







 2022-09-30 10:38:17
2022-09-30 10:38:17
摘要
学习准确的深度对于多视图3D目标检测至关重要。最近的方法主要是从单目图像中学习深度,由于单目深度学习的不适定性,这些方法面临着固有的困难。在本项工作中,作者没有使用单一的单目深度方法,而是提出了一种新颖的环视temporal stereo(STS)技术,该技术利用跨时间帧之间的几何对应关系来促进准确的深度学习。具体来说,作者认为将自车周围所有摄像头的视野作为一个统一的视图,即环绕视图,并对其进行temporal stereo匹配。利用来自STS的不同帧之间的几何对应关系,并与单目深度相结合,以产生最终的深度预测。nuScenes的综合实验表明,STS极大地提高了3D目标的可检测性,尤其是对于中长距离目标。在BEVDepth与ResNet-50主干网络上,STS分别将mAP和NDS提高了2.6%和1.4%。当使用更大的主干和更大的图像分辨率时,也都有提升,证明了STS的有效性。
概述
鸟瞰图(BEV)中的多视图3D目标检测最近发展迅速,因为它是基于LiDAR的解决方案可行的替代方案,并且成本低得多,适用于机器人和自动驾驶系统。然而,由于缺乏足够的信息,用RGB图像来预测深度长期以来一直是一个具有挑战性的问题。因此,提高基于相机3D目标检测的深度预测能力越来越受到研究人员的关注。
深度估计主要包括基于单目、双目、多目、temporal stereo(也叫从运动中获取)等方法,其中最常见的是单目深度估计,可以直接从RGB图像中学习到深度信息。单目深度估计主要根据视觉线索估计深度,例如阴影、地平面和目标的垂直位置。但只用一张图来估计深度是不靠谱的,至少需要两张图像,也就是基于立体的方法,基于立体的方法也分为双目、多视图立体以及temporal stereo(从运动中获取深度)。双目是需要相同平面上的两个前视相机(如下图a),而多视图(multi-view stere,MVS)则需要多个具有已知相对位置的相机(大于2个),如下图b,其中MVS在三维重建中广泛应用。temporal stereo则是从图像序列中估计深度信息,这些图像之间的相机自运动是已知的(如下图c)。现在多视图3D目标检测中,常用的方法仍然是基于单目图像的,基于立体的方法研究较少。
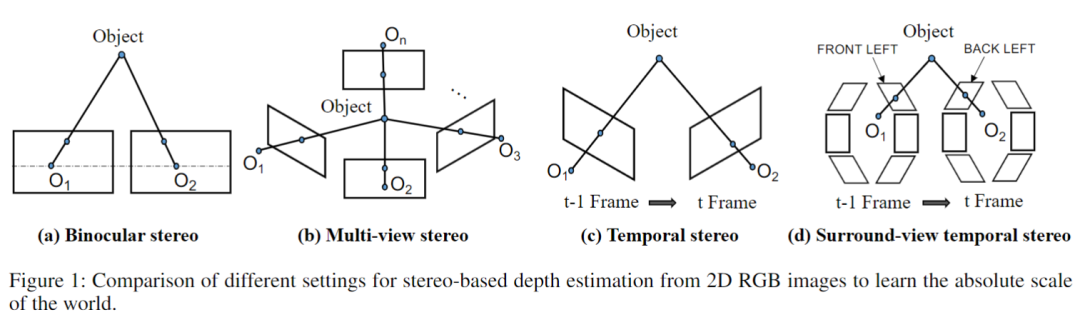
在多视图3D目标检测中,不同相机的视野(FoV)不一定需要重叠,这使得利用传统的基于立体的技术是不可行的。但随着时间的推移,出现重叠是很正常的。特别是,这种重叠可能发生在相机之间。例如,时间戳t−1处的“FRONTLEFT”相机中的目标可能会出现在时间戳t的“BACKLEFT”相机中,这就提供了利用temporal stereo的机会。因此,基于任务的特殊性,作者探索了一种新的temporal stereo模型,即Surround-view Temporal Stereo(STS),以促进多视图3D检测中的准确深度学习(如上图(d))。具体来说,STS首先为参考帧中的每个空间位置生成深度假设,然后使用可微单应性warping将它们在源帧中的相应特征从历史帧warp到参考帧。与现有的temporal stereo方法仅使用同一摄像机内跨时间的对应关系不同,STS允许跨摄像机的对应关系,可以充分利用帧之间的几何对应关系。此外,参考图像中深度均匀分布的假设,将会在源图像中采样到非均匀特征(短距离稀疏但长距离密集,见下图),不同的特征距离将过采样或欠采样。

作者使用非均匀深度假设,即Spacing-Increasing Discretization(SID(Fu et al. 2018))来解决此问题。这与MVS中的逆深度假设(Xu and Tao 2020)具有相同的思想。最后,由于temporal stereo深度估计在无纹理区域和移动物体中存在困难,作者将来自STS的深度预测与单目深度模块相结合,使它们互补。
作者以BEVDepth(Li et al.2022a)作为基础检测器对nuScenes(Caesaret al.2020)数据集进行了大量实验。结果表明,STS极大地提高了3D目标检测的性能,特别是对于单目深度估计难以处理的中远距离目标。总而言之,本文的贡献主要是三个方面:
将temporal stereo技术引入多视图3D目标检测中,提出了一种新的立体范式,即环视temporal stereo(STS),以促进准确的深度估计和3D目标检测。
作者进行了充分的实验来分析STS带来的积极影响,以及它们在整个算法中的不同作用。
STS方法在多视图3D目标检测中实现了新SOTA。
相关工作
3D目标检测
最近,与基于LiDAR的方法相比,多摄像头检测目标由于成本低而受到欢迎。DETR3D(Wang et al.2022)和 PETR(Liu et al.2022)在3D空间中设置目标查询并与Transformer解码器中的多视图图像进行交互。BEVDet(Huanget al. 2021)和BEVDet4D(Huang and Huang 2022)遵循LSS(Philion and Fidler 2020),它首先将每个图像单独提升为每个相机的特征截锥体,然后将所有截锥体分解为统一的bird-eye-view representation,并应用像 Center-Point(Yin, Zhou, and Krahenbuhl 2021)这样的检测头来获得最终的3D检测结果。BEVFormer(Li et al. 2022b)引入了空间交叉注意力来聚合图像特征和时间自注意力来融合历史BEV特征。在上述范式中,深度估计对于获得高质量的BEV特征非常重要。BEVDepth(Li et al.2022a)尝试学习值得信赖的深度,然后将图像特征投影到BEV空间。然而,深度估计仍然会给检测头带来定量误差。因此,作者建议通过准确的深度估计来改进多视图3D目标检测。
单目深度估计
单目深度估计对于场景理解和3D重建很重要。但估计单目密集深度是一个不适定问题。为了克服这个问题,许多工作试图提取单目线索,例如纹理变化、亮度和颜色、遮挡边界、表面、目标大小和位置。早期工作利用马尔可夫随机场(MRF)及其具有手工特征的变体来估计深度(Zhuo et al. 2015; Saxena, Sun, and Ng 2009; Liu, Salzmann, and He 2014)。最近,基于学习的方法在单目深度估计任务中达到了最先进的水平。DORN(Fu et al. 2018)设计了一个普通的回归损失,采用增加间距的离散化 (SID) 策略来离散化深度。他们采用多尺度网络结构来提取多层次的特征。此外,Adabins(Bhat、Alhashim 和 Wonka 2021)通过自适应划分深度bin,将此问题表述为分类任务。更重要的是,室外单目深度估计还可以依靠地面来预测深度,这对于3D目标检测有很大好处。MonoGround(Qin和Li,2022)发现了地面在深度估计和3D目标检测中的重要性。他们引入地平面作为帮助深度估计的先验。
立体深度估计
根据相机的几何关系,基于立体的算法可以分为:立体匹配、Multi-view stereo和Temporal stereo方法。立体匹配方法估计同一平面上两个相机之间的视差。GCNet(Kendall et al.2017)首先将4D cost volume引入立体匹配,并使用soft argmin操作找出最佳匹配结果。GCNet的许多变体已经被提出,例如PSMNet(Chang and Chen,2018)、GwcNet(Guoet al.2019)、GANet(Zhang et al.2019)、AANet(Xu和Zhang,2020)和ACVNet(Xu et al.2022)。Multi-view stereo将立体匹配的相机设置扩展到任意位置。开创性的MVSNet(Yao et al.2018)使用可微同源构建cost volume。R-MVSNet(Yao et al.2019),AA-RMVSNet(Wei et al.2021),CasMVSNet(Gu et al.2020),PatchmatchNet (Wang et al.2021a),Uni-MVSNet(Penget al.2022))使用循环正则化或粗到细策略改进MVSNet。Temporal stereo方法估计来自单个移动摄像机的多帧图像的深度。ManyDepth(Watson et al.2021)、MonoRec(Wimbaueret al.2021)、DepthFormer(Guizilini et al.2022)和MaG-Net(Bae,Budvytis,and Cipolla 2022)编码一个序列图像为4D cost volume,类似于Multi-view stereo。受上述方法成功的启发,作者设计了基于立体的深度估计框架来学习用于多视图3D目标检测的高质量BEV表示。
方法
作者方法的整体架构遵循多视图3D目标检测的一般设计(Li et al.2022a)。它由四个主要阶段组成:图像特征提取、深度估计、视图转换和3D目标检测。如下图所示:
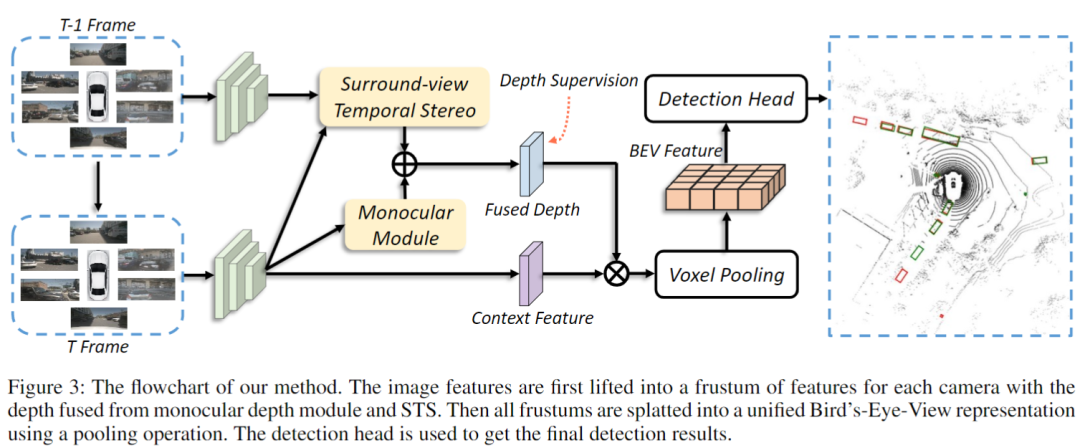
(1)图像特征提取阶段,使用一个图像主干从N个视图图像中提取2D特征。(2)深度估计阶段利用环视temporal stereo(STS)和单目深度模块生成融合深度。(3)视图转换阶段首先利用前面得到的深度信息将图像特征提升为特征平截头体,然后使用pooling操作将所有特征平截头体分解为BEV网格,将2D特征转到BEV空间。(4)检测头根据BEV特征预测类别、3D边界框位置、偏移量和其他属性。由于这项工作旨在提高深度估计的质量,因此在接下来的部分中,作者主要关注深度估计阶段。
STS
作者提出的Surround-view Temporal Stereo(STS)的整体架构如下图所示: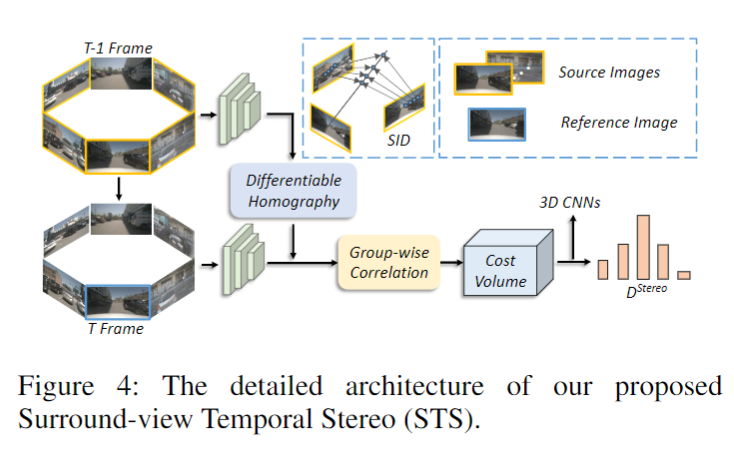
Cost Volume 建立:基于temporal stereo的深度估计的关键部分是将前一帧的特征warp到当前帧,以探索跨时间的几何约束(Wang、Pang 和 Lin 2022)。然而,传统的temporal方法只能探索同一相机内的时间一致性。而STS允许有ego-motion的跨视图交互,以实现更好的深度估计。
具体来说,作者首先使用以下单应矩阵,根据时间戳 t 处的第i个参考图像中的深度假设P_ref(i)计算在时间戳 t-1 处的所有源图像对应的采样位置P_source(i,j)。单应矩阵如下:
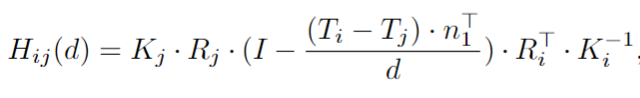
其中Hij(d)是前一帧t-1的第j个源特征图与采样深度d帧中第i个图像的参考特征图之间的单应矩阵。Tj和Rj是从时间戳t-1处的第j个图像的相机坐标到时间戳t的ego坐标的平移和旋转矩阵。Ti和Ri是从参考图像的相机坐标到其ego坐标在时间戳t处的平移和旋转矩阵。Kj和Ki是相机的源图像和参考图像的内在参数。n1表示参考相机的主轴。CD'是减少的深度假设数量,仅用于时间深度估计部分,以节省内存成本。所以,P_source(i,j)可以表示为:
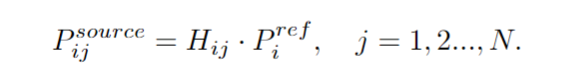
由于参考图像中的一个像素只能出现在部分源图像中,因此P_source(i,j)中的大多数坐标都是无效的。因此,作者只对具有有效坐标^P_source(i,j)的源帧中的特征进行采样。这也是 STS 和一般的temporal stereo技术之间的主要区别。最终,通过^P_source(i,j)获得了扭曲的特征体积Vi。接下来,作者采用分组相关相似性度量(Guo et al. 2019)来构建轻量级cost volumes。具体来说,时间t处的参考图像特征Fi通道和体特征Vi中的特征Fv通道,先被分成G个组,然后通过下面公式按组计算第g个特征组的相关性:
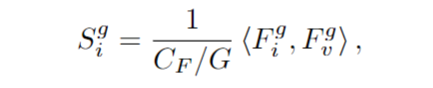
其中〈·,·〉是内积。所有的 G组相关性都被打包成一个 G个 通道的cost volume Ci。作者使用三个核大小为 1×1×1 的 3D 卷积来规范cost volume,并使用平均池化来调整深度logits的shape,从Hn×Wn变为Hm×Wm。此外,作者通过简单地复制原始深度特征值将深度通道数量从 CD' 扩展到CD,以获得来自 STS D_stereo(i)的最终深度logits。因此,STS的深度shape与单目深度对齐,便于后续的深度融合技术。
深度采样:常见的深度估计采用均匀采样的方法。但它不适用于基于立体的深度估计。将均匀采样的深度点投影到另一个视图后,相邻点之间的距离会随着深度值的变化而变化。特别是对于近距离的点,它们的投影对应物会非常稀疏,这将导致没有点落在目标的正确位置。如下图所示

它可能无法对源帧上的对应点进行采样,尤其是在基于立体的深度估计中较近的目标。在这种情况下,基于立体的方法表现不佳。因此作者使用深度离散化策略,命名为 Spacing-Increasing Discretization(SID) (Fu et al.2018):

其中Dmin和Dmax代表深度范围的开始和结束。SID 策略在对数空间中采样深度,这对于环视图temporal stereo模块的近距离采样点有很大帮助。
单目深度学习及深度融合
由于temporal stereo无法处理无纹理区域和移动目标,因此作者保留了(Li et al. 2022a)中的单目深度模块。在 BEVDepth 之后,单目深度模块接受来自主干网的特征,下采样因子作为其输入,然后利用相机感知深度估计来预测单目深度D_mono(i)。
对于深度融合,作者简单采用了一种“element-wise sum”策略,因为它简单但有效。具体来说,将单目深度logits D_mono(i)和时间深度logits D_stereo(i)相加,并使用Softmax函数σ得到最终的深度概率:
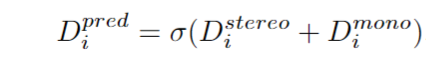
作者将点云投影到图像平面以获得深度ground-truth,并使用Binary Cross Entropy Loss训练深度模块。
实验
作者使用nuScenes数据集,作者使用最先进的多视图 3D 检测 BEVDepth (Li et al. 2022a) 和 ResNet-50 作为基线模型,并在它们的基础上应用STS。在 BEVDepth 之后,作者将 256×704设置为基本实验分辨率,并使用关键和第四个sweep图像作为输入。深度channels默认设置为 112。作者还采用了数据增强,如图像裁剪、缩放、翻转、旋转和 BEV 特征缩放、翻转和旋转。作者使用带有 EMA 的 AdamW 作为优化器。消融实验中,在不使用 CBGS(Zhu et al. 2019)策略的情况下以 64 的batch size大小训练模型 24 个 epoch,而基线使用 CBGS 训练。用于立体匹配和单目深度的默认特征分别是stride=16 和stride=4。
结果见下表:
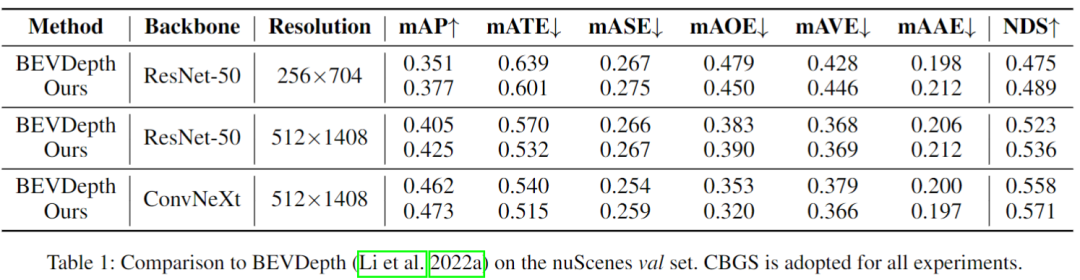
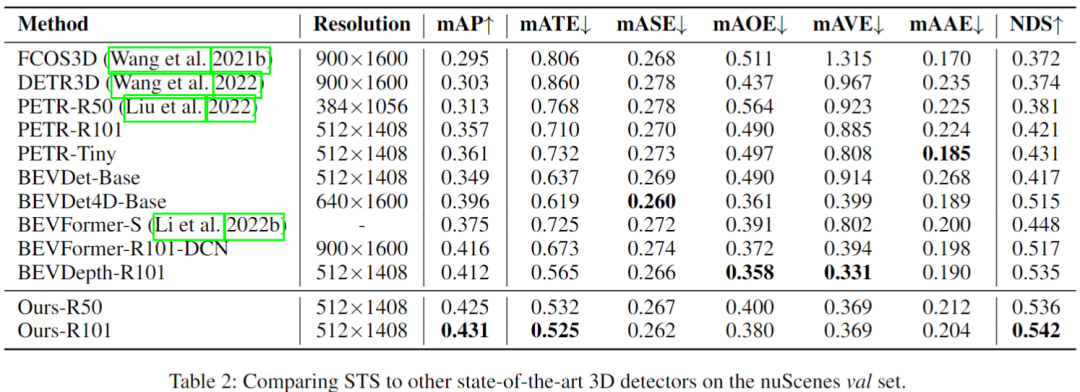
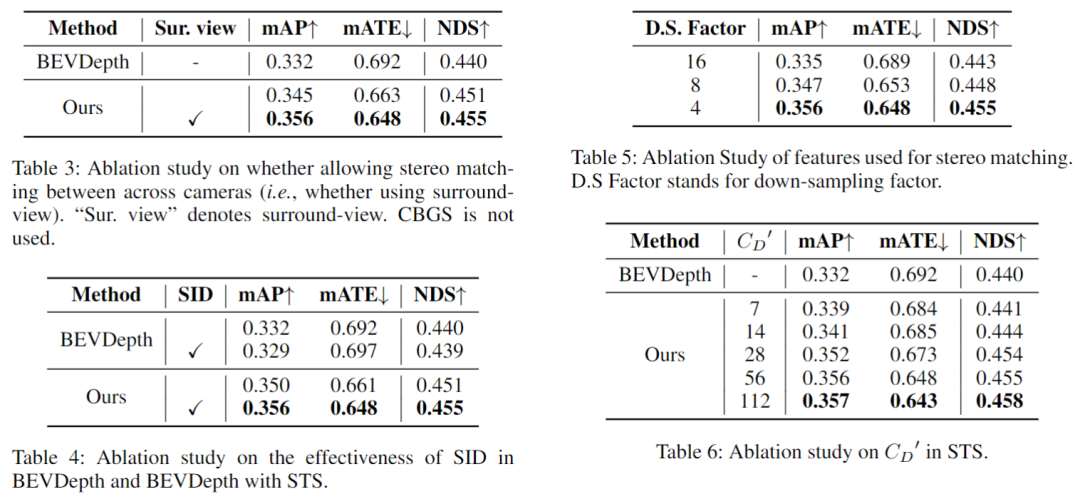
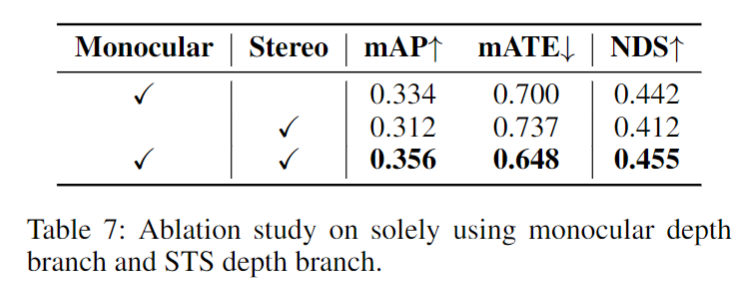
消融实验发现,不用环绕视图的话,将减少近一半的增益,所以环视引入到temporal stereo是很有必要的;SID在STS中也有效果,且在近中距离有优势;不同分辨率的特征对STS有增益效果;随着深度bin的个数增大,性能会提升,当它大于56时,这个因素带来的提升会饱和。因此作者将STS的bin设置为56,以平衡精度和内存成本。融合单目和STS的深度在mAP和NDS中的性能提高了约2.2%和1.3%。具体见下图及表。
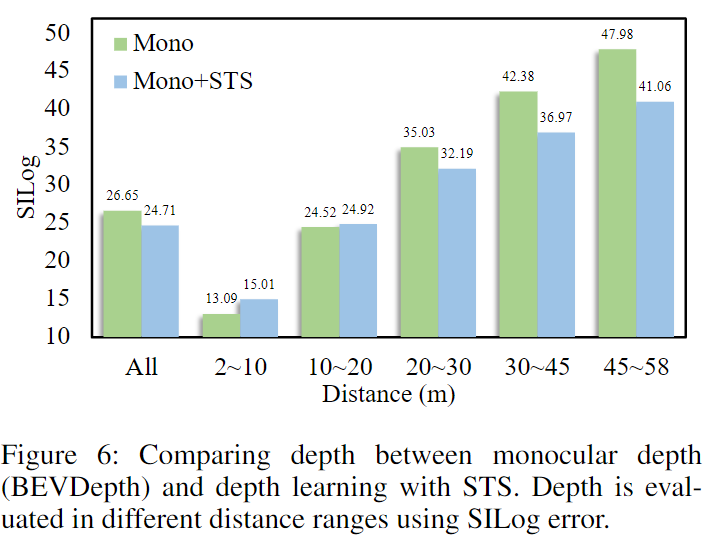
在nuScenes上,不同距离目标的提升效果对比,在中远距离(21-58m)上,STS具有优势,在远距离上使用SID没有增益。
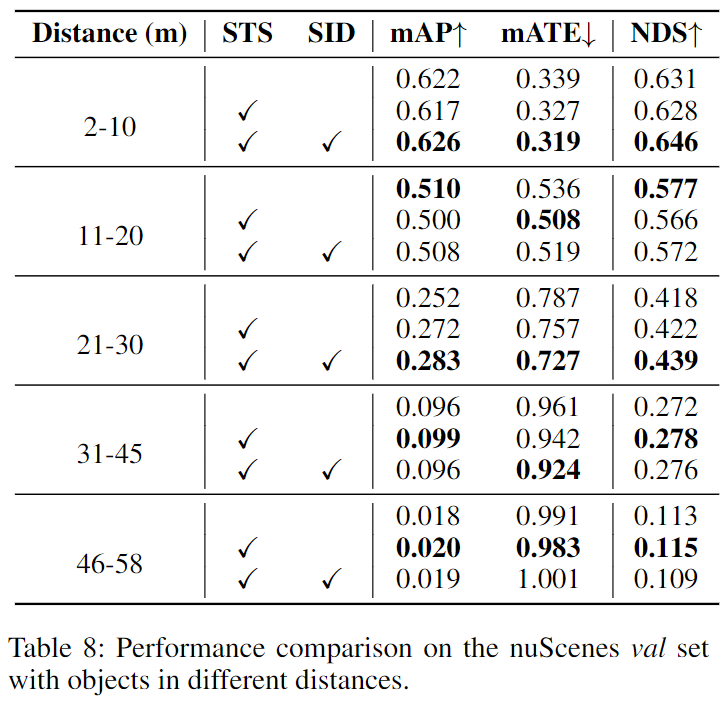
STS与单目深度(BEVDepth)在距本车不同距离的深度估计性能比较:
总结
在本文中,作者介绍了用于多视图 3D 目标检测的环视temporal stereo(STS)。STS 的核心思想是利用temporal stereo技术进行多视图 3D 目标检测,将所有摄像机的视野视为一个统一的视图。作者还利用非均匀深度假设来更好地利用几何对应来学习真实世界的尺度深度。此外,作者为运动物体和无纹理区域的最终密集深度分布结合了单目立体深度融合机制。nuScenes 的实验结果证明了其在多视图 3D 检测中的有效性。
参考
[1] STS: Surround-view Temporal Stereo for Multi-view 3D Detection
 关注公众号
关注公众号
 计算机视觉研究院
计算机视觉研究院
 集智书童
集智书童
 极市平台
极市平台

 Jack Cui
Jack Cui