2026-04-16 18:45:00
2026-04-16 18:45:00
智猩猩AI整理
编辑:宁宁
大模型后训练正在发生一个明显变化:训练对象不再只是文本模型,训练流程也不再只是单轮问答。目前模型越来越多地接收图像、音频、视频等全模态输入,同时还要完成多轮推理、工具调用、搜索增强等 agentic 任务。问题也随之而来——很多 RL 训练框架最初都是围绕文本场景设计的,一旦把视频、音频和多轮交互真正接进来,系统很快就会暴露出三大难题:数据流高度异构、长尾时延和故障更难处理、同步训练吞吐低而异步训练又容易引入策略陈旧问题。
针对这些难题,小红书 AI Platform 团队联合港大、中科大提出并开源了 Relax(Reinforcement Engine Leveraging Agentic X-modality)。这不是单纯做算法改进的工作,而是一套面向全模态后训练的大规模异步强化学习引擎。它要解决的核心问题是:当 RL 后训练走向 omni-modal 与 agentic 场景后,系统如何同时做到能训练、训得稳、训得快,还能灵活扩展。实验结果证明,在 Qwen3-4B / DAPO-MATH-17k 实验中,Relax 相较 veRL 实现了 1.20× 的端到端加速;在统一训练框架下,fully async 模式相较 colocate 模式在 Qwen3-4B 上达到 1.76× 提升、在 Qwen3-Omni-30B 上达到 2.00× 提升,同时不同模式都能收敛到相近 reward 水平。

论文标题:
Relax: An Asynchronous Reinforcement Learning Engine for Omni-Modal Post-Training at Scale
论文链接:https://arxiv.org/abs/2604.11554
Github仓库地址:https://github.com/redai-infra/Relax?utm_source=chatgpt.com
01 方法
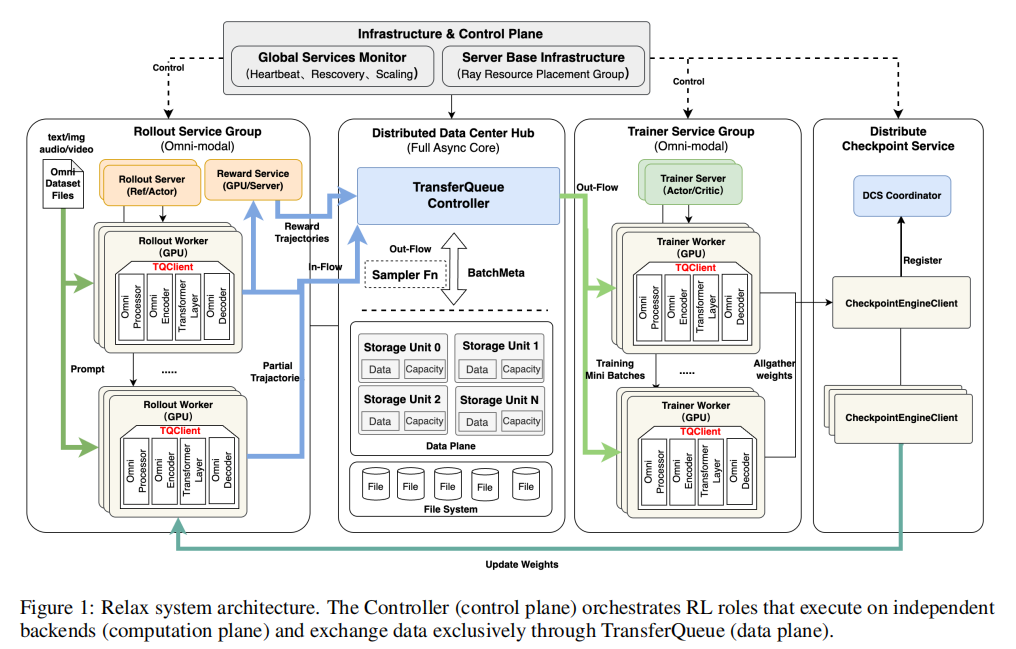
Relax 的关键,不是在原有文本 RL 框架上“打补丁式”加全模态支持,而是从系统底层重做了一套更适合 omni-modal RL 的基础设施,如上图所示。
(1)采用 omni-native 的全模态原生架构。图像、视频、音频和文本不会被粗糙地拼接处理,而是通过统一数据管线完成解析、组织、编码和 batch 构建。在 Relax 中,全模态支持不是后接在文本 RL 框架上的补丁,而是从数据处理到推理生成都被纳入系统底层设计。
(2)采用角色隔离的服务化架构。Actor、Rollout、Critic、Reward 等 RL 角色都被做成独立服务,每个角色都可以单独部署、扩缩容、监控和恢复。这样做的好处很明显:某个角色异常时不会立即拖垮整个系统,而且资源调度也更灵活。围绕这一点研究团队还设计了 DCS 来负责训练侧与推理侧的权重同步,并加入健康监控和故障恢复机制,让系统更适合长时间稳定运行。
(3)基于 TransferQueue 的异步训练机制。传统 RL 训练常常要等最慢的一批样本完成,尤其在全模态场景下,一段长视频或一条超长推理链就可能把整个 step 卡住。Relax 用 TransferQueue 作为数据总线,把不同角色之间的数据交换解耦,并通过 max_staleness 参数统一控制 on-policy、near-on-policy 与 fully async/off-policy 三种训练模式。同时,Relax 引入了 streaming micro-batch 机制,用 micro-batch 级别的数据流动替代整批同步等待。这样,下游阶段不必等整个 global batch 全部完成,而是可以在部分数据就绪后尽快开始处理,从而缓解长尾生成延迟带来的阻塞。
02 评估
为了验证系统设计是否真的有效,研究团队从全模态收敛性、端到端性能、不同训练模式比较,以及 MoE 场景稳定性四个维度展开实验。
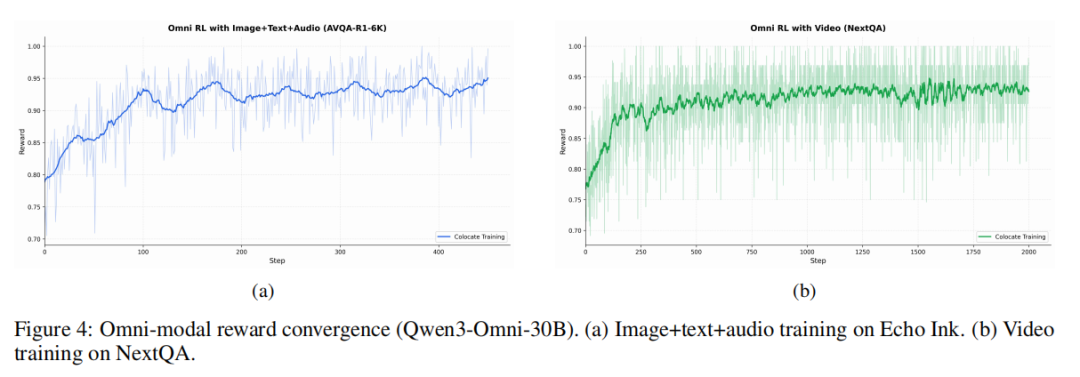
在全模态收敛实验中,研究团队使用 Qwen3-Omni-30B,在 Echo Ink 上进行音频+图像推理训练,在 NextQA 视频子集上进行视频理解训练。结果显示,在 Echo Ink 任务上,reward 从 0.72 提升到约 0.93,大约 450 steps 进入平台;在 NextQA 视频任务上,reward 从约 0.75 提升到约 0.93,并且在 2000 多步训练中没有出现 collapse 或明显退化,如图4所示。这说明 Relax 不只是“支持全模态输入”,而是真的能把复杂全模态 RL 训练稳定跑通。
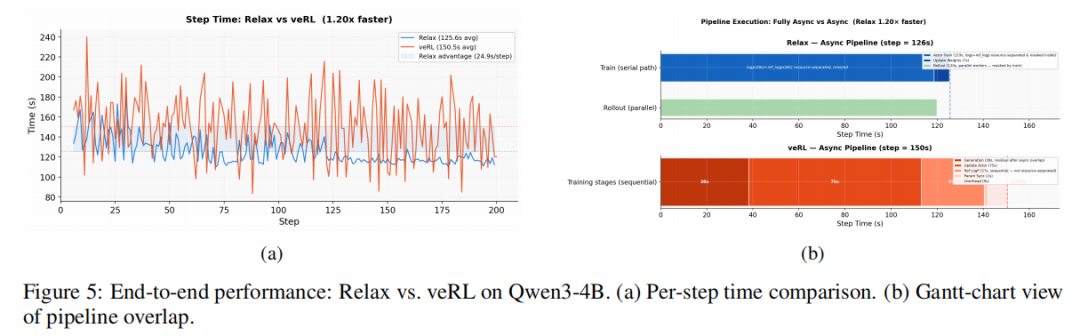
在端到端性能实验中,研究团队将 Relax 与 veRL 对比,模型为 Qwen3-4B,数据集为 DAPO-MATH-17k。结果显示,Relax 的 step time 为 125.6 秒,veRL 为 150.5 秒,实现了 1.20× 的端到端加速,如图5所示。研究团队指出,这种优势并不来自某个单独算子的优化,而是来自整体 pipeline overlap:训练端更早拿到可消费数据,关键路径等待更少,所以整条流水线更顺。
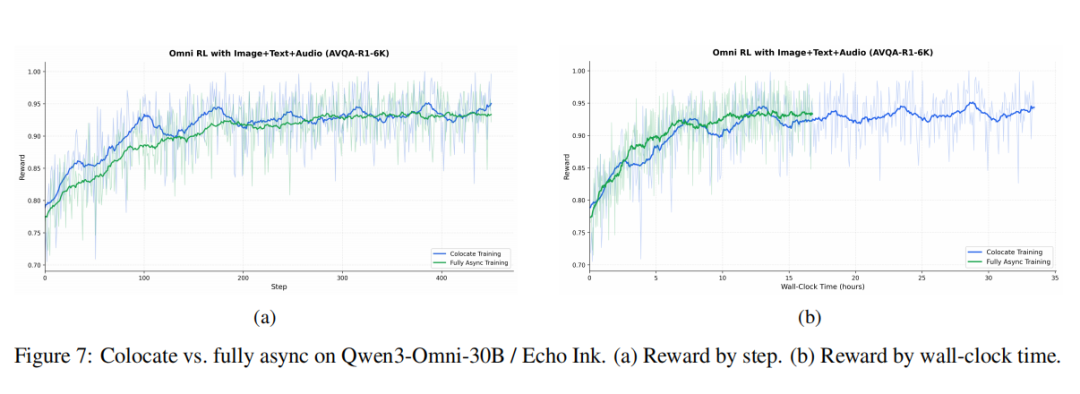
在训练模式比较实验中,Qwen3-4B 上 async off-policy 相较 colocate 达到 1.76× 提升,async on-policy 也有 1.12× 提升,而且三种模式最终都收敛到相近 reward,如图7所示。进一步在 Qwen3-Omni-30B 上,fully async 相较 colocate 达到 2.00× 加速。这说明一个很清晰的趋势:模型越大、模态越复杂,异步服务化架构的优势就越明显。
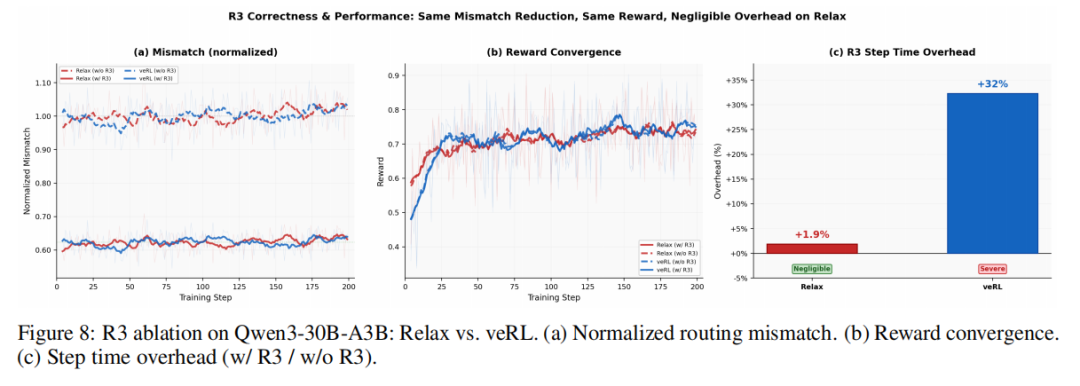
研究团队还考察了 MoE 模型下的训练稳定性,如图8所示。结果表明,启用 R3 后,rollout-training 的 mismatch 可下降约 38%;更重要的是,Relax 几乎把这项稳定性增强机制做成了低成本操作:在 veRL 上启用 R3 会带来 32% 的 step time 开销,而在 Relax 上只有 1.9%。此外,在多轮 agentic RL 任务 Deepeyes 上,Relax 在 Qwen3-VL-MoE-30B 上与 veRL 收敛到相同的 reward 上界,说明它不仅能处理感知型全模态任务,也能正确支撑带工具调用的多轮 RL 训练。
03 总结
Relax 的价值不在于提出某个新的 RL 算法,而在于正面回答了一个越来越现实的问题:当大模型后训练从文本走向图像、音频、视频和 agentic 交互后,我们还能不能用一套统一、稳定、可扩展的系统把训练真正跑起来?
研究团队给出的答案是肯定的。通过全模态原生管线、角色隔离的服务化架构、TransferQueue 驱动的异步训练,以及统一 staleness 抽象,Relax 把“全模态支持”“大规模稳定运行”和“高吞吐异步执行”尽量统一到了同一个系统框架内。实验结果证明,这套设计不仅带来了可观的性能收益,也在图像、音频、视频和多轮 agentic 场景中展示了可靠的收敛能力。
对于关注大模型后训练的人来说,这篇工作传递出的一个重要趋势是:未来 RL 的竞争,不只在算法,也在系统。谁能更好地处理异构数据、更稳地管理服务和故障、更高效地把 rollout 与训练并行起来,谁就更可能把 omni-modal 和 agentic 模型真正推向规模化落地。

 关注公众号
关注公众号