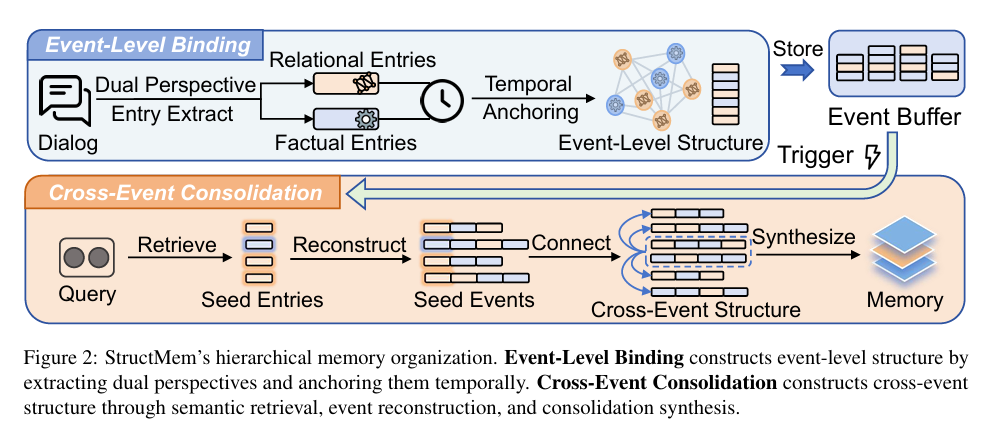
StructMem的分层记忆架构
(一)事件级绑定(Event-Level Binding)
事件级绑定是StructMem的基础模块,负责将每一轮对话转化为自包含、可还原、带结构的记忆单元,为后续跨事件推理提供可靠原子单元。它由两个关键操作构成:双视角提取与时序锚定。
1. 双视角提取:事实与关系同步捕获传统记忆要么只存事实,要么强行抽取三元组,而StructMem采用并行的双路提取,分别捕捉对话的两类核心信息:
事实视角:主要提炼事件本身相关信息,包含具体事件、状态、计划、观点、偏好等客观内容。
关系视角:主要挖掘人物间的互动逻辑,涵盖情感交流、立场支持、观点赞同、因果影响以及时序依赖等主观关联信息。
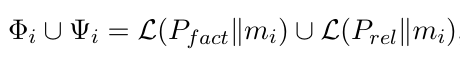
2. 时序锚定:StructMem将单轮对话提取的事实与关系,绑定到对应时间戳,形成含内容、关系、时间的完整事件单元,检索时可完整还原上下文,避免扁平记忆的信息割裂问题。
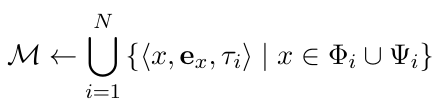
这种时序绑定让检索时可完整还原事件现场上下文,从根本上解决扁平记忆 “事实孤立、关系丢失” 的问题。
(二)跨事件整合(Cross-Event Consolidation)
跨事件整合是 StructMem 实现时序推理与多跳推理的核心,也是效率提升的关键设计。
系统不逐轮处理,而是按预设时间窗口累积事件,达到阈值后触发批量整合。首先将缓存条目按时序排序。
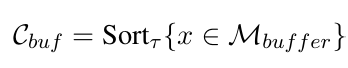
通过语义检索从历史记忆中获取相关种子条目,并依据时间戳还原出对应完整事件上下文,保证关系不丢失。
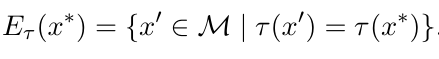
将缓冲事件与还原后的历史事件合并,构建跨事件关联结构。
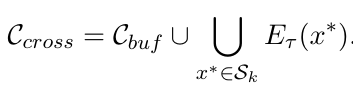
最后通过合成生成高层结构化知识。
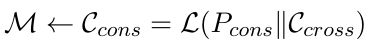
这种整合并非简单摘要,而是挖掘时序、因果、共现、人物关联等深层结构,使模型在不构建显式图谱的情况下,具备强大的跨轮次、跨时间理解能力。
02 实验结果分析
为了全面验证StructMem的效果与效率,研究团队在LoCoMo基准上开展了系统实验。LoCoMo是专门用于评测长对话记忆能力的数据集,包含10组超长对话,平均对话轮次高达588轮,涵盖单跳、多跳、时序推理、开放域问答四大任务,能够真实反映模型在长期交互中的记忆与推理水平。
对比方法包括OpenAI提出的RAG系统、FullContext、MiniRAG、LightRAG、LangMem、A-Mem、Mem0、MemoryOS、Mem0ᵍ、Zep、Memobase。这些方法分别覆盖直接上下文、检索增强、扁平无结构记忆与结构化图记忆等主流技术路线。所有实验均以gpt-4o-mini为基座模型,采用text-embedding-3-small生成向量嵌入表示。
(一)整体性能
主实验结果显示,StructMem以76.82分的综合得分取得最优性能,超过所有扁平记忆与图记忆方法,尤其在时序推理(81.62)与多跳推理上提升显著。
StructMem的总Token消耗(输入+输出)仅193.7万,API调用次数仅1056次,远低于对比方法。以Mem0ᵍ为例,其Token消耗高达3351.2万,API调用高达53514次,StructMem的开销分别约为其1/17和1/51。在运行时间上,StructMem也具备明显优势,比Mem0ᵍ快约3.3倍,比MemoryOS快约5.2倍。
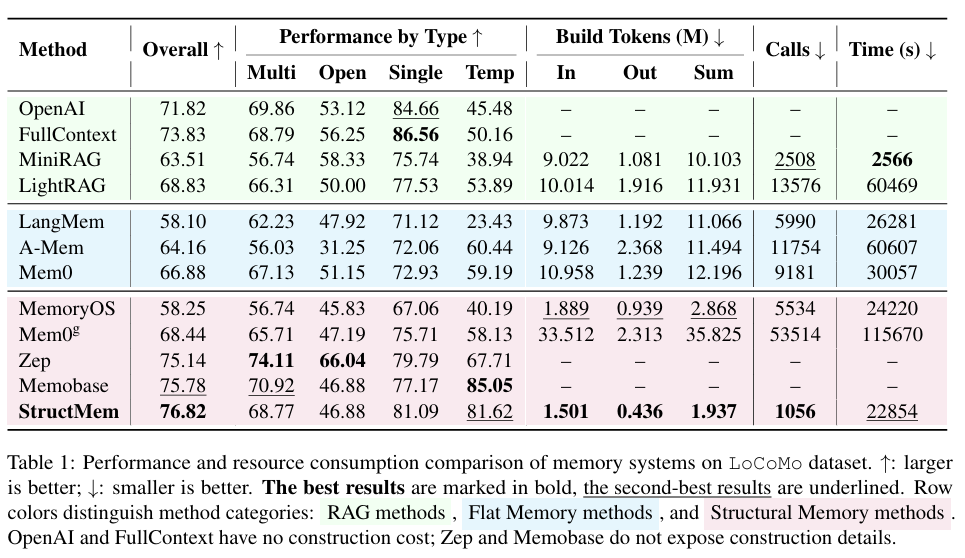
不同记忆系统在LoCoMo数据集上的性能与资源消耗对比
(二)范式对比
为进一步验证记忆范式与核心模块的价值,研究团队进行了范式对比与消融实验。
对比三类记忆范式可见,扁平记忆虽然资源消耗低,但因缺少事件间关联建模,难以支撑复杂推理;图记忆能够在部分单轮与开放域任务上提升效果,但时序推理表现下降,且计算开销巨大;而 StructMem 在所有任务类型上均实现稳定提升,兼具推理能力与运行效率。
消融实验证明,事件级绑定为模型提供了稳定的基础记忆能力,而跨事件融合则是推动多跳与时序推理大幅提升的关键,移除该模块后模型推理能力明显下降,充分说明分层结构的协同作用不可或缺。
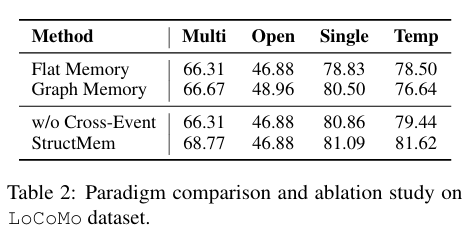
不同记忆范式与消融模型的性能对比
(三)效率分析
效率分析结果直观展现了三类方法的差异,图记忆随着对话轮次增加,Token消耗与运行时间急剧上升,原因是它需要逐轮执行实体抽取、关系抽取、双重去重,复杂度呈平方级增长,扁平记忆消耗平稳,但推理能力不足,StructMem依靠周期性批量融合,资源消耗呈线性平稳增长,即使在超长对话下依然保持高效。
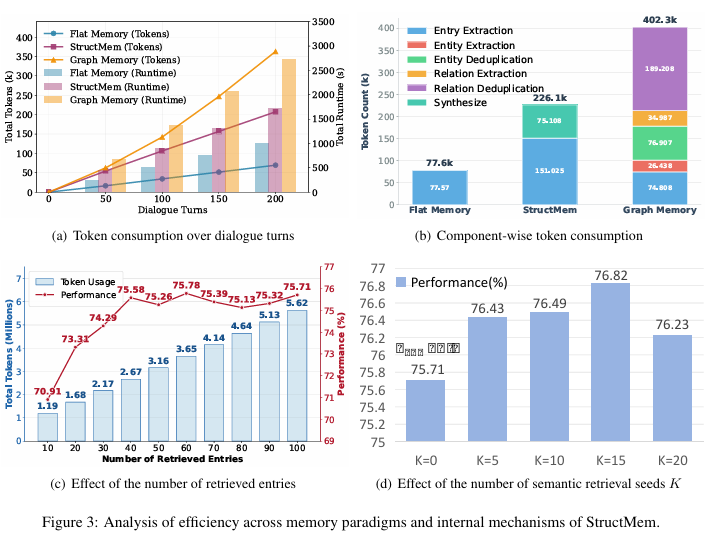
不同记忆范式的效率与内部机制分析
(四)保真度与鲁棒性验证
研究还通过多模型交叉验证与幻觉检测对 StructMem 进行了鲁棒性与保真度分析。在多个评测模型下的评分一致性达到 0.8341,证明其结果稳定可靠、不易产生虚假关联,既具备强大的推理能力,又能保证记忆内容高度忠实于原始对话,为构建高可信、低幻觉的长期交互智能体提供了关键支撑。
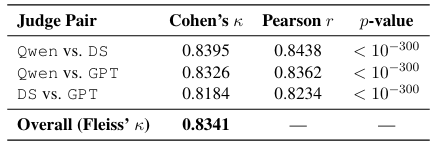
多模型评测一致性
StructMem 在双视角提取阶段的平均幻觉率仅 2.36%,在时序锚定的约束下,跨事件虚假关联被控制在极低水平。
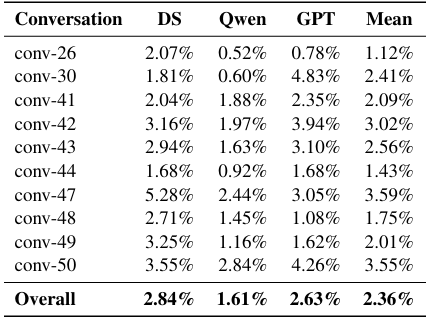
事件级抽取幻觉率
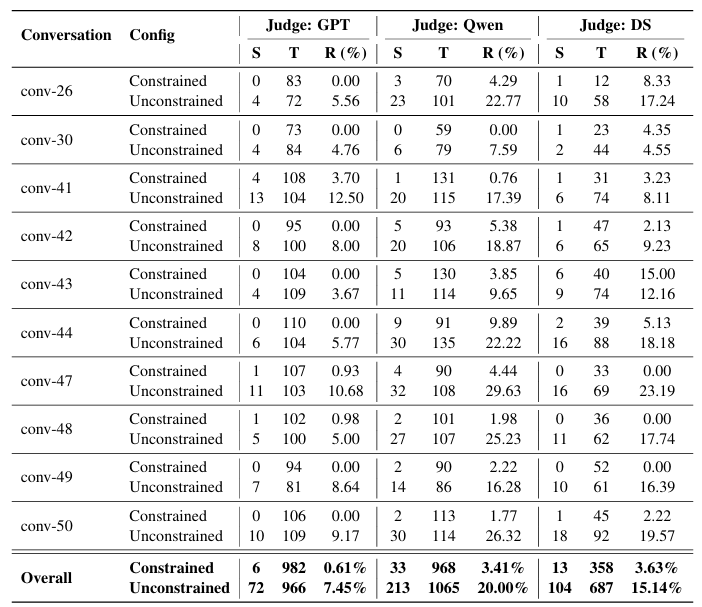
跨事件融合虚假关联统计
03 总结
针对大模型在超长对话场景中记忆结构与计算效率难以兼顾的痛点,研究团队提出StructMem 分层结构化记忆框架。该方法以事件为基本单元,通过双视角抽取与时序锚定构建单轮事件结构,并借助周期性跨事件融合实现长期关系建模,在保持强时序推理与多跳推理能力的同时,显著降低 Token与API开销。
在LoCoMo基准上的实验结果表明,StructMem在时序推理、多跳推理等任务上均取得最优性能,且资源消耗远低于传统图结构记忆方法,为长时序对话智能体的高效记忆架构设计提供了可行新思路。

 关注公众号
关注公众号