2026-05-09 17:44:00
2026-05-09 17:44:00
智猩猩AI整理
编辑:没方
如果说 OpenClaw 点燃了2026年开源Agent的第一波热潮,那么紧随其后最受关注的项目,毫无疑问就是Hermes Agent《狂揽28.4k Star!OpenClaw最新平替Hermes Agent开源,从经验中自主生成skill并持续优化》。
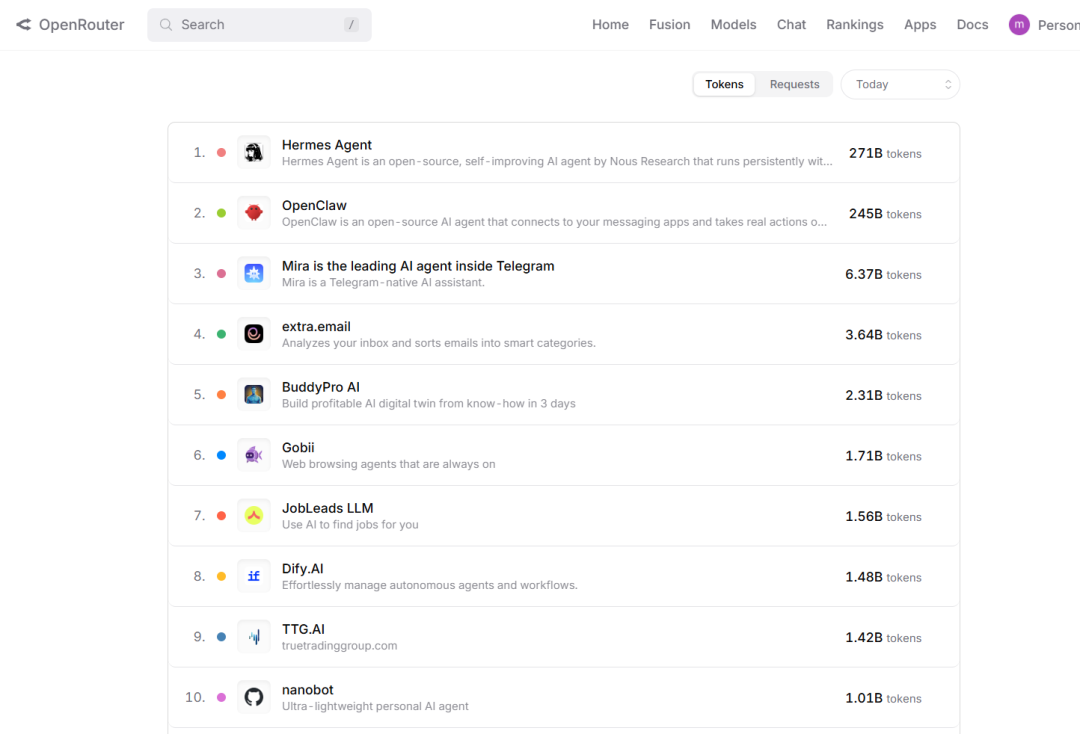
OpenRouter上Personal Agent排行榜链接:
https://openrouter.ai/apps/category/productivity/personal-agent
大家看它看的不是工具多,而是那个真正戳中人的点:Agent 能从过往任务里自己沉淀 Skill,越用越聪明。
2026 年的 Agent 赛道已经达成共识——自进化,才是下一波分水岭。谁做不到,谁就还停留在"花里胡哨的自动化脚本"阶段。
就在这个节骨眼上,一个叫 GenericAgent(GA) 的国产项目,把自进化 Agent 的实现成本直接打到了地板价。
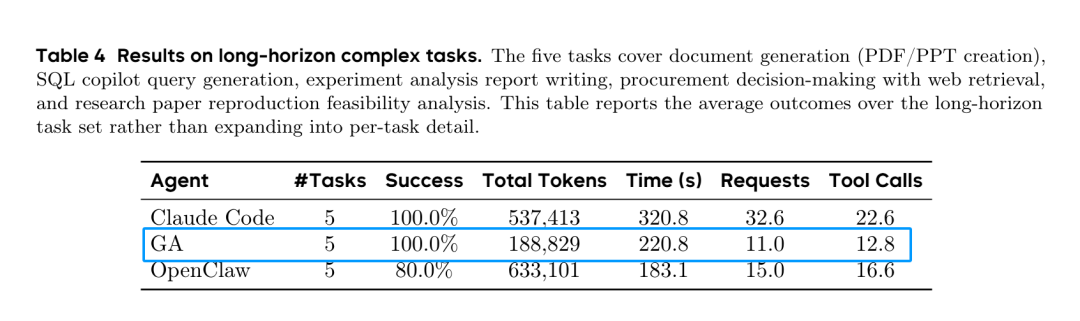
它的核心代码只有3300 行,OpenClaw 是它的 160 倍(约 53 万行,整整两个数量级),Agent Loop 仅 92 行,它的上下文窗口始终控制在 <30K tokens。
同样任务下,GA 总 Token 消耗仅 188,829——相当于 Claude Code 的 35.1%、OpenClaw 的 29.8%。
目前,该项目在github上已收获10.2k stars。
项目链接:https://github.com/lsdefine/GenericAgent
论文链接:https://arxiv.org/pdf/2604.17091
01 Hermes 点燃自进化 Agent,GA 则把战场拉到上下文信息密度
大部分人看 Agent,看的是参数规模和工具数量——好像买显卡,越大越强。
GA 的作者盯着另一件事看——上下文信息密度(Context Information Density):
Agent 真正的性能,不取决于上下文能塞多少字,而取决于在有限 Token 预算里,能装进多少真正有用的信息。
简单说就是,塞得多 ≠ 干得好。就像行李箱塞满不代表你旅行装备齐了,可能只是你没学会打包。
这是 GA 论文的第一性原理,也是整套系统的出发点。
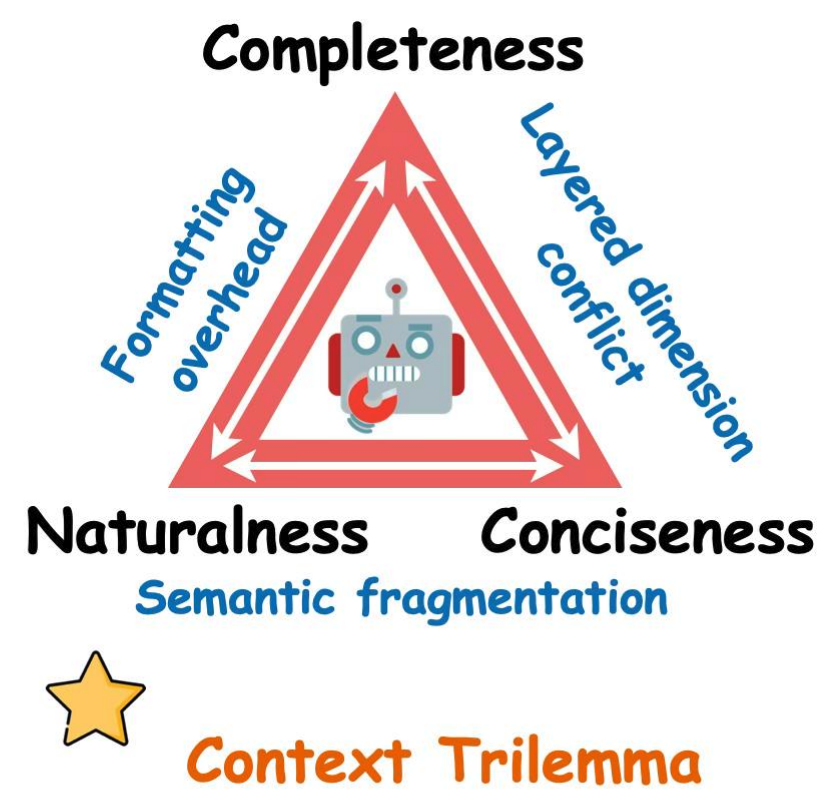
(1)长上下文的三重套娃陷阱
LLM 在长上下文里,会同时踩三个坑,而且这三个坑还会互相叠buff:
陷阱 1:Lost-in-the-Middle(关键证据迷失在中间)
模型就像看小说——开头和结尾记得特别牢,中间那一大段,基本当空气处理。
陷阱 2:注意力稀释(Attention Dilution)
上下文里无关内容越多,注意力被摊得越稀。无关信息不是"中性"的——它会主动抢戏,把模型的注意力从关键证据上撕走。
陷阱 3:名义窗口 ≫ 有效窗口
一个标称 128K 的模型,实际能稳定推理的有效窗口可能只有几万 token。剩下的,全是"我可以,但我不想"的区域。
三者一叠加,死循环就来了——上下文越长,推理越差;为了补偿推理差,又塞更多上下文。这大概就是 Agent 界的"越努力越焦虑"。
(2)把信息密度当成唯一 KPI
GA 不做"更大",它做"更干净"。围绕上下文信息密度最大化,GA 设置了四道闸口,每一道都是拦噪音的安检员:
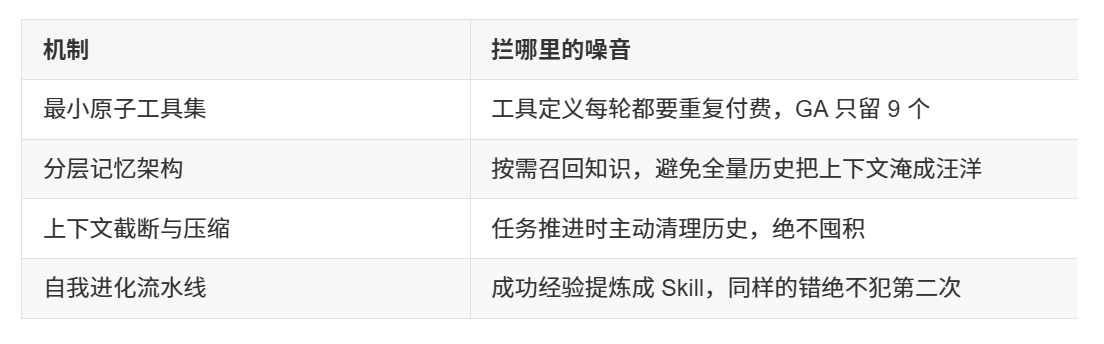
这四道闸口合起来,就是 GA 的全部秘密武器。
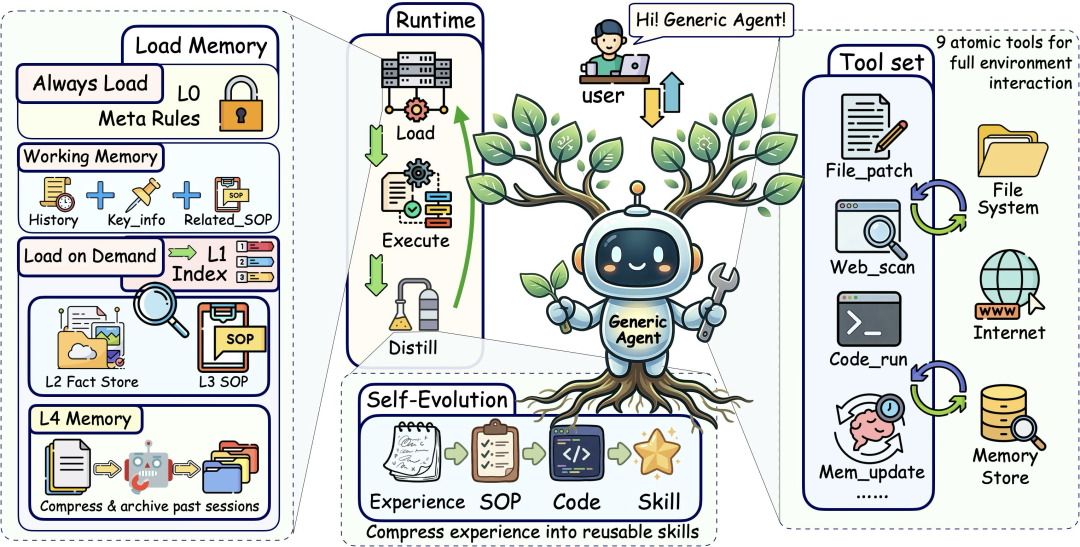
02 不要堆工具,要会组合:GA用9个原子工具撑起完整Agent能力
Claude Code 有 53 个工具,OpenClaw 有 18 个工具,GA 只有 9 个工具。
看起来是不是 GA 特别不够用?
再来看真实的调用分布,画风立马不对了:
| Agent 系统 | 工具总数 | Top 3 工具调用占比 |
| Claude Code | 53 | AgentTool 50.4% / WebFetchTool 22.1% / FileReadTool 10.6% |
| OpenClaw | 18 | browser 32.5% / exec 20.5% / web_fetch 15.7% |
| GA | 9 | code_run 34.4% / file_read 31.2% / update_working_checkpoint 17.2% |
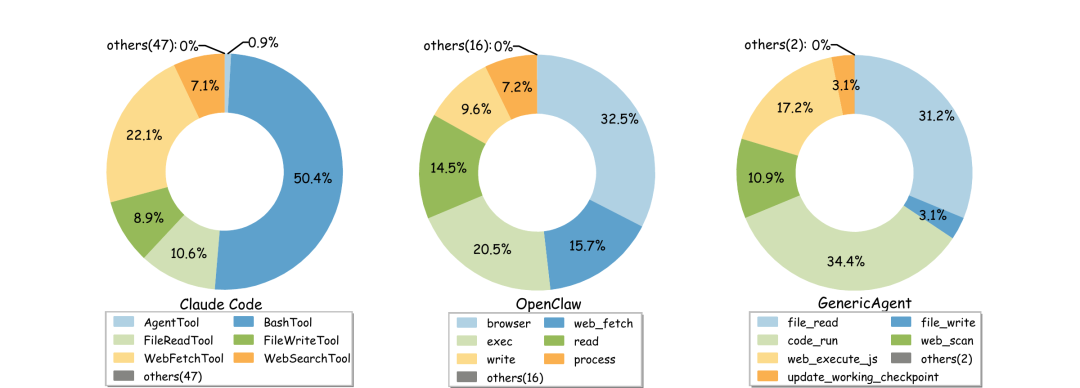
Claude Code 的 53 个工具,80% 以上的调用只落在 3 个工具上——剩下 47 个工具常年摸鱼,但每一轮推理都要占据上下文。
所以 GA 敢只留 9 个,不是因为它勇,是因为它看透了。
它用两把尺子来筛选工具:
原子性(Atomicity):每个工具都是不可再分的原始能力,职责单一,工具之间零重叠——没有"都能干但都不专精"的万金油。
组合泛化(Compositional Generalization):复杂行为通过原子工具的组合产生,而不是靠新增专用工具。

这 9 个工具覆盖了 Agent 的完整能力环:状态观测 → 动作执行 → 上下文保持 → 干预请求。
注意一个反常识的细节:GA 没有专门的"搜索"工具、没有"浏览器截图"工具、没有"HTTP 请求"工具。
因为这些能力全部由 code_run + Python 生态兜底——Python 本身就是最庞大、最活跃的工具集合,pip 一下啥都有。
03 分层记忆:别人还在用 22,821 token 打招呼,GA 只用了 2,298
场景设想一下:装好 20 个 Skill 之后,你对四个 Agent 说一句 Hello,它们各自的完整提示词长度是多少?
论文里给了一张让人当场破防的图:
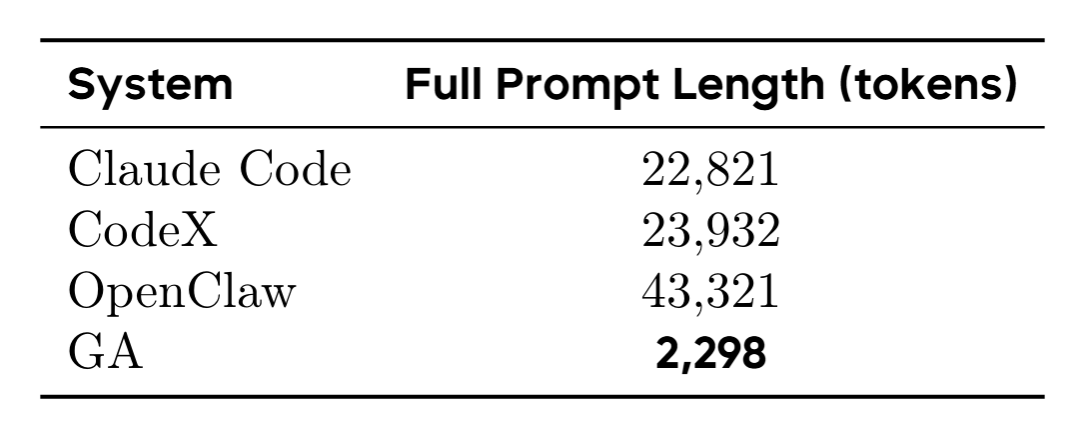
GA 的提示词长度,是 Claude Code 的 10%,OpenClaw 的 5%。OpenClaw 打一句招呼的 token 量,够 GA 跑完一小段实际任务了。
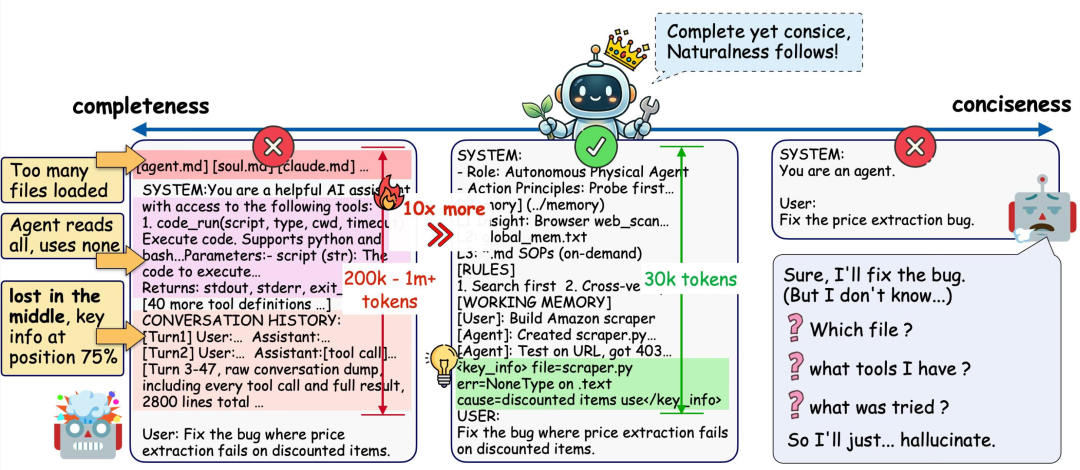
做到这件事的,是 GA 的四层分层记忆架构(L0 → L4):
| 层级 | 角色 | 内容 |
| L0 Meta Rules | 元规则 | Agent 的基础行为规则与系统约束 |
| L1 Insight Index | 记忆索引 | 极简路由层,告诉 Agent哪里有哪些知识 |
| L2 Global Facts | 全局事实 | 长期稳定、验证过的事实(机器环境、账号配置…) |
| L3 Skills / SOPs | 任务流程 | 可复用的工作流:前置条件、关键步骤、常见故障、调试恢复 |
| L4 Session Archive | 会话归档 | 已完成任务的提炼记录,用于长程召回 |
每一轮对话,GA 只默认加载 L0(最小 Meta 规则)+ L1(目录级索引),其它层级按需用 file_read 拉进来。相当于进图书馆不是把所有书搬回家,而是先看目录——需要哪本再抽哪本。
路由不是硬编码的流水线,而是模型根据任务自主选择要不要读。不相关的知识永远不进入活跃上下文。
光分层还不够。如果任何东西都能进长期记忆,错经验、过期配置、一次性调试信息迟早把记忆搞成一锅大杂烩。
所以 GA 给 L2 / L3 加了一条准入铁律:
No Execution, No Memory ——不是应该这样做,而是这样做了,而且成功了,才配进记忆。
瞬态状态、一次性事件、未验证假设,一律被门卫拦在外面。
GA 论文在 SOP-Bench 的 dangerous goods 子集上跑了一组记忆消融实验(Memory Ablation),直接拷问记忆密度到底重不重要。
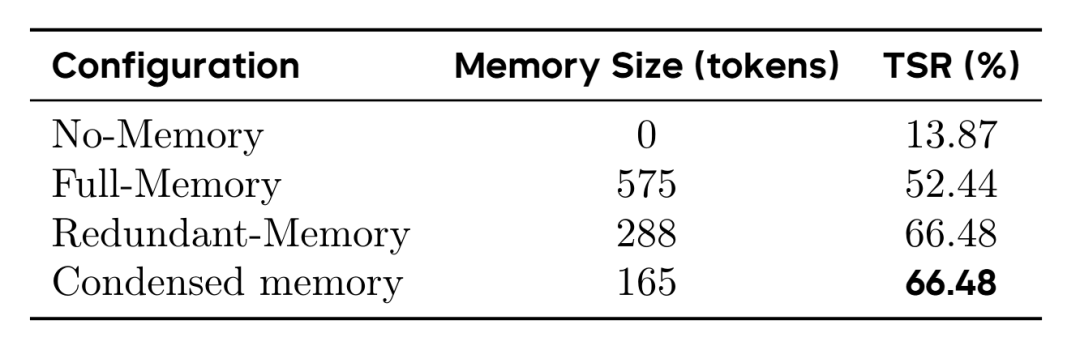
165 token 达到了 575 token 的 1.27 倍成功率。
让我们算一下反差:用三分之一的"墨水",干出一倍多的活。这就是整个 Agent 设计哲学的硬核注脚——浓缩、行动导向的记忆,比更多的记忆有效得多。
少即是多,在 Agent 这里是实打实的数据,不是玄学。
04 约束,才是Agent能力涌现的真正源泉
GA 最让人拍案叫绝的,不是上面那些"设计得很巧妙"的机制,而是下面这种"根本就没设计"的能力:
| 功能 | 传统框架的做法 | GA 的做法 |
| 子 Agent 分发 | 子 Agent 管理器(SubAgent Manager) | code_run 起一个新的 GA 进程 |
| 定时任务 | 调度守护进程(Scheduler Daemon) | 反射模式 + 一个轮询脚本 |
| 看门狗监控 | 专用监控层 | 反射模式 + 条件脚本 |
| 多 Agent 协作 | 编排层(Orchestration Layer) | 文件协议做跨进程通信 |
GA 没有子 Agent 管理器、没有调度守护进程、没有事件总线、没有编排层——这些听起来很高大上的词,在 GA 里全部不存在。
那这些"高级功能"从哪冒出来的?它们从两个基础原语里直接涌现出来:
可调用 CLI 入口点:Agent 就是一个命令行程序,父 GA 通过
code_run启动子 GA——自己调自己,亲爹当亲儿子使文件协议:跨进程通信只靠目录约定——
input.txt送任务、output.txt收结果、reply.txt续对话、inject_message.txt运行时干预。比 RPC 简单,比 MQ 靠谱,还没有中间商赚差价。
这种涌现不是物理意义上的涌现,而是工程意义上的涌现——当基础组件足够通用、组合成本足够廉价时,设计者没预先规划的功能,能在需要的时候被轻松实现出来。
给 Agent 的选项越少,它反而越能长出花来。
05 使用方法
环境要求:Python 3.10+
(1)下载并安装GenericAgent项目
git clone https://github.com/lsdefine/GenericAgent.gitcd GenericAgent(2)配置 API Key
把项目文件中的 mykey_template.py 重命名为 mykey.py。进入 mykey.py 配置 API Key。
oai_config = { 'apikey':'Your-API-Key', # 此处填写API Key 'apibase':'http://api.example.com:3001', # 此处填写 base url,openai的base url后自动接"/v1/completion" 'model':"openai/gpt-5.1" # 此处填写模型名称,注意名称要与供应商提供的名称完全一致(大小写等)}(3)自动配置其他依赖
cd GenericAgentpython3 agentmain.py在命令行输入:“请查看你的代码,安装所有用的上的python依赖”请复制这句话到终端,GenericAgent会自动安装剩下的相关依赖。
(4)启动
python launch.pyw #一键启动 【或 python3 launch.pyw】完整步骤请参考:
https://my.feishu.cn/wiki/CGrDw0T76iNFuskmwxdcWrpinPb
系统学习请参考:
https://datawhalechina.github.io/hello-generic-agent/
06 Hermes 之后,Agent 的分水岭到底在哪
Hermes 点燃了自进化 Agent 的热度,但它留下一个问题——怎么把这件事做便宜、做稳定、做本地可部署?
当其他框架在功能内置、模块堆叠上继续加码时,GenericAgent 押注了另外一条路径 ——用最小原语 + 最大组合空间,让能力从约束中涌现。
两条路谁赢,现在下结论还太早。但如果你正在做 Agent、被 Token 账单炸过钱包、被长上下文的三重陷阱毒打过心态,那 GA 这套范式真的值得抄进下一版架构——或者至少可以重新思考一遍"是不是工具堆太多了"。

 关注公众号
关注公众号