







 1970-01-01 08:00:00
1970-01-01 08:00:00
大家好,我是 Jack。
今天继续给大家推荐一些让人“心动”的开源项目。
point-e
OpenAI 最近真的是杀疯了,真是一家大力出奇迹的公司。
先有 CLIP、再有 Dalle2,然后又搞了一个大火的 ChatGPT。
可谓是在多模态领域、图像生成领域、文本对话领域大杀特杀。
现在,他们又把“魔爪”伸向了 3D 模型生成领域!
我们看一下效果:

简单概述就是:
根据本文,生成 3D 模型。

并且运行速度也很快,单个 GPU,只需要 1-2 分钟。
你可别笑话这 3D 模型,颗粒感明显,后续提高精度了,有可能又是一波大杀特杀。
要知道,最原始的扩散模型生成 2D 图像,效果也是不太好。但自从 DDPM 发力后,基于本文的2D图像生成,开始迅猛发展,两年的时间,发展到了如今的 2D 高清图片生成。
像我之前分享的 AI 作画,就是基于扩散模型 LDM 做的。

从最初的难用、甚至不可用,到现在的火爆,只用了几年的时间。
想象一下:输入各种风格、主题、氛围的关键词,AI 就会生成符合要求的 3D 模型。
完善好后,这无疑又是动画、游戏、VR/AR等从业人员的一大利器。
项目刚刚开源,“新鲜热乎”:
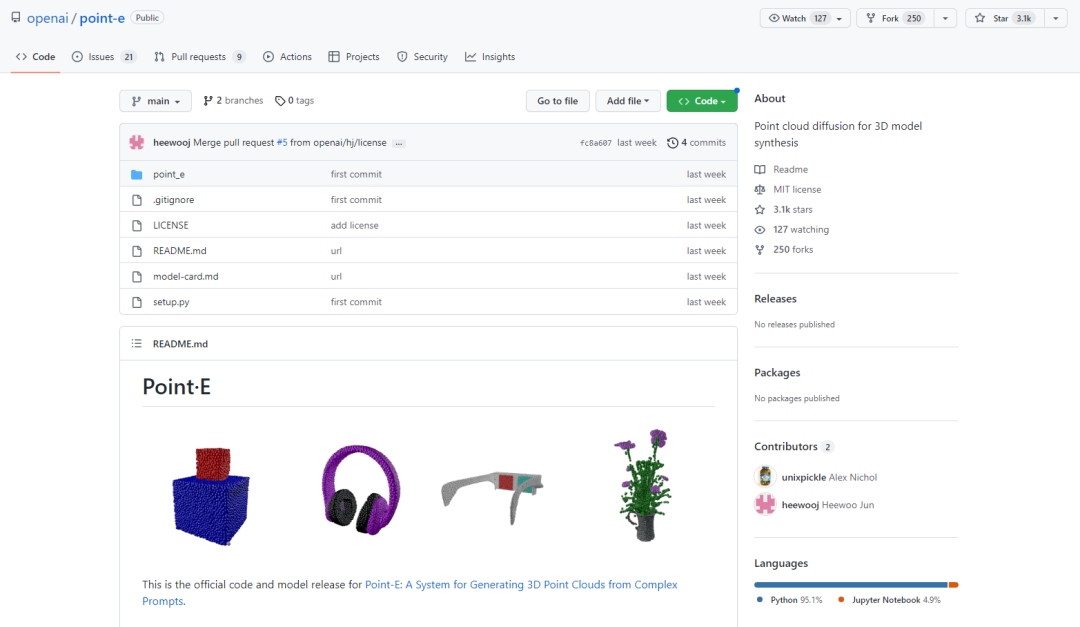
项目地址:
https://github.com/openai/point-e
使用方法也很简单,首先下载代码,然后在项目根目录进行安装:
pip install -e .
然后就能使用 jupyter 运行以下代码:

支持:从图片生成点云、从文本生成点云、从点云生成 3D Mesh。
用 Point·E 依据文本提示生成 3D 点云的过程分为三个步骤:
1、依据文本提示,生成一个合成视图 (synthetic view)
2、依据合成视图,生成 coarse point cloud (1024 point)
3、基于低分辨率点云和合成视图,生成 fine point cloud (4096 Point)
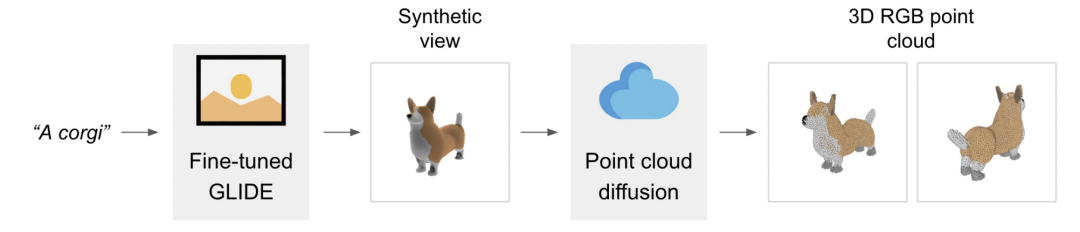
感兴趣的小伙伴,可以玩一玩。
DiT
没错,还是扩散模型。
绝大多数扩散模型,从 DDPM 开始,再到 DDIM、GLIDE,以及最新的 Imagen、LDM,用来预测噪声的网络,都是选择 UNet 作为基础架构。
加个多头 Attention,修改下网络尺寸,翻来覆去都是在折腾 UNet 结构。
最新发表的 DiT 改变了这个局面,用 Transformer!
扩散 Transformer(DiTs):一个基于 Transformer 的扩散模型主干,它优于先前的 U-Net 模型,并继承了 Transformer 模型类的优秀扩展特性,性能表现出色,代码刚刚开源!
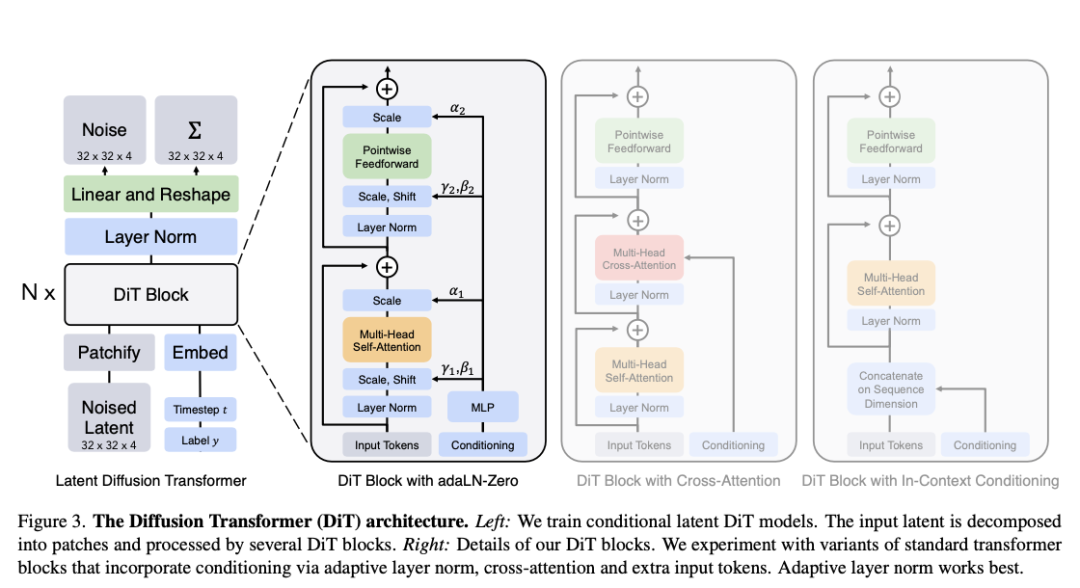
我们直接看下效果对比:

FID 指标越小越好,其余指标越大越好。
从数据上看,DiT 比 LDM 还要好。
LDM 是谁?就是 NovelAI 用的底层模型。

真实场景,逼真自然的 2D 图像生成,离我们不远了。
项目地址:
https://github.com/facebookresearch/DiT
不想部署开发环境,直接测试,作者也贴心地提供了 Web 环境:
https://huggingface.co/spaces/wpeebles/DiT
Best Papers 2022
时间过得真快,2022 年也接近了尾声。
跟往年一样,今年也出现了很多优秀的算法。
2022 年全年的 Amazing AI papers,有人整理了出来。
今年的,30+ 篇 Best Papers,整理得非常不错:
这里面的,有一部分我写过教程。
项目地址:
https://github.com/louisfb01/best_AI_papers_2022

 关注公众号
关注公众号
 计算机视觉研究院
计算机视觉研究院
 集智书童
集智书童
 极市平台
极市平台
 李rumor
李rumor