2026-05-07 21:45:00
2026-05-07 21:45:00
智猩猩AI整理
编辑:林夕
当前,用户普遍期待大语言模型能借助外部工具处理订票、网购等实际事务,但工业级智能体系统大多依赖GPT‑5、Claude等大型专有模型,API费用高昂。即便是开源的Qwen3‑235B,在百万级用户场景下计算成本依然过高。
对于Vibe coding这类高度专业的复杂任务,超大模型的确有必要。但订票、检索等标准化高频任务,并不需要巨型模型。小模型完全可以胜任,并显著降低成本与延迟。可惜的是,Kimi、MiniMax、DeepSeek等主流机构,很少推出具备强智能体能力的小模型,市场存在明显缺口。
针对这一问题,阿里团队以Qwen轻量底座为基础,打造出AgenticQwen模型体系。研究团队首创推理+智能体双数据飞轮训练架构,依托多轮GRPO强化学习机制,使8B/30B小模型在工具交互任务中逼近超大模型水准。实验结果表明,在TAU-2与BFCL-V4两项主流智能体基准评测中,AgenticQwen-8B模型取得47.4的综合分数,性能是基线Qwen3-8B(23.8)的2倍以上。仅激活3B参数的AgenticQwen-30B-MoE版本,综合得分达到50.2,推理时延相比Qwen3-235B降低23%,在性能逼近超大模型的同时实现了效率的显著提升。

论文标题:AgenticQwen: Training Small Agentic Language Models with Dual Data Flywheels for Industrial-Scale Tool Use
论文链接:https://arxiv.org/pdf/2604.21590
项目地址:https://huggingface.co/collections/alibaba-pai/agenticqwen
01 核心创新
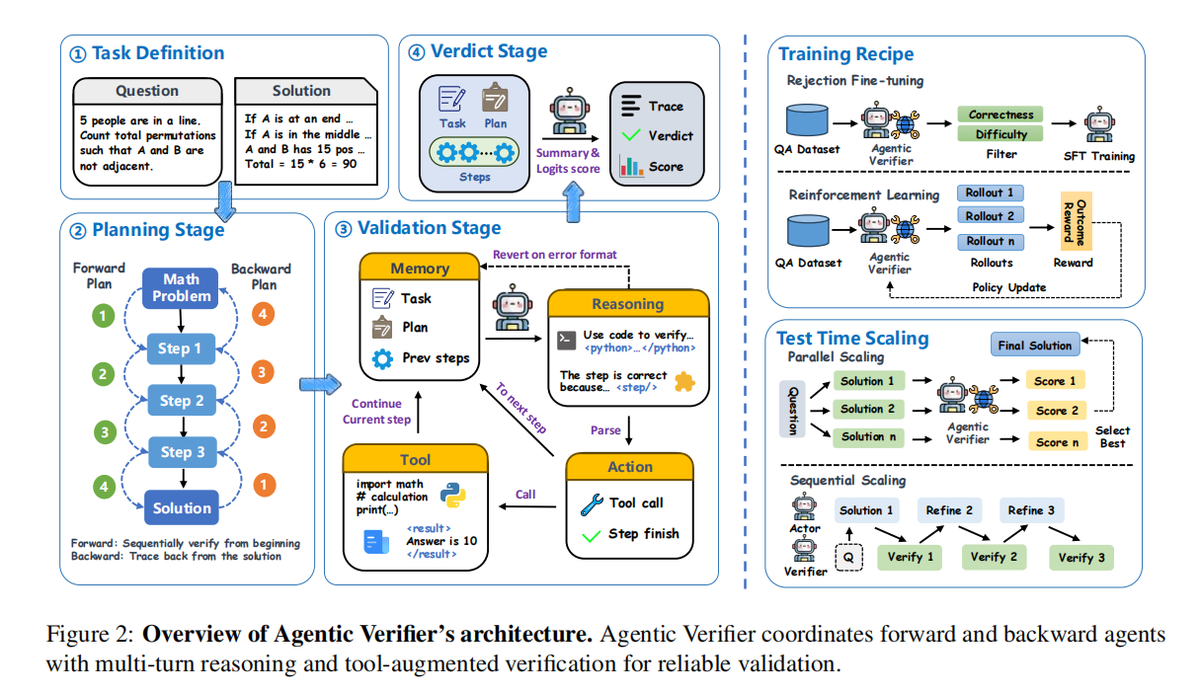
AgenticQwen训练框架融合推理RL与Agentic RL,分别对应两个相互独立又互补的数据飞轮。
推理RL(Reasoning RL):聚焦多步推理任务,基于Omni、2WikiMultiHopQA、HotpotQA等数据集开展训练,引导模型调用网页搜索、代码解释器等工具,解决数学推理、多轮问答等复杂问题。训练采用二元奖励机制,直接以最终结果为导向:答案正确得满分,错误则计0分。
Agentic RL:瞄准真实工业落地场景任务,以SYNTHAGENT数据集作为初始训练底座,同时借助Qwen3-235B构建模拟用户与工具交互的仿真环境。训练不再采用简单二元奖励,而是基于rubric(评分细则)的 0-1连续奖励,把任务拆成若干可验证子目标,按完成比例给分。
但仅靠这两类RL与固定数据,模型训练一两轮就会快速饱和、性能不再提升。于是团队提出双重数据飞轮(Dual Data Flywheels):通过从模型错误中持续挖掘、生成更具挑战性的多样化训练样本,形成闭环迭代,推动模型能力迭代升级。
第一重飞轮:推理数据飞轮(Reasoning Data Flywheel)
从模型失败样本出发,用自指令扩展与场景注入生成更具挑战性的推理问题,再经多模型一致性过滤得到高质量可验证难题,最终回流至训练流程,持续提升模型多步推理与工具协同解题能力。
第二重飞轮:Agentic 数据飞轮(Agentic Data Flywheel)
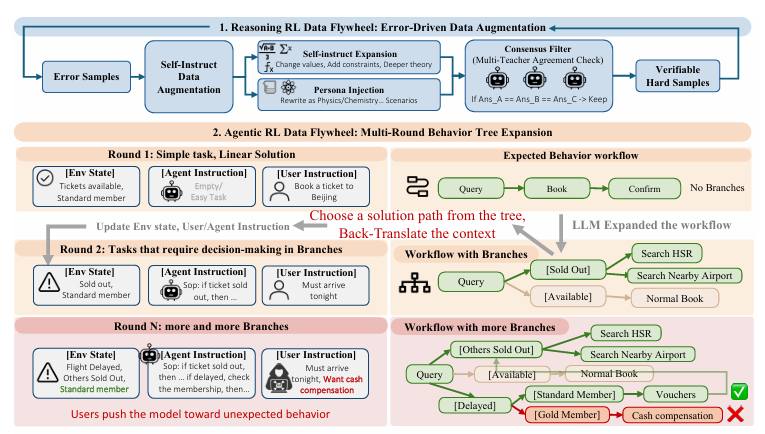
Agentic RL 的训练以线性任务为起点,通过四个阶段的迭代,把简单的工具调用流程,逐步升级为具备复杂分支决策能力的真实工作流。
(1)线性任务初始化。
以无分支、无异常的单路径任务为起点,让模型学习基础工具调用流程,例如完成 “查询机票→预订→确认” 的标准流程,掌握工具语义与基础交互逻辑。
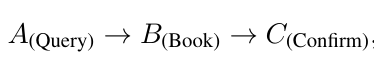
(2)行为树扩展
引入环境状态变化,将线性流程扩展为多分支行为树。例如机票售罄时,衍生出查询高铁、搜索邻近机场等备选路径,让模型学习条件判断与多方案切换。

(3)通过分支到任务的倒置生成新任务
将扩展后的行为树反向生成新任务,把每个分支对应的环境状态、用户指令与操作规范转化为训练样本,推动训练数据复杂度持续提升,从固定流程走向动态决策。
(4)对抗性模拟用户干预
在多分支行为树基础上,加入航班延误、用户不合理诉求等对抗场景,甚至模拟误导性指令,迫使模型在复杂分支中做出合规决策,避免无效路径,提升鲁棒性与边界处理能力。
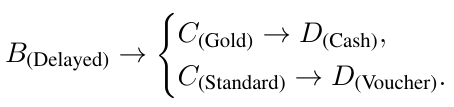
通过多轮迭代,简单的线性任务会逐渐成长为包含数十个分支的复杂行为树,覆盖各种正常流程、异常情况和对抗场景。
02 实验结果分析
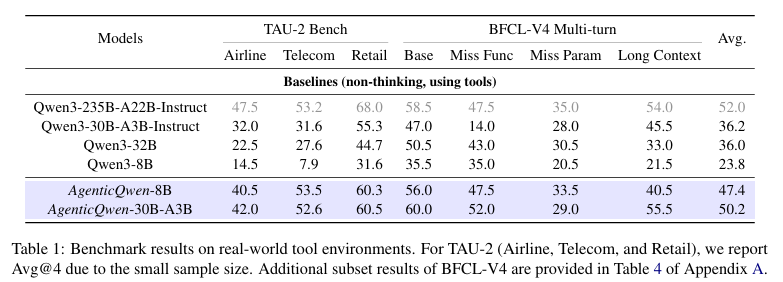
论文在TAU-2和BFCL-V4 Multi-turn上评估模型。TAU-2覆盖航空Airline、电信Telecom、零售Retail这三类场景,来评估模型在真实世界中的可靠性;BFCL-V4 Multi-turn用来评估模型多轮调用工具的能力。
(1)公开Agentic Benchmark
在公开智能体基准上,AgenticQwen的表现远超同尺寸原生模型,甚至在部分任务中追平或超越超大模型。
在覆盖航空、电信、零售三大真实场景的 TAU-2 测试中,AgenticQwen-8B 平均分达到47.4,是原生Qwen3-8B(23.8)的两倍,大幅缩小了与 Qwen3-235B 的差距;AgenticQwen-30B-A3B则进一步将平均分提升至50.2,在电信、零售等场景中表现亮眼。
而在BFCL-V4 Multi-turn多轮工具调用测试中,两个版本同样实现了对基线的全面超越。特别是在Base子集上,AgenticQwen-30B-A3B以60.0的得分,超过了 Qwen3-235B的58.5,展现出小模型在标准化工具编排任务上的强大潜力。
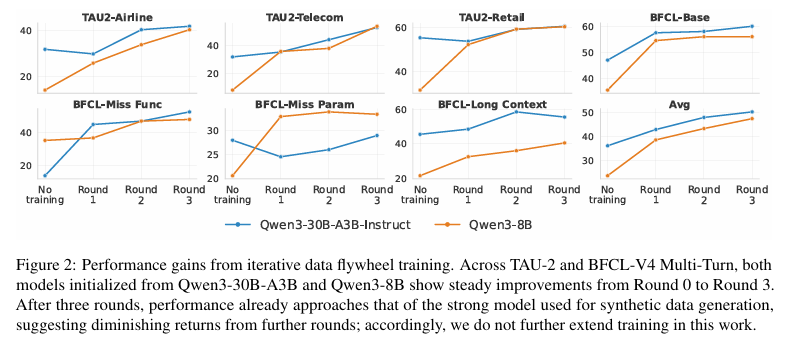
(2)飞轮训练迭代效果
AgenticQwen-8B与30B版本从第0轮到第3轮训练,在七大任务类别上性能持续稳定提升,三轮训练后接近数据生成大模型水平,验证双飞轮训练的有效性。其中AgenticQwen-30B-A3B为混合专家模型,仅激活3B参数,推理效率优于密集型 8B模型,实现参数量与性能的平衡。
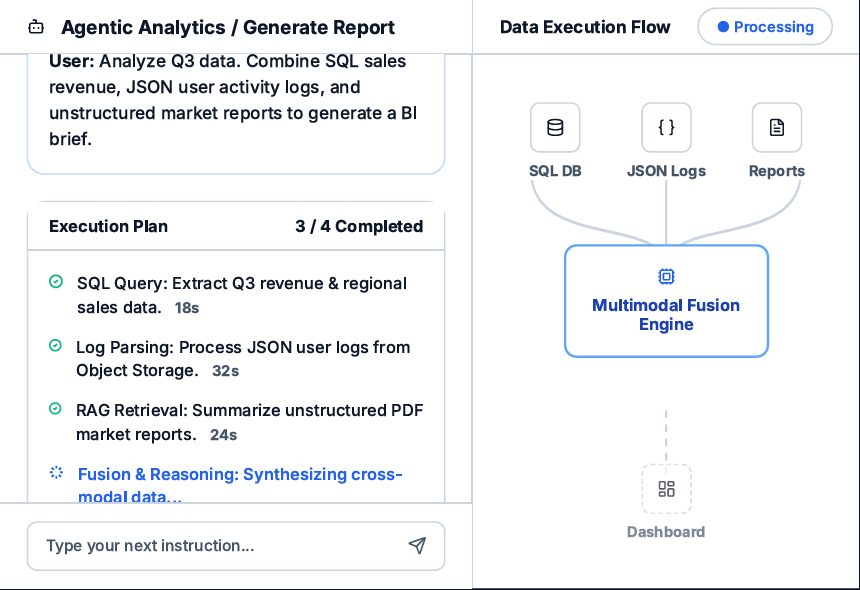
(3)工业系统部署
研究团队进一步将AgenticQwen集成并部署到云端Agent产品系统中,系统通过沙箱环境调用各类工具,可自主串联完成SQL销售数据查询、JSON用户日志解析、PDF市场报告检索增强生成全流程,实现多源跨模态数据融合推理,自动产出标准化业绩简报。
整套任务全程自主闭环、无需人工介入,生成报告的内容质量可与Qwen3-235B超大模型持平,部署与使用成本却足足降低了一个数量级。
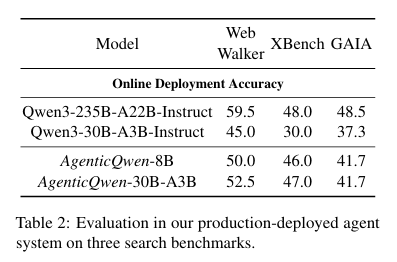
在阿里云产品环境的沙盒中,AgenticQwen模型在有限搜索数据训练下,仍实现出色泛化。WebWalker、XBench、GAIA三大基准中,AgenticQwen-30B-A3B得分52.5、47.0、41.7,远超基准Qwen3-30B-A3B,逼近Qwen3-235B。
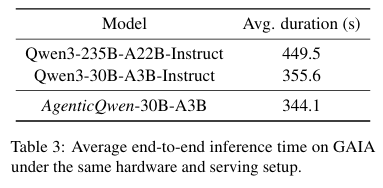
推理延迟方面,相同硬件环境下,AgenticQwen-30B-A3B平均推理时长344.1秒,优于原生30B模型,远低于Qwen3-235B的449.5秒,推理步骤更精简,效率更高。
04 总结
AgenticQwen 的发布,标志着工业级 Agent 进入了 "小模型也能办大事" 的新时代,突破核心在于双数据飞轮解决小模型训练数据瓶颈,推理飞轮提升抽象解题能力,智能体飞轮适配真实场景决策复杂性,强化学习与动态数据生成结合,让小模型精准掌握工具调用逻辑。相比原生模型,该方案无需扩大参数量即可实现性能跃迁,在成本、延迟与性能间取得最优平衡,适合工业规模化部署。

 关注公众号
关注公众号