2026-04-11 11:31:00
2026-04-11 11:31:00
智猩猩AI整理
编辑:宁宁
大模型正在从“会回答问题”走向“会完成任务”。但真正的 Agent 任务,并不是一次性给出答案,而是要在环境里持续观察、推理、行动,再根据反馈修正策略。网页操作、深度搜索、游戏任务、科学实验,本质上都属于这种长时程、多轮决策问题。研究团队指出强化学习本应是训练这类能力的自然路径,但开源社区长期缺少一个能在多种真实环境中统一训练 LLM Agent 的 RL 框架;与此同时,长时交互训练又很容易不稳定,模型常陷入重复动作、无效探索甚至训练崩溃。
为解决这一问题,复旦大学与字节 Seed 等团队提出 AgentGym-RL。这项工作包含两层贡献:(i)提出统一、解耦、可扩展的 Agent 强化学习框架 AgentGym-RL;(ii)在此基础上提出 ScalingInter-RL,通过逐阶段扩展交互轮数的训练方式,稳定提升 Agent 的长时交互能力。研究团队最终在5 类场景、27 个任务上验证了这一思路,并报告其方法训练出的模型在整体评测中已可与 OpenAI o3、Gemini-2.5-Pro 等商业模型相当,部分设置下甚至超过。成果相关论文已被 ICLR 2026 接收。

论文标题:AgentGym-RL: An Open-Source Framework to Train LLM Agents for Long-Horizon Decision Making via Multi-Turn RL
论文链接:https://openreview.net/forum?id=ZgCCDwcGwn
GitHub仓库地址:https://github.com/WooooDyy/AgentGym-RL
数据集来源:https://huggingface.co/datasets/AgentGym/AgentGym-RL-Data-ID
项目主页地址:https://agentgym-rl.github.io/
01 方法
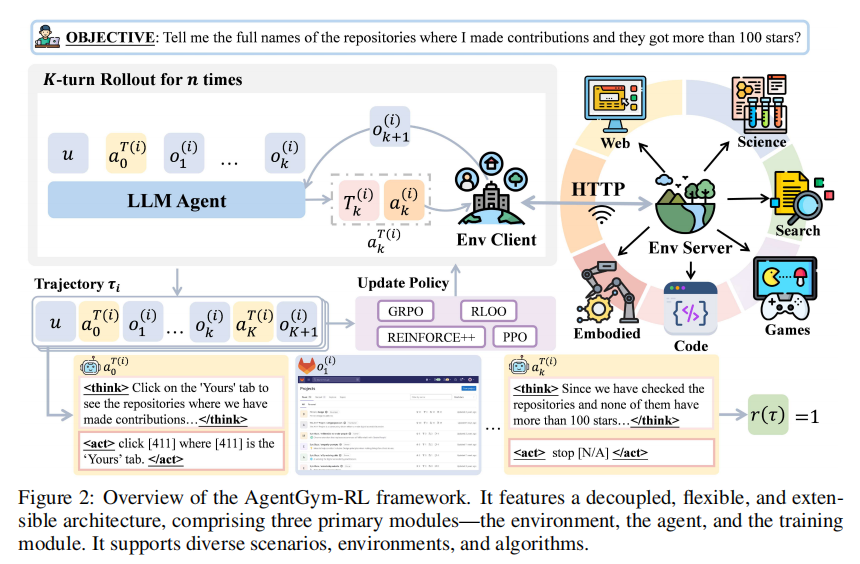
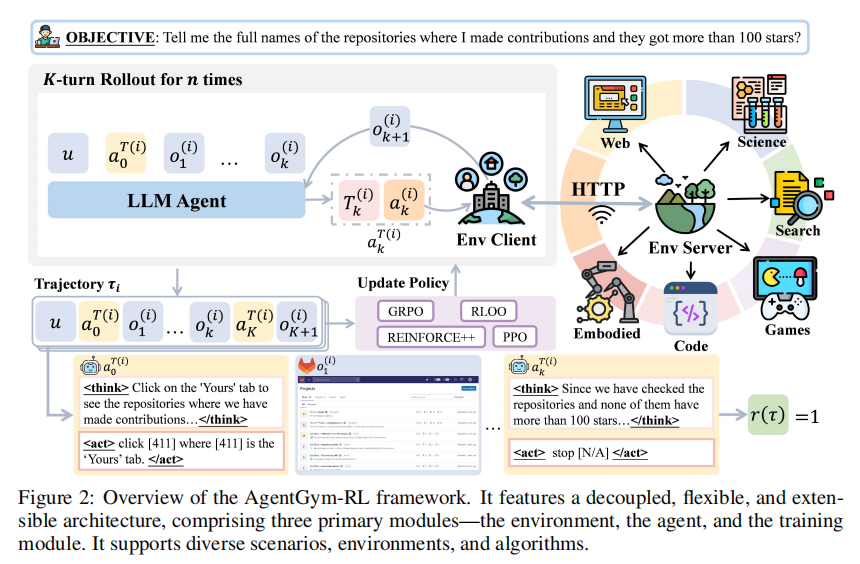
(1) AgentGym-RL:把 Agent 训练拆成三块
研究团队首先把多轮交互任务形式化为一个 POMDP:给定任务指令后,Agent 基于当前状态输出动作,环境返回观察并更新状态,最终根据整条轨迹给出奖励。换言之,优化目标不再是“这句话答得好不好”,而是“这一整串动作最终有没有把任务做成”。在此基础上,研究团队将 PPO、GRPO、REINFORCE++ 等主流策略梯度算法统一纳入框架。
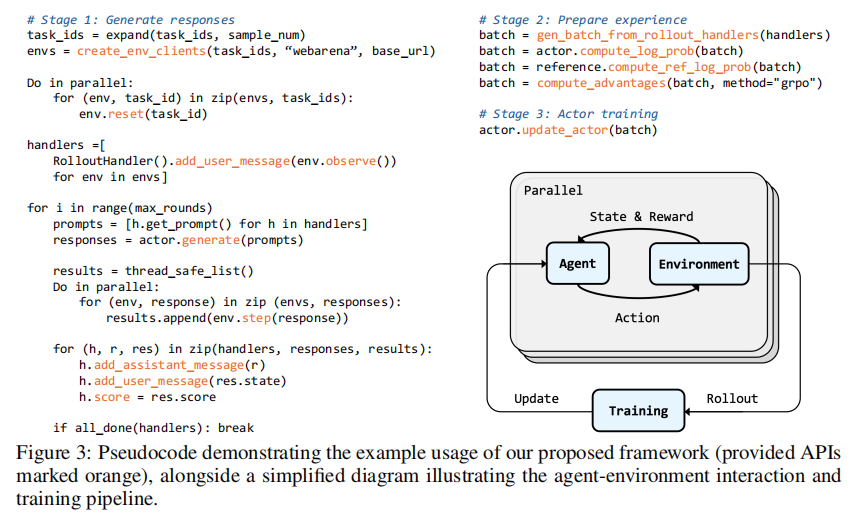
AgentGym-RL 采用非常清晰的三模块设计,如图2所示。
第一是环境模块。 不同环境被封装为独立服务,通过 HTTP 接口与 Agent 通信,支持 /observation、/step、/reset 等操作;同时可部署多个环境副本,以支持并行采样。
第二是 Agent 模块。 它负责完整的 reasoning-action loop:接收环境观察、组织上下文、生成动作,再进入下一轮交互。这个模块本质上承载的是“大模型如何在环境中一步步做事”。
第三是训练模块。 它统一处理 rollout、优势估计、策略优化与奖励塑形。研究团队给出的伪代码很直观,如图3所示:先并行生成多条轨迹,再计算 log prob、reference log prob 和 advantage,最后更新 actor。研究团队不仅提出了概念框架,也给出了完整的训练管线。
从研究基础设施角度看,AgentGym-RL 的价值在于它并不绑定某一个任务,而是覆盖了网页导航、深度搜索、数字游戏、具身任务、科学任务五类场景,对应的代表性环境/基准包括 WebArena、RAG-based environment、TextCraft、BabyAI 和 SciWorld,形成了统一的训练与评测平台。
(2) ScalingInter-RL:先学会短程做对,再逐步扩展到长程交互
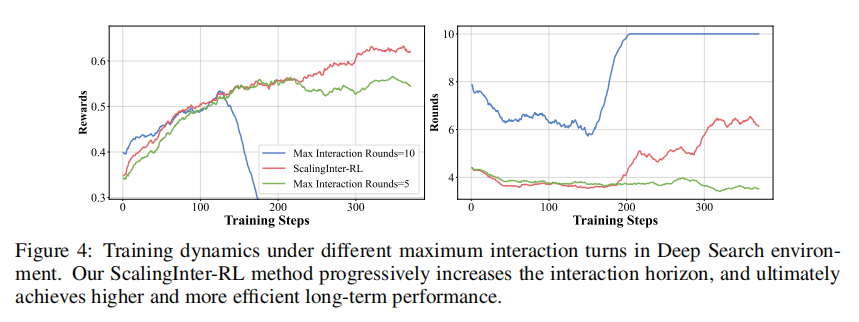
仅有框架还不够,真正的难点在于长时交互训练为什么不稳定。研究给出的观察很有代表性:如果直接允许模型进行很长的交互 rollout,虽然探索更充分,但训练经常会崩;模型会反复执行冗余动作,陷入无效循环。相反,如果把最大交互轮数限制得太短,训练更稳定,但性能上限也随之受限。图 4 展示的正是这种“长 horizon 不稳、短 horizon 不强”的两难局面。
为此,研究团队提出 ScalingInter-RL。它的核心思想并不复杂却非常关键:把交互轮数也做成一种 curriculum。 训练初期,先用较短的交互 horizon,让模型掌握基础策略;随着训练推进,再按照单调递增的 schedule,逐步放宽允许的最大交互轮数。这样,模型先学会“基本会做”,再学会“在更长链路中持续做对”。
研究团队形式化地将其写成一组递增的阶段性 horizon,并说明 horizon 会按一定训练步数逐步更新。研究团队认为这种 staged horizon scaling 同时兼顾了 exploitation 与 exploration:前期以稳为主,后期再鼓励更深层的环境探索,从而在不牺牲训练稳定性的前提下,逐渐获得更强的长时交互能力。
这也是最值得记住的方法点:它不是重新发明 RL 损失,而是重新设计“Agent 应该如何被训练成长”。
02 实验设置与结果分析:这套方法到底有没有用?
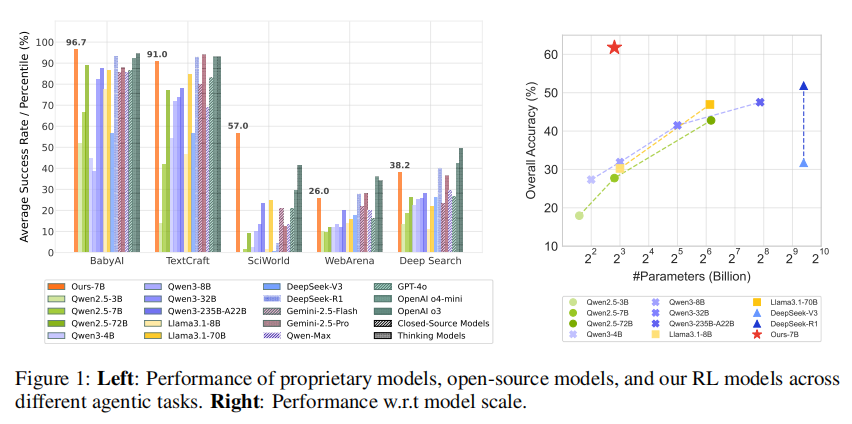
如上图所示,实验覆盖五类场景、27 个任务,主骨干模型是 Qwen-2.5-3B 与 Qwen-2.5-7B,同时与多种闭源模型、强开源模型和搜索类 RL baseline 进行比较,训练和评测均基于 ReAct 范式完成。
主结果非常明确。以 Qwen-2.5-7B 为例,在 AgentGym-RL 框架和 ScalingInter-RL 方法下,平均性能可提升 33.65 个点,并在整体上接近甚至超过部分商业模型。研究团队还强调,ScalingInter-RL-7B 的平均成功率达到 61.8%,显著高于 Llama3.1-70B 的 46.9% 和 Qwen2.5-72B 的 42.8%。这说明在 Agent 任务上,后训练和测试时交互扩展,可能比单纯堆大模型参数更有效。
Deep Search 的结果尤其典型。原始 Qwen2.5-7B-Instruct 的 overall 仅为 18.8,训练成 AgentGym-RL-7B 后升至 34.0,再加入 ScalingInter-RL 后升至 38.3。这不是小修小补而是说明模型的多轮搜索—推理—行动能力发生了实质提升。
从环境差异上看,研究团队也给出了很有价值的分析:RL 在 规则清晰、反馈直接 的环境中提升更大,例如 TextCraft、BabyAI 和 SciWorld;其中 SciWorld 从 1.50% 提升到 50.50%,增幅接近 50 个点。相反,在 WebArena、Deep Search 这类更开放、更嘈杂的环境中,虽然也有收益,但提升相对有限。这意味着,未来 Agent RL 的关键不只是模型和算法,还包括环境反馈能否提供清晰、可归因的学习信号。
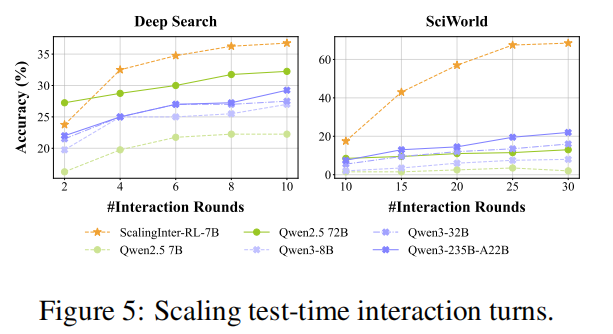
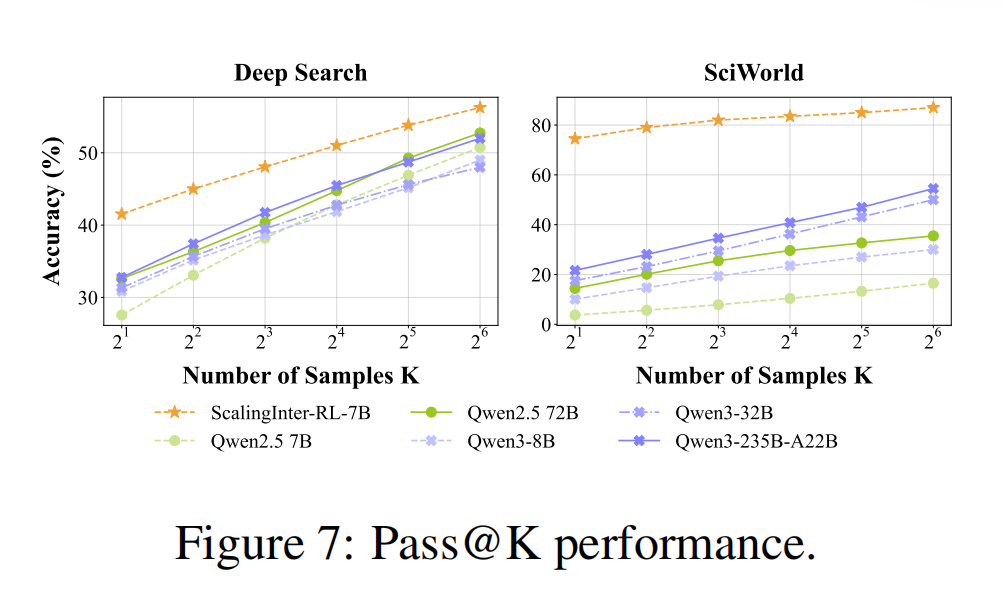
研究团队还做了几组很有说服力的分析实验,如图5、图7所示。
第一,随着测试时允许更多交互轮数,所有模型性能都会提升,但经过 ScalingInter-RL 训练的模型始终领先,说明它确实更擅长长时交互。
第二,在 Pass@K 分析中,随着采样数增加,性能持续提升,而该方法训练出的模型在小采样预算下就已优于基线;研究团队甚至指出,在 SciWorld 上,其 Pass@2 已超过所有 baseline 的 Pass@64。这表明方法不仅提高了上限,也提高了每次 rollout 的有效性。
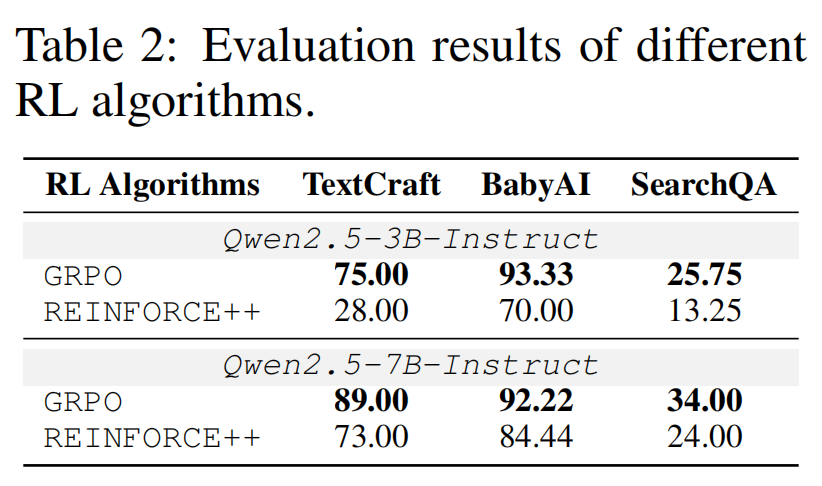
算法比较同样值得关注。研究团队对比了 GRPO 与 REINFORCE++,如表2所示,结果显示 GRPO 在 TextCraft、BabyAI、SearchQA 上均显著更优,甚至出现 3B-GRPO 超过 7B-REINFORCE++ 的现象。研究团队认为原因在于 GRPO 用同一 query 下多条轨迹的平均值作为 baseline,并进一步做归一化,因此更能抑制离群样本带来的高方差梯度。
03 总结
AgentGym-RL 最重要的意义,不只是提出了一个新框架,也不只是拿到了一组更高分数,而是把一个关键问题说清楚了:对 Agent 而言,能力扩展不应只理解为 reasoning scaling,更应理解为 interaction scaling。
在这个逻辑下,研究团队完成了两件事:一是提供了一个可扩展、可复现、跨环境的统一 RL 框架;二是提出了一种简单但有效的训练原则——长时交互能力不是一开始就硬训出来的,而是要通过“从短到长”的课程式训练逐步长出来。

 关注公众号
关注公众号