2026-01-27 14:16:00
2026-01-27 14:16:00
智猩猩AI整理
编辑:没方
强化学习(RL)显著提升了大型语言模型(LLM)智能体在具有可验证结果的任务(如数学推理和代码生成)上的表现。但在解决方案众多的开放域智能体任务(例如复杂的旅行规划)上仍面临挑战。由于这类任务缺乏客观的标准答案,近期研究采用LLM-as-Judge范式,对模型输出进行逐点标量打分,但这种方式存在判别崩溃问题:开放域任务主观性强,奖励模型难以像数学题那样给出精准的绝对分值。随着策略模型能力提升,生成的回答质量普遍提高(例如都在 0.8-0.9分之间)。此时,细微的质量差异远小于评分噪声,导致真实优势信号被掩盖。模型不仅无法继续优化,甚至可能因错误梯度而退化。
为应对上述挑战,通义DeepResearch联合高德提出一种强化学习新范式ArenaRL,该方法通过基于锦标赛的相对排序机制取代不稳定的逐点标量奖励,以实现鲁棒的策略优化。研究团队引入种子单败淘汰赛方案,以O(N)的计算复杂度,达到了与全成对比较(O(N²) 计算复杂度)相当的优势估计精度。为填补开放域智能体训练与评测数据的空白,研究团队构建并开源了Open-Travel与Open-DeepResearch两大基准,并开源了完整的 RL 训练集与测试集。大量实验表明,ArenaRL 显著优于标准强化学习基线方法,使LLM智能体在复杂现实任务中生成的解决方案更具逻辑严谨性和鲁棒性。

论文标题:ArenaRL: Scaling RL for Open-Ended Agents via Tournamentbased Relative Ranking
论文链接: https://arxiv.org/abs/2601.06487
GitHub: https://github.com/Alibaba-NLP/qqr
HuggingFace: https://huggingface.co/papers/2601.06487
01 方法
为从根本上解决判别崩溃问题,研究团队借鉴决策理论中成对偏好判断比逐点量化评估更具稳定性的经典认知,主张从逐点标量评分向组内相对排序的范式转变。
ArenaRL 让智能体针对同一指令生成一组候选方案,构建一个微型“竞技场”。系统不再问“这条轨迹得几分?”,而是问“哪一条更合理、更符合用户意图?”
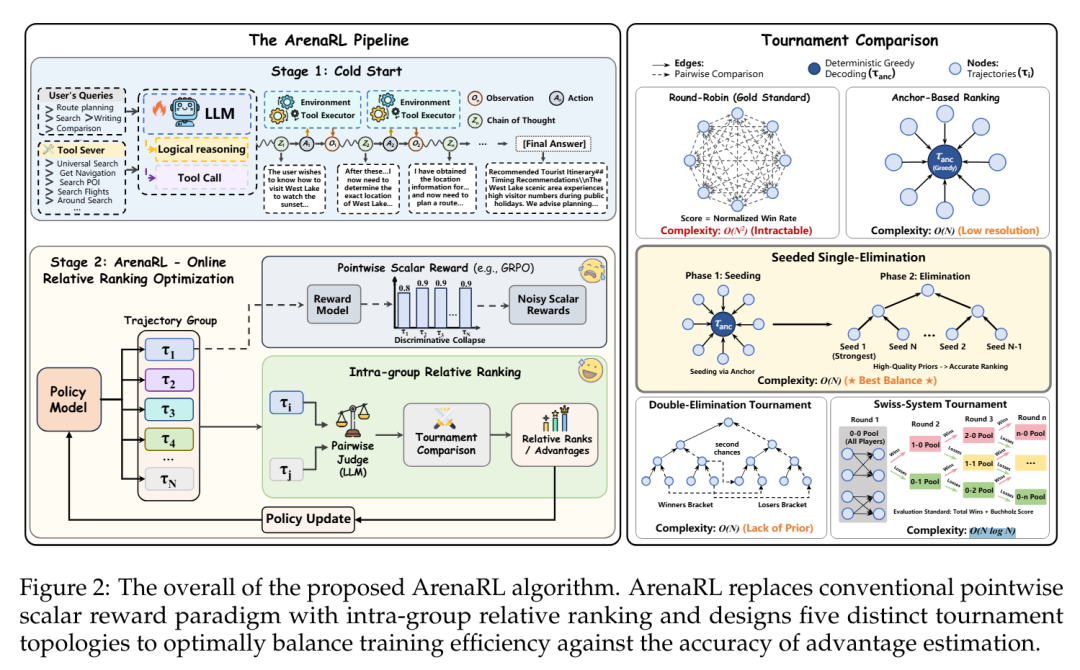
这种成对比较将奖励建模重构为组内相对排序问题,并通过分位奖励映射将离散排名转化为归一化优势信号。相比绝对分数,相对排序天然更能抵抗噪声,敏锐捕捉高质量轨迹间的细微差异,有效规避了训练后期的判别崩溃。
将成对偏好优化扩展到开放域智能体任务时,一个核心瓶颈是高昂的计算成本:虽然穷举比较能产生精确排序,但O(N²)计算复杂度对于在线训练(online training)难以承受。
为了寻找效率与准确率的最佳平衡点,研究团队系统性地对比了多种竞技拓扑,如下表所示:
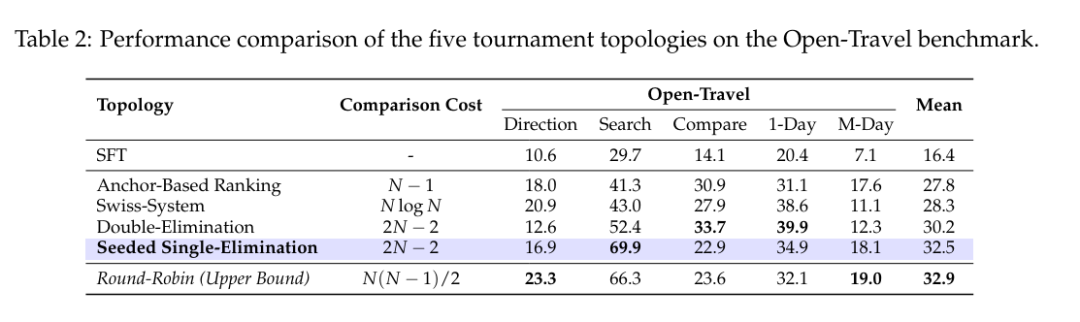
全量循环赛(Round-Robin):让所有候选方案两两对决。这是评估的理想基准,但O(N²)指数级的计算复杂度使其无法应用于大规模在线训练。
瑞士轮(Swiss System)与双败淘汰(Double-Elimination): 这类赛制虽比全量循环快,但仍存在局限:瑞士轮复杂度较高(O(NlogN));而双败淘汰虽接近线性复杂度,但在缺乏高质量种子预排序时,容易受随机性影响,排序保真度不足。
基于锚点的排序(Anchor-Based Ranking):虽然也将复杂度降低至O(N),但它仅将所有候选方案与一个固定的基准(Anchor)进行单点比较。这种方式缺乏候选方案之间的直接博弈,难以分辨高质量方案之间的细微优劣,即论文所述的分辨率缺失(Loss of Resolution),导致排序分辨率受限。
针对上述痛点,ArenaRL 采用“种子单败淘汰赛”架构:通过引入贪婪解码生成的基准轨迹作为质量锚点,对候选样本进行快速初筛预排序,确立种子顺位。这有效防止了高质量样本在早期轮次中意外撞车。随后,基于种子顺位进行二叉树式的单败淘汰赛。
该设计将计算复杂度降至线性O(N),其优势估计准确率能够高度逼近全量循环赛,实现了训练效率与效果的最佳平衡。
开放域智能体的优劣不仅取决于最终答案,更取决于推理规划过程。ArenaRL 引入了过程感知的评估机制,不仅对比结果可靠性,同时审查思维链的逻辑连贯性及轨迹中工具调用的有效性。
同时,为了消除大模型作为裁判时的位置偏见,采用双向评分协议,确保每一场对决的评估结果都是公正且细粒度。
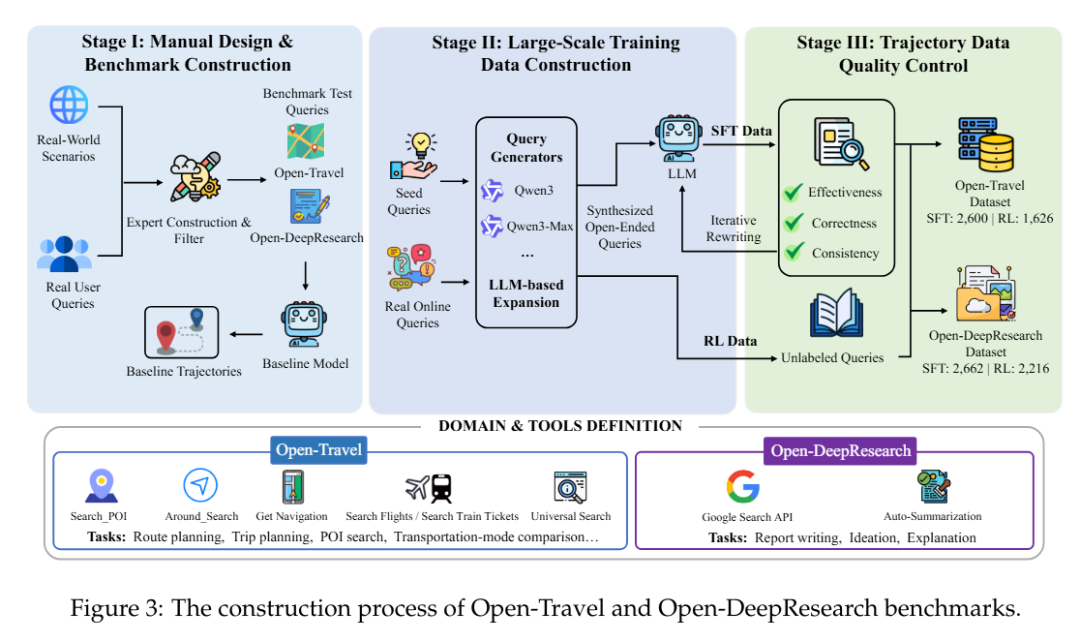
为填补开放域智能体训练与评测数据的空白,研究团队构建了两大基准:
(1)Open-Travel:专注于智能体模糊意图理解、多途经点规划、时空约束权衡等5类任务。
(2)Open-DeepResearch:着重考察智能体在真实互联网环境中自主信息检索与报告生成的能力。
与传统仅提供测试集的基准不同,这两个基准提供了从监督微调→ 强化学习训练 → 多维度自动化评估的完整流程,为学界建立了可复现的基础设施。
02 评估
研究团队在 Open-Travel、Open-DeepResearch 以及通用写作任务上对 ArenaRL 方法进行评估。
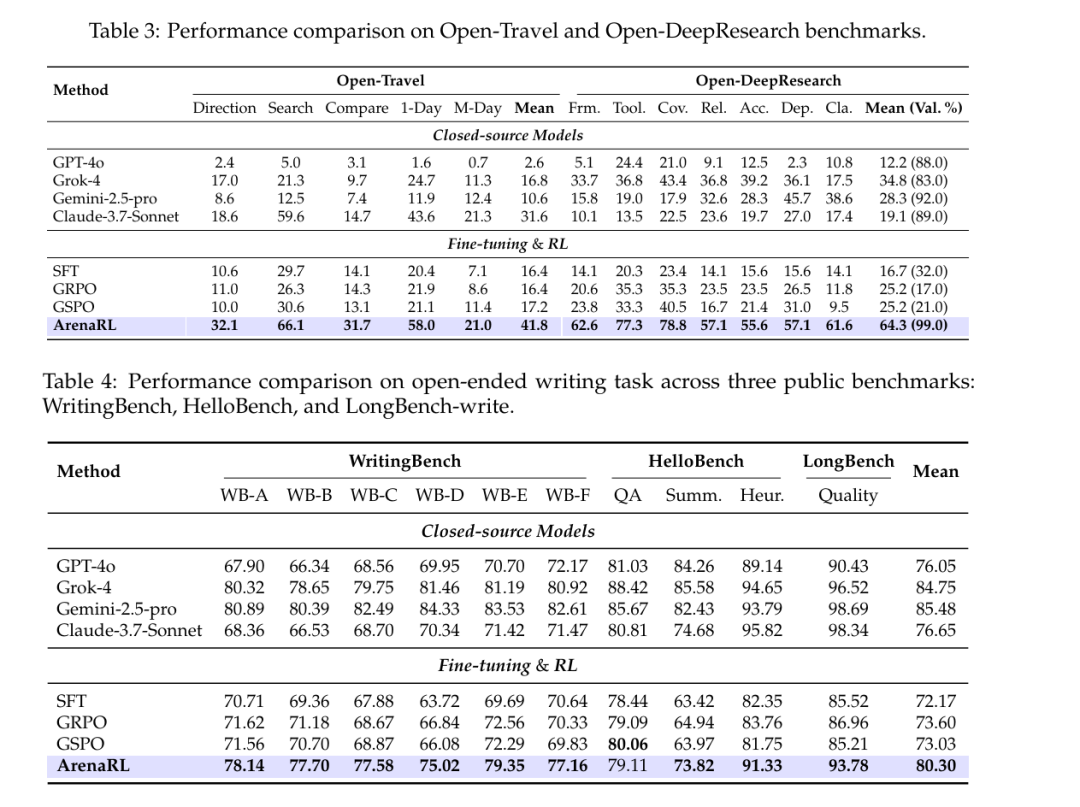
如表 3 所示,ArenaRL 在两个开放域智能体基准上均展现出卓越性能,显著优于四个强大的闭源模型。在 Open-Travel 基准上,ArenaRL的平均胜率达41.8% ,大幅超越 GRPO(16.4%)和 GSPO(17.2%)。在 Open-DeepResearch 基准上,ArenaRL 不仅达到了 64.3% 的胜率,还实现了 99% 的有效生成率(Val. %)。相比之下,基线方法在任务完成度方面表现不佳:SFT训练的模型有效生成率仅为 32%;尽管 GRPO 和 GSPO 在平均胜率略有提升,但其有效生成率甚至低于 SFT 基线。
这些结果表明,标准逐点奖励方案(如 GRPO 和 GSPO)存在一个关键局限性:对于涉及复杂工具调用的长程任务,给单条轨迹分配标量分数往往无法捕捉策略的细粒度改进,且容易受到长度偏好等虚假优势的干扰。相比之下,ArenaRL 基于比较的奖励信号提供了更具判别力的梯度方向,有效引导策略在庞大的搜索空间中向更鲁棒的规划与推理能力演化。
表4进一步验证了 ArenaRL在写作任务上的泛化能力。在三个基准测试中,ArenaRL 的综合平均分大幅领先,分别比 GRPO 高出 6.70%,比 GSPO 高出 7.27%。此外,ArenaRL 还超越了GPT-4o 和 Claude-3.7-Sonnet,进一步彰显其优越性。实验结果表明,ArenaRL不仅适用于工具增强型智能体,还能系统性地增强模型的推理与表达能力,适用于更广泛的开放式生成任务。
ArenaRL 不仅在学术基准上领先,更在高德地图真实业务场景中完成落地验证。
确定性POI搜索:准确率从75%提升至83%。在规则明确、结果精准性要求极高的 POI 搜索场景中,ArenaRL 展现了对刚性约束的出色适应能力。这一结果证明了,即使在规则确定的场景下,锦标赛机制也能敏锐捕捉高质量结果之间的细微优劣,从而推动模型性能突破瓶颈。
复杂开放式规划:满意度指标从69%提升至80%。面对真实场景中的复杂模糊需求,例如:从上海徐汇出发,周末想找一条人少有遮阴可推婴儿车的城市绿道,途中顺路找一家低糖面包店买点心,再去一家可以预约包间的本帮菜馆,整段路线希望尽量不走台阶,傍晚前回到地铁站。
ArenaRL 训练的模型展现出更强的逻辑自洽性与多约束权衡能力,在时间、成本、用户偏好等多重维度间找到更优平衡点,显著提升了复杂长尾场景的用户体验。
03 展望
研究团队希望 ArenaRL 能为大家提供一套切实可用、可复现、可扩展的开放域智能体进化方案。让 AI 在没有标准答案的真实世界里,依然能持续学习、不断逼近更优解。

 关注公众号
关注公众号