







 1970-01-01 08:00:00
1970-01-01 08:00:00
导读
在轻量模型上,高分辨率+多分支结构真的是必要的吗?基于此问题,MIT韩松老师组提出了用于边缘实时多人姿态估计的高效架构设计LitePose。本文主要阐述自己对该工作的一些思考和分析,欢迎大家一起讨论交流~

论文标题:Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation
论文链接:https://tinyml.mit.edu/wp-content/uploads/2022/04/CVPR2022__Lite_Pose.pdf
最近在交流群里听小伙伴提到了MIT韩松老师组在CVPR2022上的新工作LitePose,作者团队分别来自清华,CMU和MIT,由于图片上看起来非常强,所以我也第一时间拜读了一下。
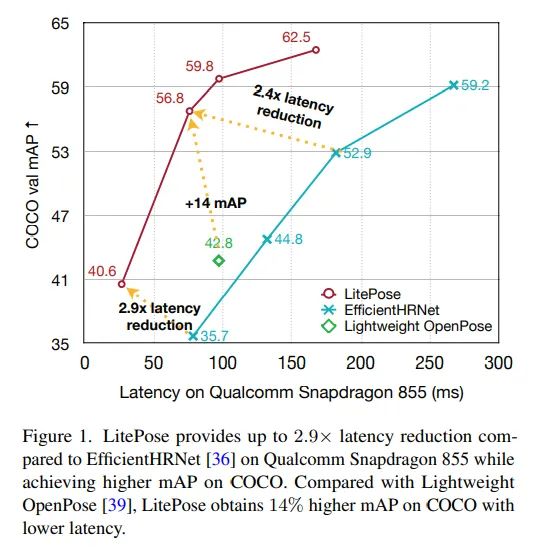
前言
整体而言,我认为这是一篇结论价值大于代码的工作,本文没有提出什么新的酷炫的技术或者模块,而是设计了一个巧妙的实验,得出了一个反直觉的结论,并以此为指导设计了更高效的模型,这其中的科研直觉和思维我认为是值得我们学习的。我个人接触轻量模型也有一段时间了,在实践中确实发现在轻量模型上,有很多大模型上的结论和方法是不适用的,对大模型有显著帮助的trick在轻量模型上完全有可能掉点,模型性能并不是随着计算量增大而单调递增的,其中存在很多的局部最优,因而如何在有限的计算资源下设计出最优的模型结构,总结出一些最优的设计准则,我认为同样是值得研究的。
另一方面不得不说的是,本文最终得出的结果并没有那么强,在COCO上的结果比去年的LiteHRNet都差了不少,也许是发现top-down卷不过,所以本文才立足于bottom-up设计,但是今年北航的DAS在75ms上也卷到PCK_rel 81.0了。当然,由于这两篇工作一个是2D一个是3D,报告结果的数据集也不一样,指标选择也不一样,但我怀疑DAS的表现也许是比本文好的。在结果对比中,本文也没有将LiteHRNet作为backbone进行实验,这也是我认为不够说服我的地方。
但不管怎样,本文同样具有学习的价值,这也是我写下这篇笔记的初衷,希望能带给大家一些有用的东西,指导我们自己进行轻量模型设计。
背景
姿态估计任务在围绕人为核心的视觉应用上扮演着相当重要的基石角色,当前在该任务上,受HRNet的设计原则影响,大家普遍认为高分辨率特征图,多分支的结构设计是提升模型性能的有效手段。
但高分辨率+多分支这一设计,意味着庞大的计算量,这与我们算法落地的高实时性需求是背道而驰的,因此本文提出了一个问题:在轻量模型上,高分辨率+多分支结构真的是必要的吗?
设计实验
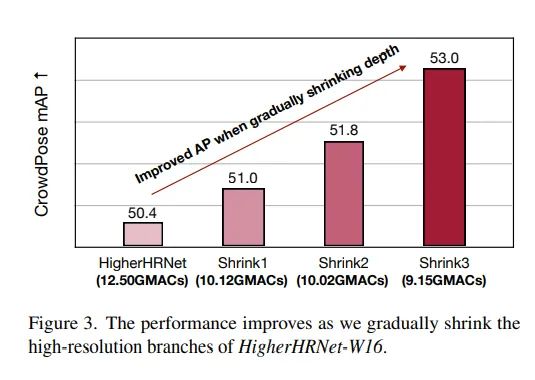
本文基于以上问题,设计了一个非常直观的实验,将一个HigherHRNet进行逐步缩减,渐进式地扔掉其中的一些模块和分支,直到最后还原成一个接近于单分支结构的模型,在这个过程中保持模型整体的计算量不变,如下图所示:
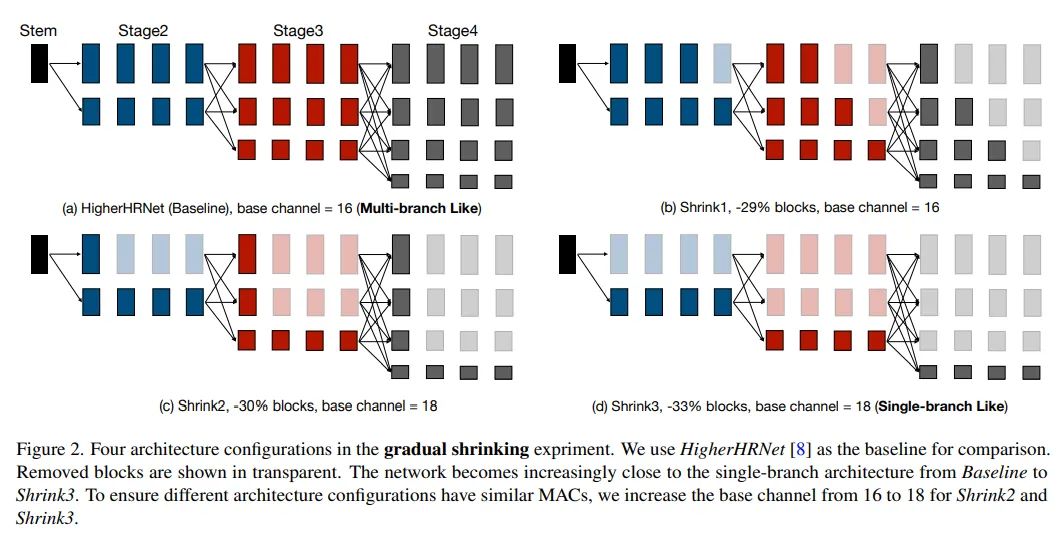
然而实验结果发现,随着模型的缩减,性能却是在提升的,这说明对于轻量模型而言,多分支高分辨率的结构是比较冗余的。这个结论其实不难理解,轻量模型原本就算力吃紧,很难在层数、通道数都极其有限的高分辨率分支上学到太多有益的东西,与其将有限的计算量浪费在这里,不如集中资源发掘高层的语义信息带来的收益高。
另外咱就是随口一说啊,你看最后这个结构,像不像FPN?像不像FPN?在写上一篇文章的时候我就感觉,什么HRNet,什么CenterNet,什么PIPNet,好像都是把目标检测的思想换了个样子在玩,关键点任务的真理没准真是目标检测yyds了(逃
Fusion Deconv Head
说到HRNet设计的高明之处,不得不提到的一个问题是scale variation,简单来说,由于画面中的目标大小是不一致的,有的图片中很大,有的很小,对于小的对象,在特征图分辨率小时就存在丢失问题,何况姿态估计,或者说关键点检测这件事本身,关节点就是一个相对较小的目标了。
HRNet通过显示地维护不同分辨率的分支,并在每个阶段进行fusion操作做信息交互,能最大程度上保留小目标的信息,让不同尺度的对象信息得以保留,这一思想在目标检测中也早有应用,也就是FPN。
大家需要注意的是,以上本文设计的实验,最后得到的模型是形似单分支,而非真正的单分支,尽管扔掉了高分辨率分支上的所有block,但依然维护了一条残差路径,将浅层特征传到深层,并进行特征融合。这种不同尺度特征的空间信息融合,带来的收益是毋庸置疑的,在FPN和ResNet中都经过了无数的实践,本文的实验也再一次验证了这一真理:
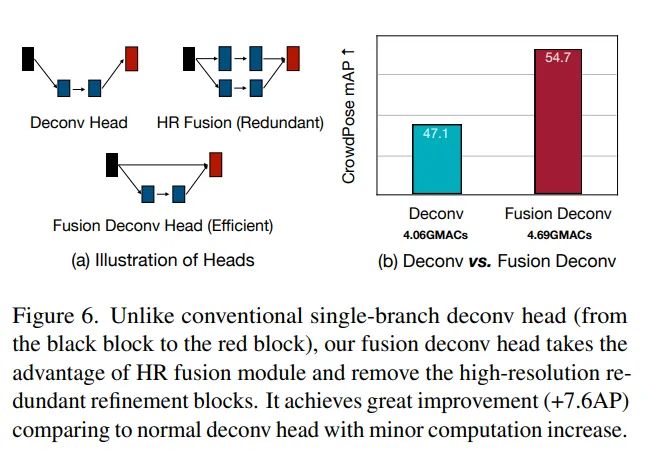
尽管本文起了Fusion Deconv Head这么个略fancy的名字,但在我眼中,这个东西不就是个残差结构吗,从ResNet到Hourglass和UNet,大家都在用,而本文的实验告诉我们,这条经验在轻量模型上也好用,而且是能涨点7.6AP的巨好用。
模型
在清楚了以上内容后,多分支高分辨率有冗余,但多尺度特征融合又很有用,那么最终的模型结构其实已经呼之欲出了:

说实话看到这个图的时候非常的眼熟,一瞬间我能列出一排相似的工作,尤其是BlazePose,我把图放上来大家自己感觉吧:
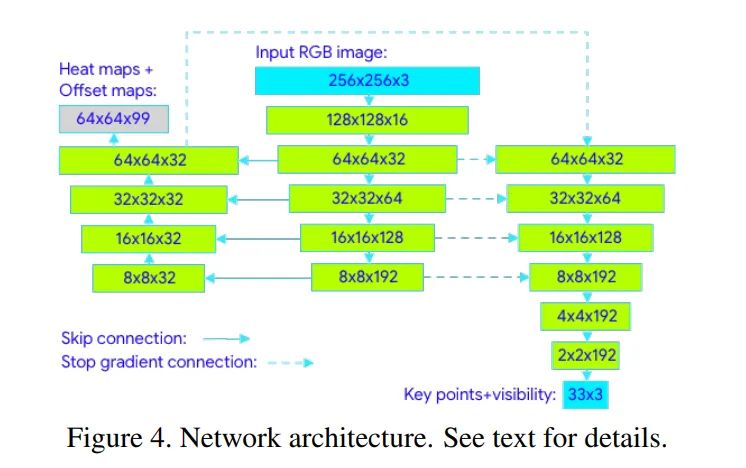
所以模型部分我觉得能分析的东西很有限,后续本文在模型结构上用到了large kernel,也用NAS搜了更优的参数组合,这些我觉得也都是近年的常规操作了,所以本文真正有意思的东西其实是那个实验设计和结论,在轻量模型设计时,面对极其有限的资源,大模型上有效的一些设计也许会变得冗余,或者说性价比低,所以发掘哪些东西是通用的,哪些trick只在大模型上好用,对小模型而言哪些东西性价比更高,这些东西是值得我们研究和关注的。
尽管最终给出的模型与之前的工作非常近似,但本文用具有说服力的实验进行了论证,进行了仔细的分析,我觉得这是做研究的学术价值,也是能启发我的东西。
结果
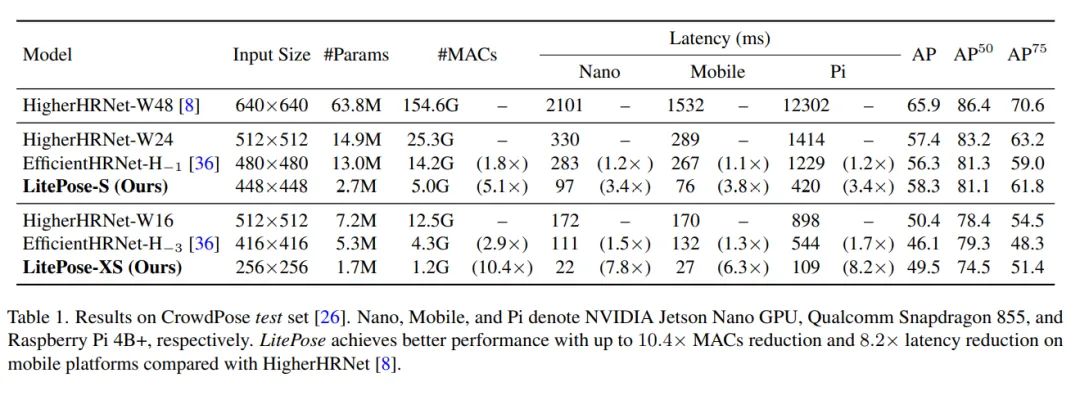
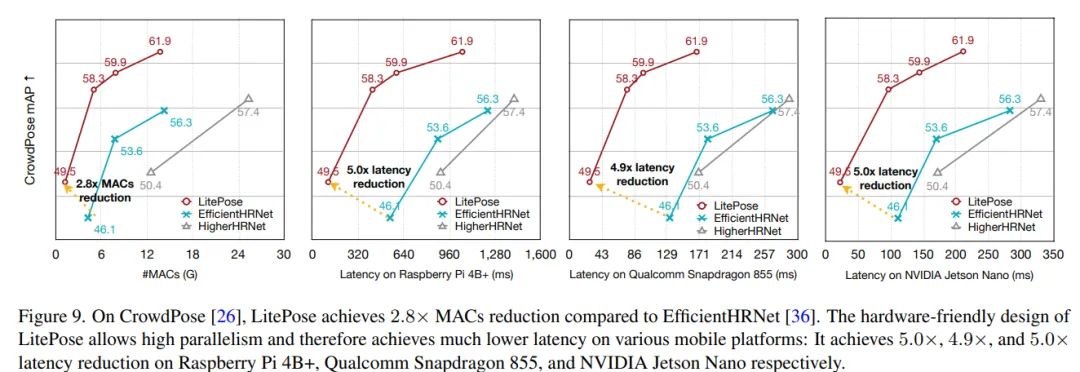
结果部分,由于对比的工作很少,我这里只放几张图了,更多的细节大家可以自行查阅原文:

 关注公众号
关注公众号
 计算机视觉研究院
计算机视觉研究院
 集智书童
集智书童

 Jack Cui
Jack Cui
 李rumor
李rumor