







 2022-09-19 10:05:04
2022-09-19 10:05:04

Vision Transformer及其变体在各种计算机视觉任务中展示了巨大的潜力。但传统的Vision Transformer通常侧重于coarse level的全局依赖,这在全局关系和Token级别的细粒度表示方面存在学习挑战。在本文中,将Multi-scale Attention Fusion引入到Transformer(MAFormer) 中,它探索了用于视觉识别的双流框架中的局部聚合和全局特征提取。作者开发了一个简单但有效的模块,通过在Token级别学习细粒度和粗粒度特征并动态融合它们来探索Transformer在视觉表示方面的全部潜力。多尺度注意力融合 (MAF) 块包括:
局部窗口注意力分支,学习窗口内的短程交互,聚合细粒度的局部特征;
通过一种新颖的全局下采样学习(GLD)操作提取全局特征,以有效地捕获整个图像中的远程上下文信息;
一个融合模块,通过注意力探索两个特征的整合。
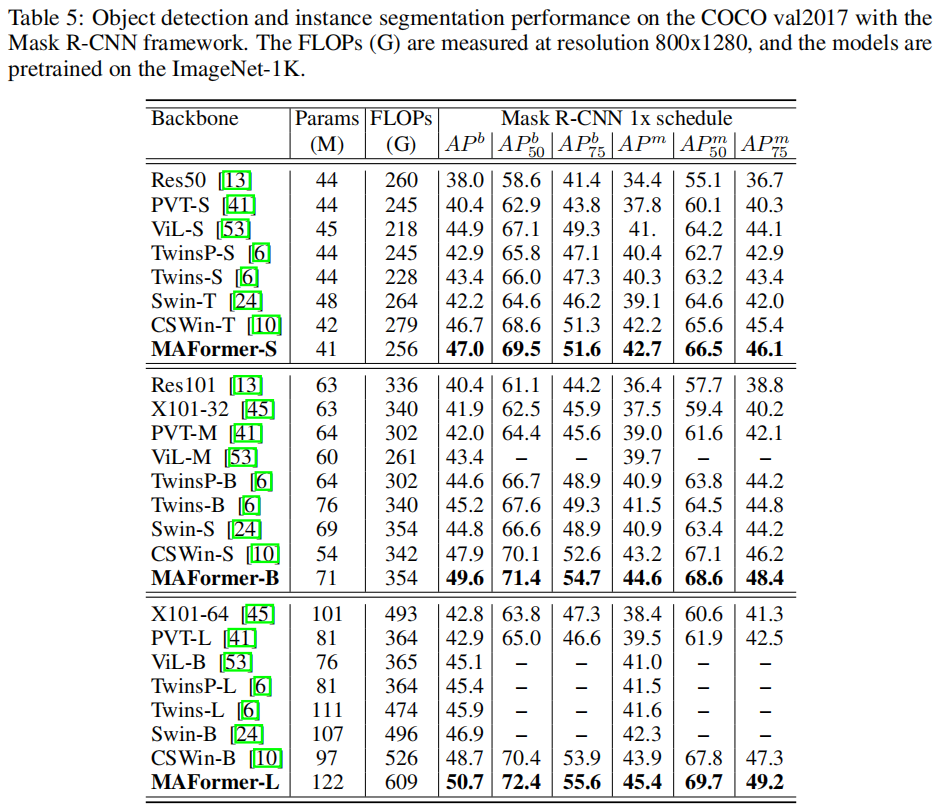
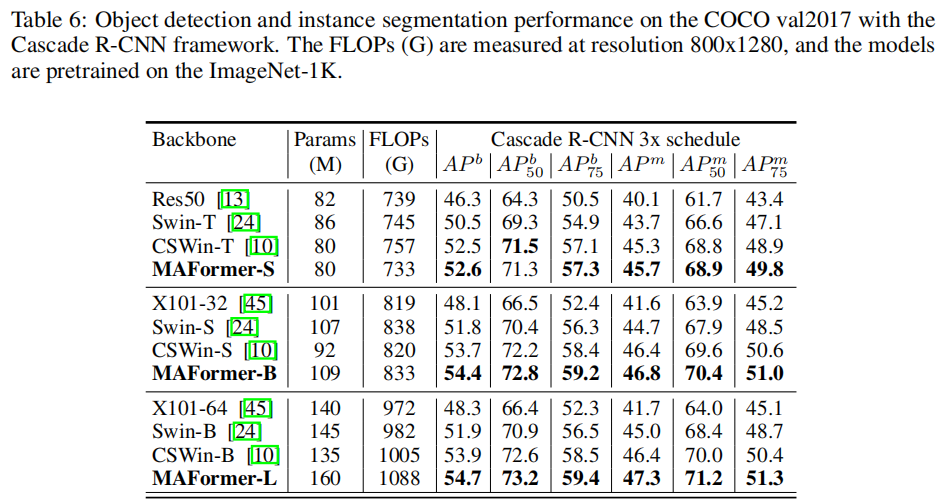
MAFormer在常见的视觉任务上实现了最先进的性能。特别是,MAFormer-L在ImageNet上的Top-1准确率达到 85.9%,分别超过CSWin-B和LV-ViT-L1.7% 和 0.6%。在MSCOCO上,MAFormer在目标检测方面的mAPs比现有技术CSWin高 1.7%,在具有相似大小参数的实例分割方面比现有技术CSWin高 1.4%,证明了MAFormer成为通用骨干网络的潜力。
本文方法
1、概览
本文提出了多尺度注意力融合机制,以在Token级别提取细粒度和粗粒度特征并动态融合它们,形成通用vision transformer主干,称为MAFormer,提高各种视觉任务的性能。
图 1(a) 显示了 MAFormer 的整体架构。它以图像 作为输入,其中 W 和 H 表示输入图像的宽度和高度,并采用分层设计。通过降低特征图的分辨率,网络可以捕获不同阶段的多尺度特征。
将输入图像划分为Patch并执行Patch Merge,接收具有 C 个特征通道的 H/4 × W/4 visual tokens。tokens流经 MAF 块的两个阶段和原始 Vision Transformer 块的两个阶段。在每个阶段,MAFormer 按照惯例采用了一个Patch Merge层,它将特征图的空间大小下采样 2 倍,同时增加了特征通道维度。
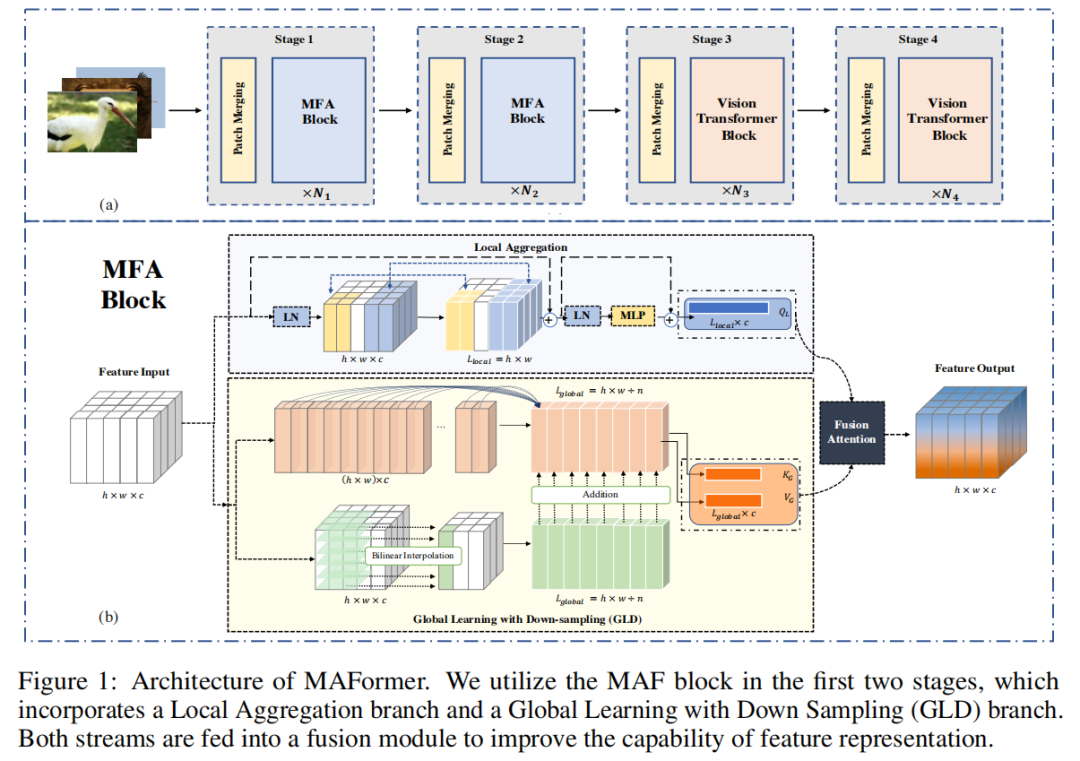
根据最近对特征表示的研究,像 ViT 这样的vision transformer在其较低层中局部和全局参与,但主要关注较高层中的全局信息。根据该模式,在 MAFormer 的前两个阶段合并了多尺度特征表示,而在后两个阶段,使用了原始的vision transformer Block,其中降低了特征的分辨率和完整的计算成本注意力变得负担得起。
2、多尺度注意力融合模块
Local aggregation
以往的混合网络利用cnn提取局部特征,并进一步集成到一个Transformer分支中。然而,这种方法可能存在卷积和自注意力之间不匹配的风险。
在MAF中避免了不兼容性,并探索了使用基于局部窗口的多头注意力机制作为细粒度表示。考虑输入,局部聚合定义为:
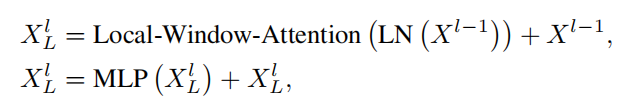
其中,为第1个Transformer block的输出。
Global feature extraction
虽然局部窗口自注意力方法取得了优异的性能,但它们只能捕获窗口级信息,而无法探索它们之间的依赖关系。此外,由于对粗粒度上下文信息的使用不足,现有的方法在全局依赖关系提取方面仍然受到挑战。因此,对全局依赖关系的有效捕获是模型表示的构成部分。
为了解决这些问题,作者引入了一个带有降采样的全局学习(GLD)模块来从一个大输入中提取全局信息。为此,首先利用一个与特征输入完全连接的单个神经元层。在不删除任何维度的情况下,它输出一个动态学习的降采样上下文抽象。
如图1(c)所示,输入首先展平为,其中L=H×W。然后由一个全连接层全局提取,缩小到比例N。
在实验中调整了几个N和0.5是最优的值,在MAFromer中设置为默认值。此外,通过位置嵌入将输入的Token级位置信息编码到全局表示中。如图1(c)所示,Pos操作采用分层双线性插值作为测度,FC表示为全连接。
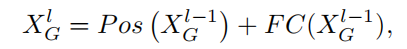
其中,为第1个Transformer block的全局分支输出。
Multi-scale attention fusion (MAF)
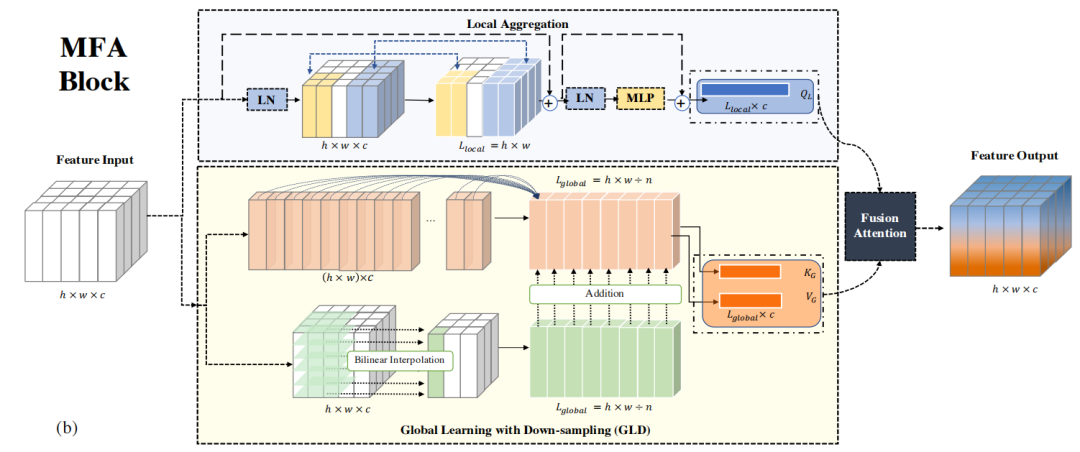
作者开发了两种类型的双流多尺度表示,如图2所示。首先,在局部表示之上提取全局依赖关系作为一种增强,旨在提供跨局部窗口的信息流。如图2(b)所示,GLD模块接受局部窗口注意力的输出,并将全局表示与局部表示重新融合。然而,这种方法只能捕获局部属性之间的全局相关性,而不能从输入中获取。
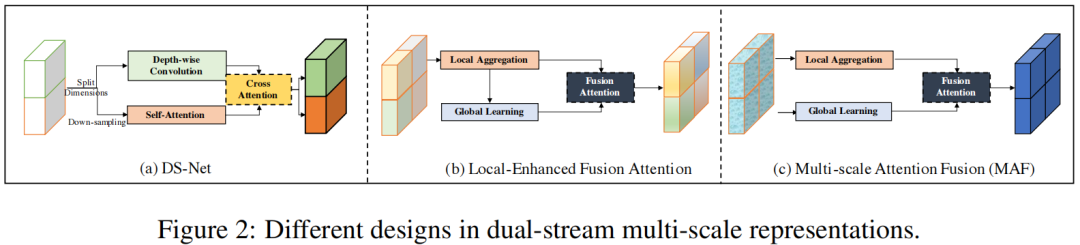
因此,作者提出了多尺度注意融合(MAF)度量,直接和分别提取输入的局部和全局尺度。这两种信息流通过注意力输入融合块,如图2(c)所示通过这种方式,MAF块可以捕获每个局部-全局Token对之间的相关性,并提示局部特征自适应地探索它们与全局表示的关系,使它们自己更具代表性和信息性。
给定提取的局部特征局部特征和全局特征,将多尺度注意融合定义为:
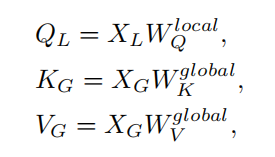
其中,,是学习超参数矩阵。然后计算每对和之间的多尺度注意力融合(MAF):

实验
消融实验
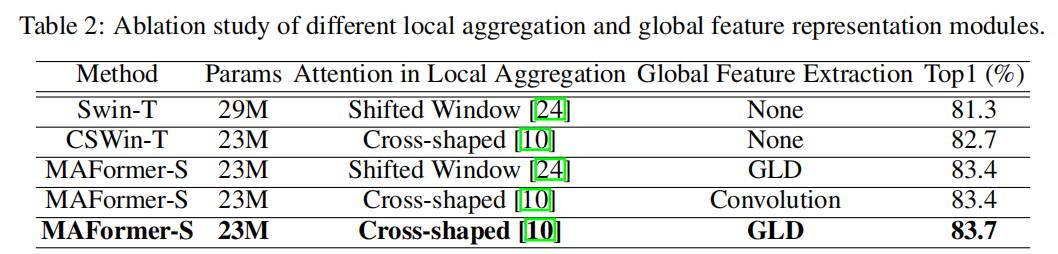
Local aggregation与Global feature extraction
Fusion structure analysis

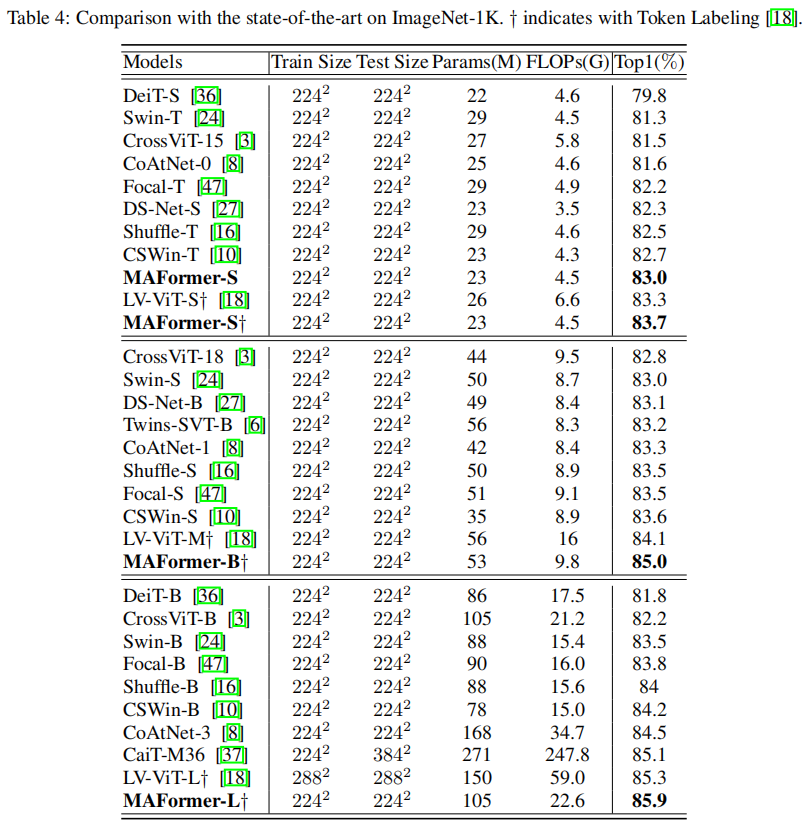
图像分类
目标检测
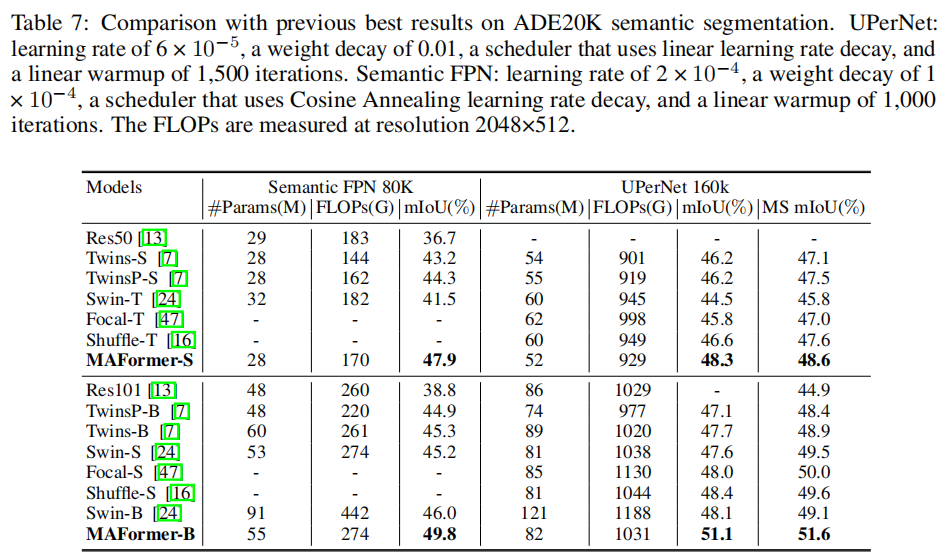
语义分割
参考
[1].MAFormer: A Transformer Network with Multi-scale Attention Fusion for Visual Recognition

 关注公众号
关注公众号
 计算机视觉研究院
计算机视觉研究院
 极市平台
极市平台

 Jack Cui
Jack Cui