2026-05-06 19:41:00
2026-05-06 19:41:00
智猩猩AI整理
编辑:没方
在大模型辅助编程日益普及的今天,Token 成本已成为开发者日常最头疼的问题之一。尤其是 Claude 这类擅长处理超长上下文的模型,虽然在代码理解、仓库级任务、多文件重构等场景表现出色,但随着代码库越来越大、上下文长度不断增加,Token 消耗急剧上升,不仅大幅推高使用成本,还会导致响应变慢、大量无关代码干扰模型判断。
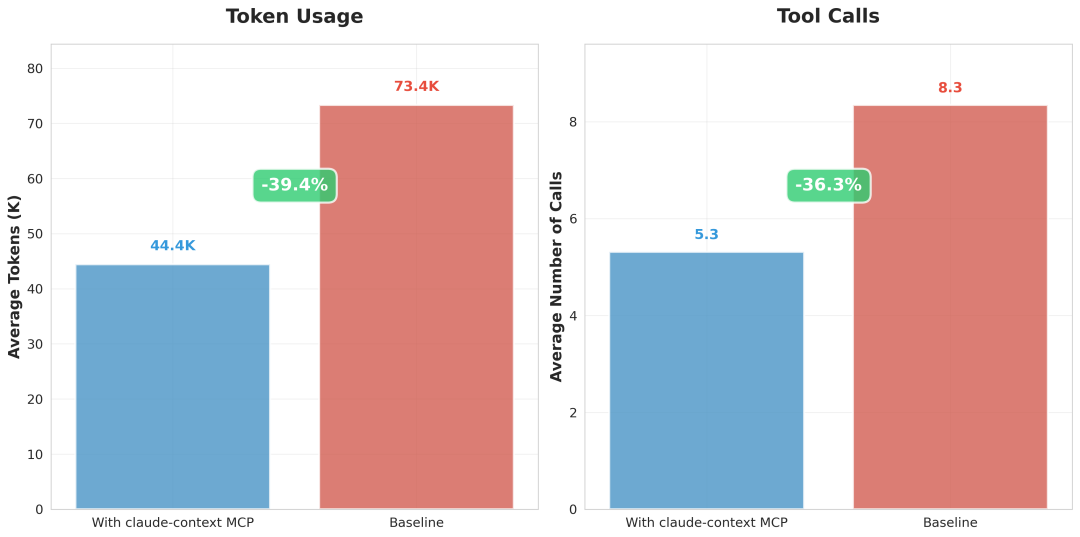
面对这一痛点,Zilliz 团队开源的 Claude Context 项目应运而生。它基于 AST 智能代码分块、混合搜索(BM25 + 稠密向量)、增量索引等技术,专为 AI 编程智能体设计。开发团队实测该项目可将 token 消耗有效降低约40%,同时提升复杂任务的解决质量。目前,该项目在 github 上已收获 10.8k stars。
项目链接:https://github.com/zilliztech/claude-context
01 项目介绍
传统 grep 式检索依赖精确关键词匹配,容易遗漏语义相近但命名不同的代码,而全目录注入又会让token窗口迅速爆炸。
Claude Context巧妙地避开了这两条死胡同。
它首先通过抽象语法树(AST)对代码进行智能分块,能够理解函数、类、模块之间的结构关系,而非简单按行切割。这种结构感知的分块方式让每个代码片段携带了更丰富的语义信息。
随后,Claude Context 利用向量嵌入模型(支持 OpenAI、VoyageAI、Ollama、Gemini 等服务商)将这些片段转化为高维向量,并存储到 Milvus 或 Zilliz Cloud 向量数据库中。同时结合 BM25 关键词检索,形成了高效的混合代码搜索机制。
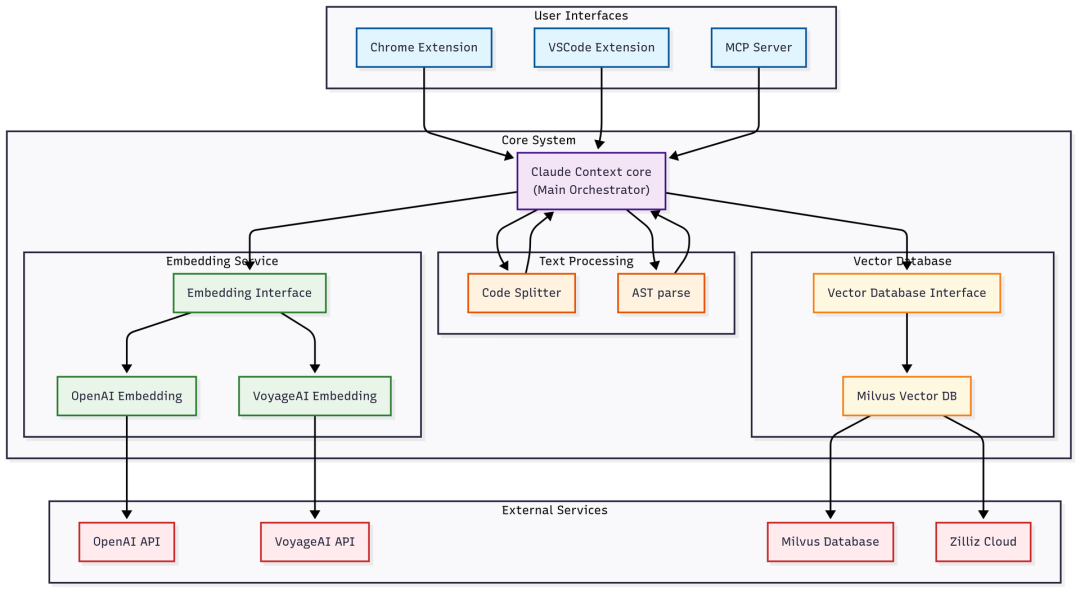
当AI智能体提出自然语言查询时, Claude Context 能精准检索出语义匹配的代码,而非仅靠字符串匹配。它无需多次往返探索,直接把最相关、最精炼的片段注入上下文。这不仅大幅节省token,还让AI的推理更加准确、完整。
该项目还特别注重实用性和效率。采用 Merkle 树实现增量索引,只有修改过的文件才会重新处理,大幅降低重复计算开销。对于百万行级的大型代码库,它也能轻松应对,展现出极强的可扩展性。
02 使用方法

(1)环境要求
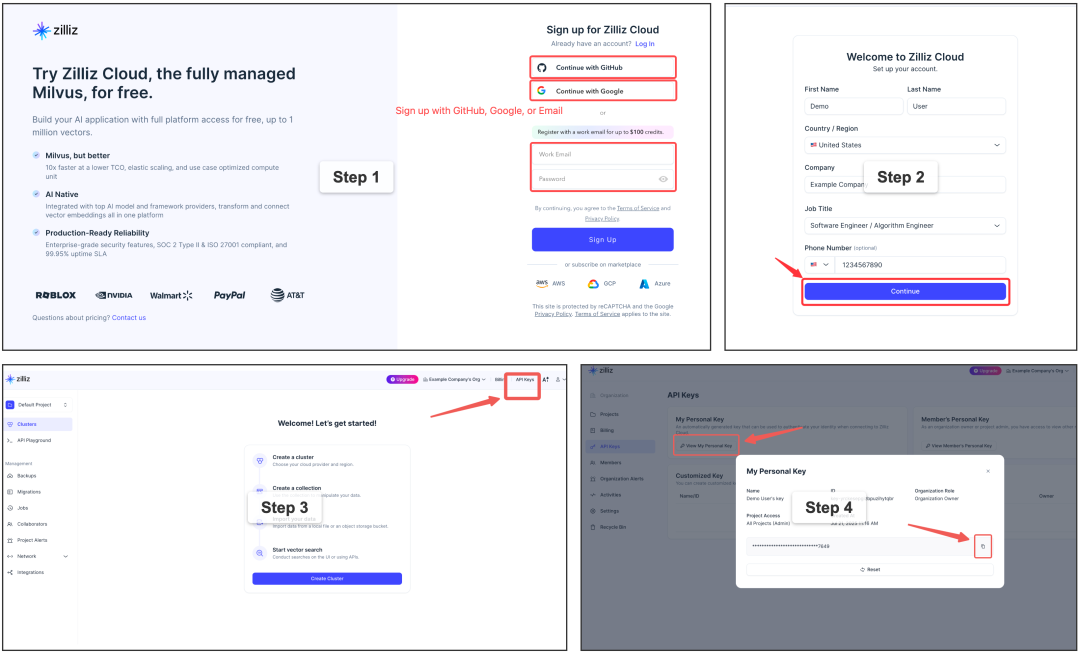
Node.js >= 20.0.0,Claude Context 需要准备一个 Zilliz Cloud 免费向量数据库账号(获取API Key)和OpenAI API Key(用于embedding)。
(2)在 Claude Code 中配置
对于Claude Code用户,最简单的方式是通过命令行添加MCP服务器:
claude mcp add claude-context \ -e OPENAI_API_KEY=sk-your-openai-api-key \ -e MILVUS_ADDRESS=your-zilliz-cloud-public-endpoint \ -e MILVUS_TOKEN=your-zilliz-cloud-api-key \ -- npx @zilliz/claude-context-mcp@latest(3)在 Codex 中配置
①创建或编辑 ~/.codex/config.toml 文件;
②添加以下配置:
# 重要提示:必须是 `mcp_servers`,而不是 `mcpServers`。[mcp_servers.claude-context]command = "npx"args = ["@zilliz/claude-context-mcp@latest"]env = { "OPENAI_API_KEY" = "your-openai-api-key", "MILVUS_TOKEN" = "your-zilliz-cloud-api-key" }# 可选:覆盖默认的 10 秒启动超时时间startup_timeout_ms = 20000③保存文件并重启以应用更改。
(4)在Qwen Code中配置
创建或编辑 ~/.qwen/settings.json 文件并添加以下配置:
{ "mcpServers": { "claude-context": { "command": "npx", "args": ["@zilliz/claude-context-mcp@latest"], "env": { "OPENAI_API_KEY": "your-openai-api-key", "MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint", "MILVUS_TOKEN": "your-zilliz-cloud-api-key" } } }}Gemini CLI、Cursor、Void、Claude Desktop、Windsurf、VS Code、Cherry Studio、Cline、Augment、Roo Code、Zencoder、LangChain/LangGraph 以及其他 MCP 客户端也有对应的配置文件方式,官方文档提供了详细模板。
请参考:
https://github.com/zilliztech/claude-context#configure-mcp-for-claude-code
03 总结
从行业视角看,未来大模型的竞争早已不只是 “上下文能撑多长”,而是 “单位 Token 能产出多少价值”。claude-context 给出的动态上下文管理,将成为大模型工程化的关键方向。它不仅能降低企业算力与调用成本,更能让超长上下文能力下沉到更多中小团队与个人开发者的项目中,打破 “长文本 = 高成本” 的固有壁垒。

 关注公众号
关注公众号