2026-04-30 13:56:00
2026-04-30 13:56:00
智猩猩AI整理
编辑:林夕
在大型语言模型(LLM)领域,随着GPT-4、Gemini 3Pro等模型将上下文长度推向数百万token的新高度,KV缓存的爆炸式增长。
现有优化方案存在显著局限:
基于KV 缓存剪枝的方法会丢弃部分历史 token,直接造成模型精度下降;
基于KV 缓存卸载的方法在CPU与GPU间频繁传输张量,数据传输开销极高;
传统架构仅依赖单一设备完成注意力计算,硬件资源利用率低、负载失衡严重;
面向 CXL 扩展内存的方案未充分考虑NUMA 延迟,内存访问效率难以保障。
在这样的背景下,如何在几乎不损失精度、不依赖超大显存、充分释放 CPU+GPU 算力前提下,把长上下文推理跑快,成为学界与工业界的共同难题。
针对以上痛点,加州大学默塞德分校与NVIDIA联合提出高效混合注意力计算框架HybridGen,通过三大原创技术,彻底破解长上下文LLM推理三大核心障碍。
HybridGen核心思路十分简洁清晰:让CPU与GPU基于各自本地内存做协同混合注意力计算,一边并行计算、一边动态均衡负载,同时用语义感知策略高效使用CXL扩展内存,最终在几乎不损失精度的前提下,把长上下文LLM推理速度提升1.41×–3.2×。

论文标题:HybridGen: Efficient LLM Generative Inference via CPU-GPUHybrid Computing
论文链接:https://arxiv.org/pdf/2604.18529
01 核心创新
(1)Attention Logits 并行化
传统注意力因Softmax全局依赖与层间串行执行,无法在多设备间并行。HybridGen首次将注意力计算解耦为两段独立流程:Attention Logits计算(Q・Kᵀ)与 Softmax+Value聚合。其中,Logits计算无全局依赖,可由CPU与GPU分别针对本地KV并行执行。
同时,论文观测到连续Transformer层的输入具有高度相似性,因此允许CPU使用当前层输入提前计算下一层Logits,与GPU当前层计算形成流水线重叠。GPU最终只需要合并结果、执行Softmax与后续FFN,功能完全等价于原生注意力,但延迟大幅降低。
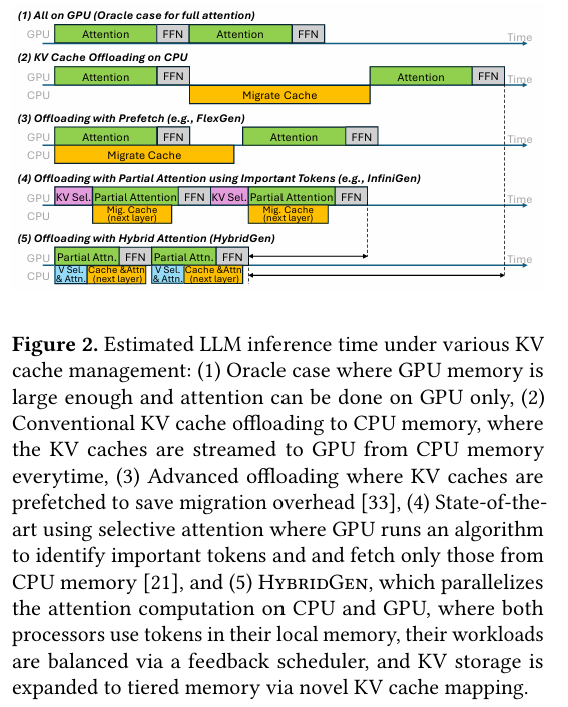
图1 在各种KV缓存管理下估计的LLM推断时间
如图1所示,相比全GPU、传统卸载、预取卸载、重要token筛选等方案,HybridGen的混合注意力模式在延迟上具备压倒性优势。
(2)反馈驱动调度器
随着上下文变长,大量KV被卸载到CPU,极易导致CPU成为瓶颈。HybridGen 提出闭环反馈调度机制,实时监测GPU计算延迟、CPU计算与传输延迟,动态调整CPU处理的token数量,并在精度约束下自动切换最优策略。
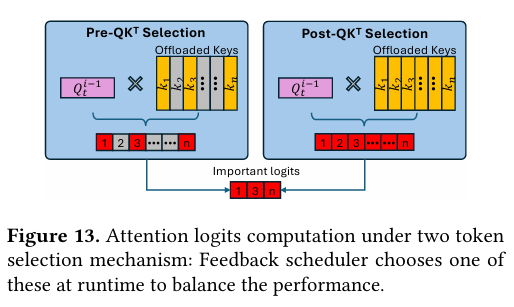
图2 两种词元选择机制下的注意力logits计算过程
如图2所示,系统可在Post‑QKᵀ(先算全量Logits再选重要token,精度优先)与Pre‑QKᵀ(先选token再计算,速度优先)之间智能切换,让CPU阶段始终隐藏在GPU流水线之后,实现资源利用率最大化。
(3)语义感知 KV 缓存映射
CXL内存容量大但延迟高,直接存放KV会显著拖慢推理。HybridGen提出按语义分置K/V的全新策略:K向量参与CPU高频Logits计算,放入CPU本地DRAM;V向量不被CPU访问,直接存放于CXL内存,通过DMA直传GPU。这一设计从根源上将CXL延迟排除在关键路径之外,实现大容量内存高效扩展,且无需在线热数据监测、无需硬件修改。
图3展示了HybridGen的完整架构,三大核心模块协同构成端到端混合计算体系。
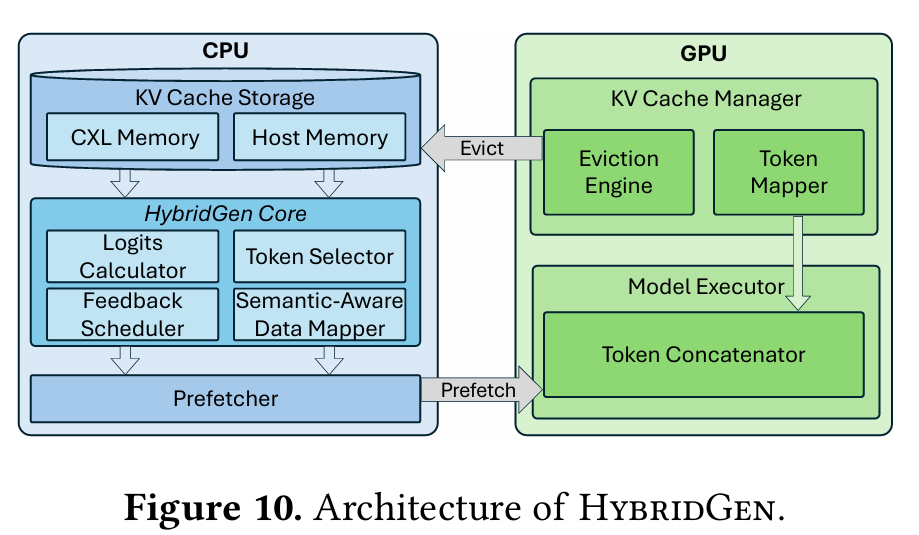
图3 HybridGen架构
02 工作流程
在生成阶段,HybridGen采用CPU-GPU流水线协同模式,GPU在执行第i层Transformer的注意力与FFN计算的同时,CPU会依据反馈调度结果筛选重要token,并利用层间输入相似性提前计算第i+1层的Attention Logits,实现计算深度重叠;
随后CPU仅将筛选后的logits与对应value向量传输至GPU,GPU在完成本地token的logits计算后,对CPU与本地两路结果进行拼接和位置还原,再执行Softmax与Value聚合,完成当前层剩余计算并将输出传递给CPU,以此循环迭代直至文本生成结束,全程无阻塞、数据传输量低。
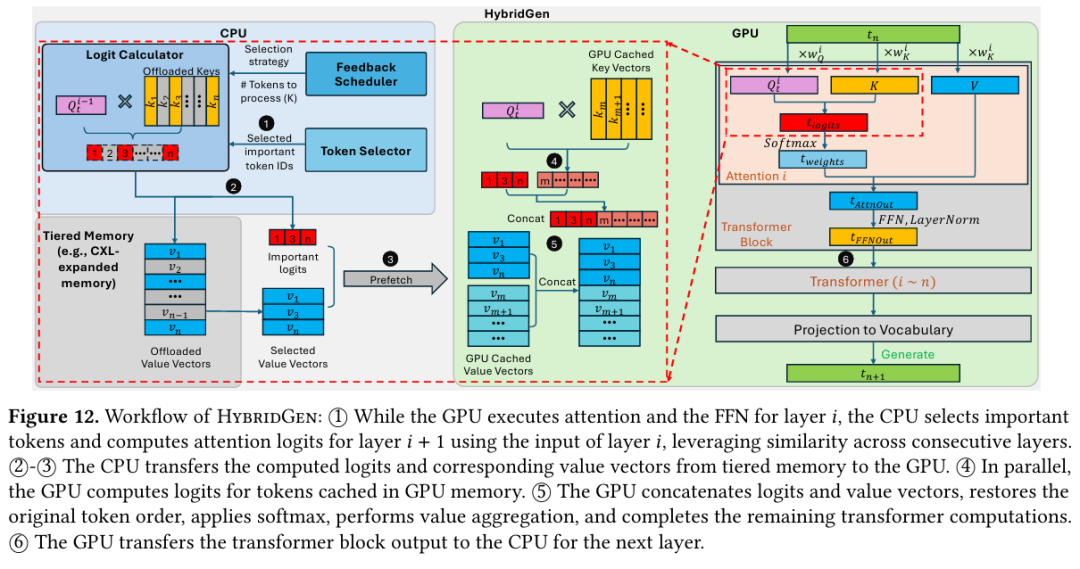
图4 HybridGen的工作流程
03 实验结果分析
实验在A100、H100 NVL、RTX 5090三类GPU平台展开,覆盖OPT、Llama-3.1、Qwen2.5等11种不同规模模型,对比FlexGen、MoE-Lightning、Keyformer、H2O、StreamingLLM、InfiniGen共6种SOTA方案,从速度、扩展性、精度、鲁棒性四个维度全面验证。
(1)全模型性能:统一领先,提速1.41×~3.2×
图5展示了不同模型下端到端推理延迟(以FlexGen为基线归一化)。可以看到,HybridGen在所有参数量级(1.3B–14B)上均取得最低延迟。相比最优Pre-QKᵀ方案InfiniGen平均提速1.41×,相比最优Post-QKᵀ方案Keyformer平均提速1.86×,相比传统卸载方案最高提速3.2×。
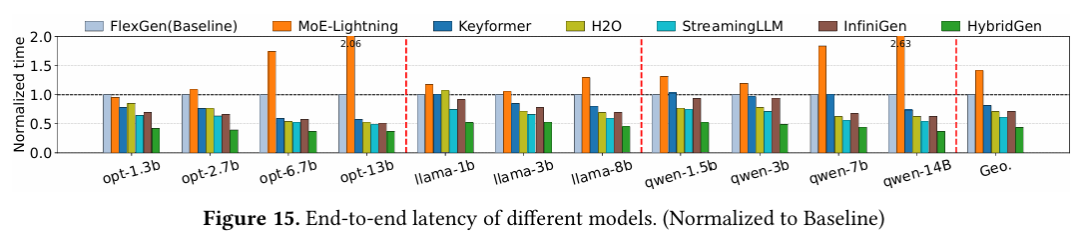
图5 不同模型的端到端推理延迟(以基线模型为归一化基准)
(2) 长上下文性能:越长越稳,优势持续放大
图6展示Qwen2.5-7B与Llama-3.1-8B在2K–32K token下的性能。随着序列长度增加,传统方法延迟急剧上升,而HybridGen增长最平缓。在32K超长上下文下,Qwen2.5-7B最高提速2.66×,Llama-3.1-8B最高提速3.18×。结果说明:HybridGen的动态负载均衡与流水线并行,完美适配超长上下文场景。
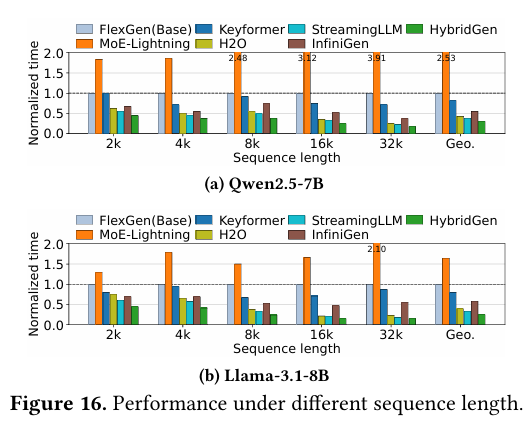
图6 不同序列长度下的模型性能
(3) 批尺寸性能:越大越强,高吞吐更具优势
图7在OPT-13B上测试不同batch size的表现。随着batchsize增大,HybridGen加速比持续提升,最高可达1.87×。原因在于:大batch进一步加剧传统方法的GPU压力,而HybridGen可通过CPU分摊计算、隐藏延迟,硬件利用率更高。
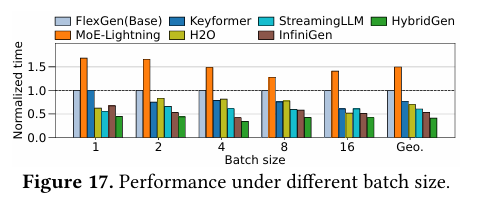
图7 不同批次大小下的性能表现
(4)语义感知KV映射效果:CXL扩展不掉速,模型越大收益越高
图8对比了HybridGen语义感知映射与常规交错页映射的性能加速比。从结果可以清晰看到,语义感知映射在OPT-1.3B、2.7B、6.7B、13B所有模型上均持续领先,平均加速比达到1.1×及以上,并且随着模型规模增大、KV缓存容量提升,加速效果愈加明显。
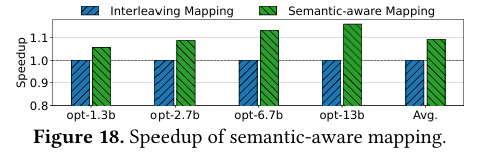
图8 语义感知映射的加速效果
(5)跨GPU平台通用性:跨代兼容,性能稳定增益
图9对比A100与H100平台性能。HybridGen在两代旗舰GPU上均显著超越基线,H100上收益更高。
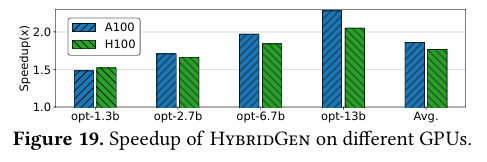
图9 跨 GPU 平台(A100/H100)性能加速效果
(6)精度保持:几乎无损,远超剪枝类方法
图10在PIQA、OpenBookQA、COPA、RTE四项任务测试中,HybridGen相对全注意力精度损失仅0.02,几乎无损。而StreamingLLM、InfiniGen等静态剪枝方法在长距离依赖任务上明显下降。
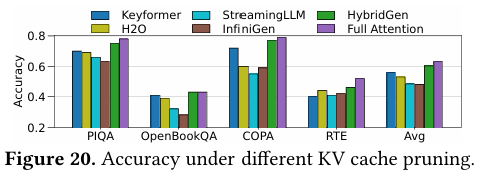
图10 不同 KV 缓存剪枝策略下的模型准确率
(7)消融实验:反馈调度是核心增益
图11、图12对反馈调度器做消融。固定K值或单一选择策略(固定Pre-QKT或固定Post-QKT),都会出现性能下降或精度明显降低。只有启用完整反馈调度(动态K+策略切换),才能在速度几乎不变的前提下实现高精度。
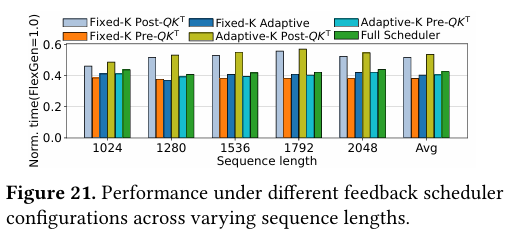
图11 不同序列长度下,各类反馈调度器配置的性能表现
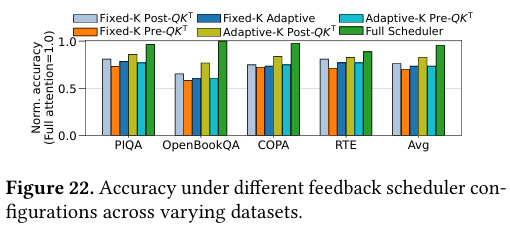
图12 不同数据集下,各类反馈调度器配置的模型准确率
04 总结
HybridGen通过CPU-GPU混合注意力机制,用一套轻量、通用、可直接部署的软件架构,系统性解决超长上下文LLM推理的显存瓶颈、算力失衡、内存延迟三大难题。
无需修改硬件、可无缝接入vLLM、SGLang等主流推理框架,保持精度的同时实现大幅加速,为百万token级长上下文推理提供了可落地、可扩展的工业级方案。

 关注公众号
关注公众号