2026-04-07 16:30:00
2026-04-07 16:30:00
智猩猩AI整理
编辑:六六
视频生成中的 GRPO 方法(比如 FlowGRPO),一直远不如它在文本和图像领域那么好用。为什么?因为视频的“解空间”太复杂,探索过程中从 ODE 转到 SDE 会注入大量噪声,结果就是生成的视频质量下降、奖励信号也变得不可靠,整个后训练过程摇摇欲坠。
针对上述问题,腾讯混元研究团队提出了面向视频生成的流形感知 GRPO 框架 SAGE-GRPO(Stable Alignment via Exploration)。在 HunyuanVideo1.5 上使用原始 VideoAlign 作为奖励模型对所提 SAGE-GRPO 进行评估,结果显示,在视觉质量(VQ)、运动质量(MQ)、文本对齐(TA)以及视觉指标(CLIPScore、PickScore)上均持续优于先前方法,充分证明了其在奖励最大化与整体视频质量、尤其是动作连贯自然表现方面的优越性能。成果代码已开源。

论文标题:Manifold-Aware Exploration for Reinforcement Learning in Video Generation
论文链接:https://arxiv.org/pdf/2603.21872v1
项目主页:https://dungeonmassster.github.io/SAGE-GRPO-Page/
Github:https://github.com/Tencent-Hunyuan/SAGE-GRPO
01 方法
研究团队将视频生成中的 GRPO 问题形式化为一个流形约束的探索问题,并指出现有方法中所采用的 ODE 到 SDE 的转换会在高噪声步中注入过量噪声,从而降低 rollout 质量,并削弱奖励引导更新的可靠性。如图 1 所示,高噪声区域欧拉离散化引入了额外能量(紫色区域)(如 a.1所示),精确 SDE 能够去除多余噪声(如 a.2 所示),从而实现 SAGE-GRPO 生成更稳定、对齐更优。
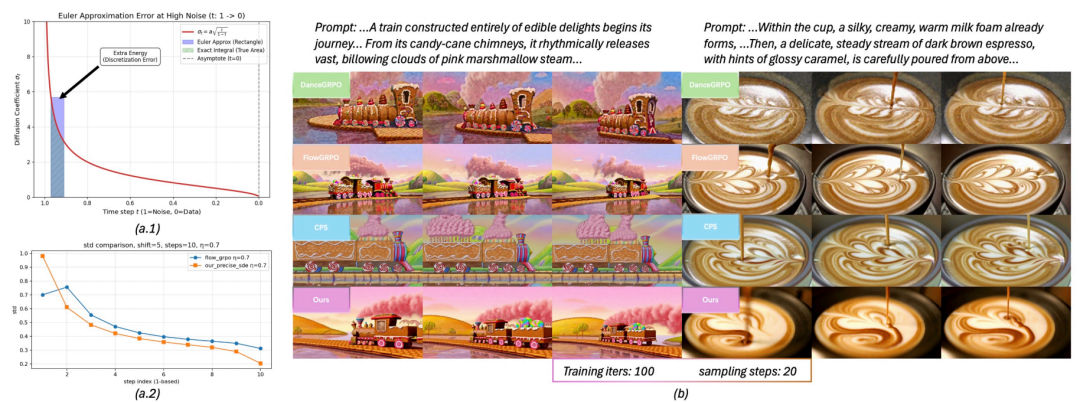
图 1 SAGE-GRPO 示意图。
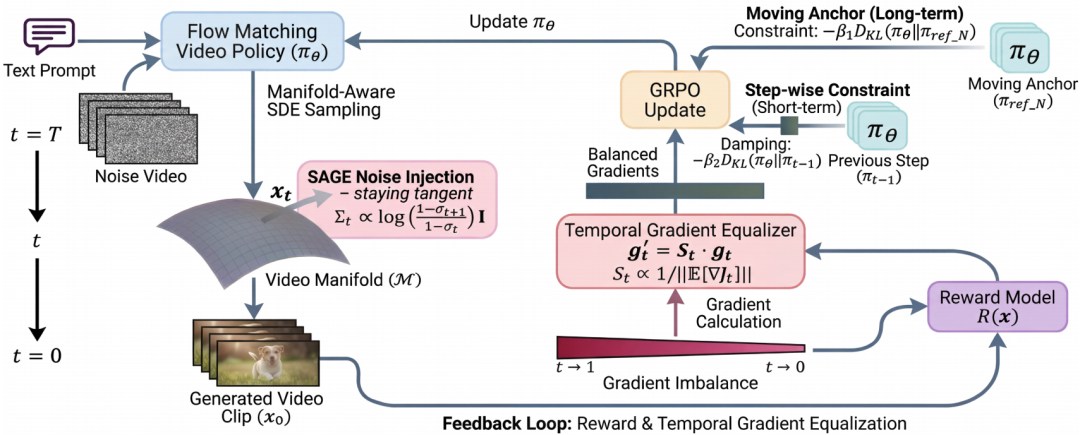
图 2 SAGE-GRPO 框架。
1. 微观探索:精确 SDE 与梯度均衡
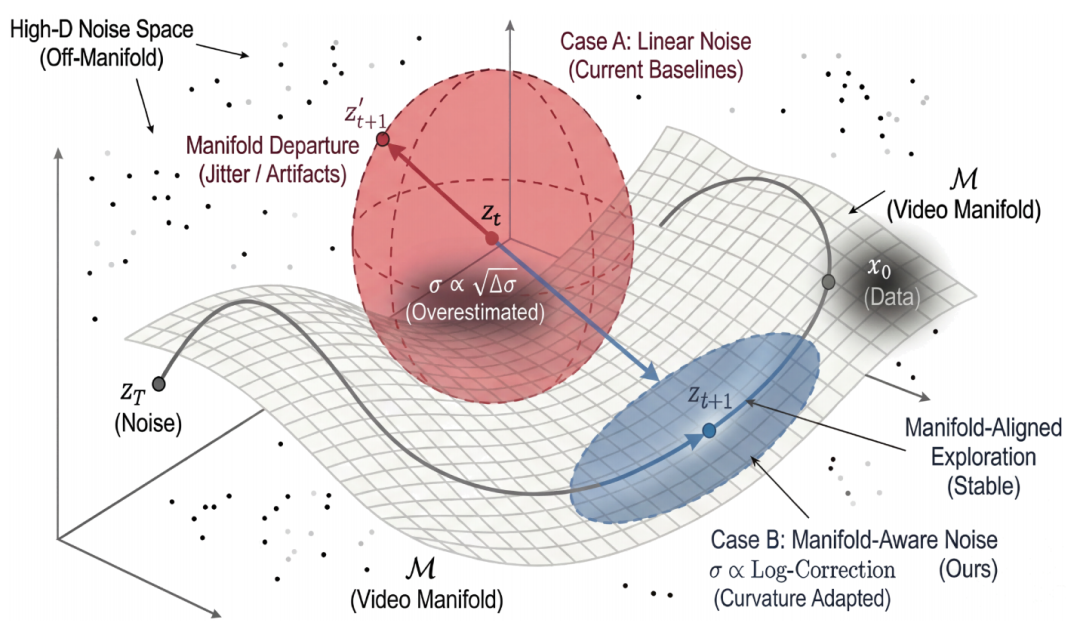
图 3 噪声注入策略的几何解释。
(1)更精确的噪声计算
为实现 GRPO 的随机探索,采用一种边缘保持 SDE(marginal-preserving SDE)对校正流(Rectified Flow)进行扰动,该 SDE 的噪声保持在与视频流形 对齐的方向上。
传统方法使用一阶近似估算噪声标准差,相当于用直线拟合曲线,误差较大,容易导致探索偏离流形。对于具有特定扩散系数的边缘保持 SDE,可通过对时间区间上的方差进行积分,得到一个包含对数校正项的方差表达式。
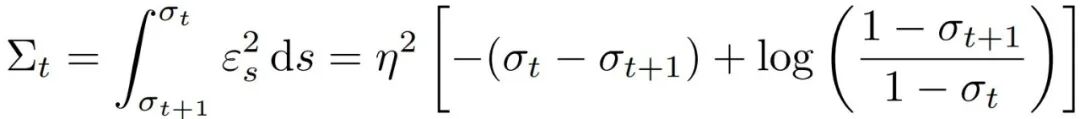
由此形成的探索区域更小、更贴近原始生成轨迹(如图 3 中蓝色椭球与红色球体的对比)。这一几何设计确保每一步探索均保持在合法的视频空间内,从而有效避免时间伪影。
(2)梯度均衡
在扩散过程中,高噪声步(初期)梯度几乎为零,低噪声步(后期)梯度极大,导致模型偏向学习后期细节而忽略整体结构。
为此,SAGE-GRPO 估计每个时间步的梯度大小,并采用基于中位数的归一化因子,将各时间步的优化压力拉到同一量级,从而使结构(布局、运动)与纹理(细节)的更新贡献均衡,训练更加稳定。
2. 宏观探索:双信任域优化
在微观探索得到稳定化之后,为防止策略模型偏离数据流形并陷入流形外的局部最优,将 KL 散度构建为一种动态锚定机制,用于约束探索朝向数据流形。
固定 KL(硬约束):锚定于初始模型,但会阻碍策略达到最优,导致欠拟合。
逐步 KL(速度约束):锚定于上一步策略,限制每步更新幅度,但无法限制累积位移,易产生长期漂移。
周期性移动 KL(位置控制):每 N 步将当前策略设为新参考,形成动态信任域,在保持稳定性的同时分阶段探索。
双重 KL(位置-速度控制器):组合位置控制与速度控制:
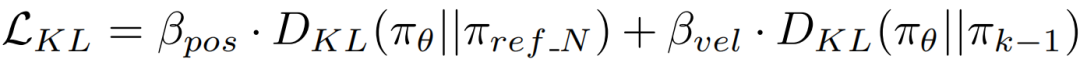
其中逐步 KL 通过对数概率差的期望近似:
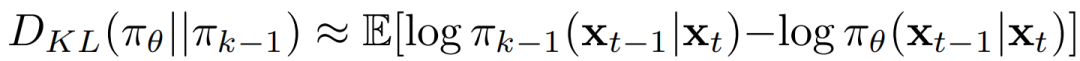
02 评估
所有实验均在 HunyuanVideo 1.5 上进行,采用 VideoAlign 作为奖励评估器,评估视觉质量(VQ)、运动质量(MQ)和文本对齐(TA),
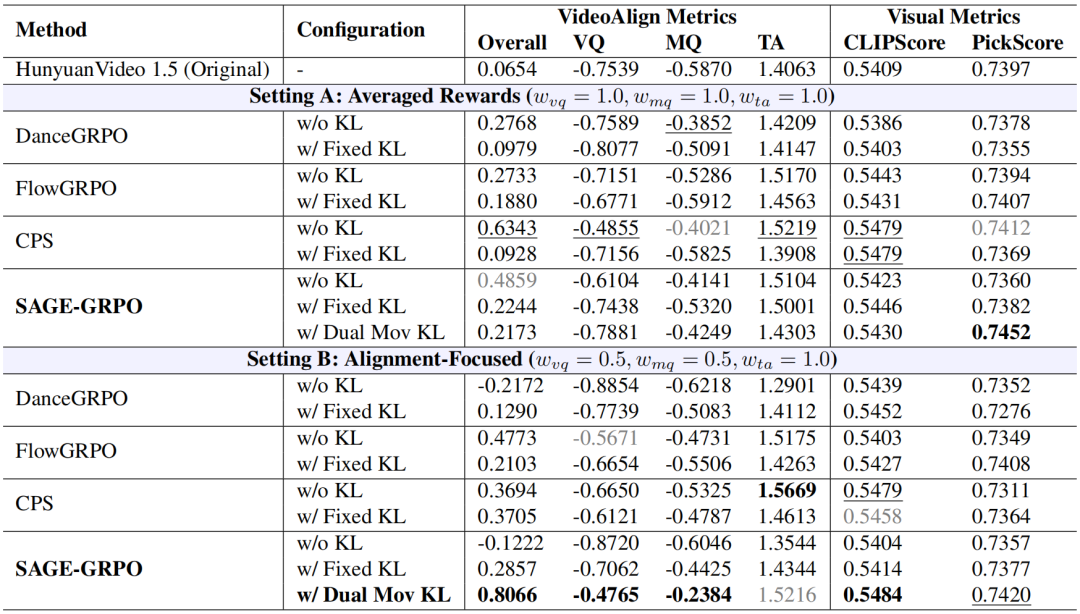
在平均奖励与对齐聚焦两种设置下,比较了各方法与 SAGE-GRPO 在有/无 KL 正则化时的表现,如表 1 所示。在对齐聚焦设置(设置 B)中,采用双重移动 KL 的 SAGE-GRPO 在总体、VQ、MQ 及 CLIPScore 上均取得最佳结果,同时 TA 接近最优。这表明,强调对齐能提供更可靠的优化目标,并在奖励与视觉指标上带来更稳定的提升。
表 1 视频生成基准测试上的比较。 在两种奖励设置下,SAGE-GRPO 与各基线方法的比较结果。
定性分析:图 4 的三个提示示例展示了所提方法的核心提升:上部分展示了在保持准确视觉内容的同时减少时间抖动;中间部分体现出在遮挡和光照变化条件下增强对齐度与逼真度;下部分表现更强的语义对齐能力,实现跨帧一致的提示匹配。

图 4 与基线方法的定性比较。
用户研究:邀请 29 名评估者对 32 个提示进行用户偏好研究,从视觉质量、运动质量和语义对齐三方面比较 SAGE-GRPO 与基线方法。表 2 的成对胜率显示,SAGE-GRPO 方法获得显著的人类偏好优势,尤其在视觉质量上最为突出,验证了自动指标与感知质量的一致性。
表 2 用户偏好研究:SAGE-GRPO 相较于各基线方法的胜率对比。


 关注公众号
关注公众号