







 2022-11-10 11::07
2022-11-10 11::07
前言
谷歌最近更新了他们掉渣天的新一代姿态检测模型Movenet: https://www.tensorflow.org/hub/tutorials/movenet
简单来说,这个姿态检测模型可以以非常快的速度跑在CPU,甚至手机端也可以实时运行。这其实并没有什么,毕竟现在很多姿态检测模型可以跑的很快,移动端问题不大。但是这个模型厉害的地方在于,它不是bottomup,也不是topdown,而是基于CenterNet构建的一套基于姿态检测模型,介于二者之间,换句话说,它不是完全的回归模型,避开了很多回归模型带来弊端,同时又保证了精度和速度。
刚好,我们上一篇自建推理框架的文章,讲解了我们已经实现了python的binding。然而有人竟然说我们的框架是一个toy framework,这是不能忍的,。 什么才是toy framework?私以为把人家MNN或者ncnn的代码精简一个版本,然后把一些很好的功能砍掉,就说自己能搞一个推理框架,那才是toyframework。一个toy framework是不可能能够推理YOLO的,不信你可以自己尝试从零构建一套推理引擎,然后推理YOLO得到正确结果,感受一下其中的难度。能把shufflenetv2结果推理正确算我输。当目前我也只看到github上有一位大佬从零购建过一个推理引擎成功推理过YOLO,不过后面感觉就没有更新了。这里面不是说会写一个matmul,会写几个矩阵乘就能把YOLO跑出来的,这里面涉及到框架设计、从训练框架到推理框架的parser、算子的设计、图的解构、无数的细节,你可能错了一个地方,整个图推理就全错了,而且很难找到问题所在。
不过我做这件事情的目的,并不是为了证明我们不是toy framework。从一开始就说了,我们想探索一条不引入ONNX的部署流程,做一个贴近PyTorch原生行为的框架,这是一条鲜有人走过的路,不了解我们的来龙去脉,可以去查看我的 1-7系列文章。
而这一次,我们要走的更远。为了验证我们框架的推理算子完备性,我决定尝试一个更具有难度的模型。
这就是Movenet。
这个模型难不难?我们先来看一下它的解构:

其实模型没啥难点,就是centernet那一套,但是Head有点多,不仅是center又监督,kpts有监督,kpts的headmap有监督,kpts的regression也有监督,以及local的offsets。
其实最复杂的是后处理,这种类型的模型, 后处理通常都极其的复杂。
这样正好,用它来验证我们的框架完备性。
Movenet
关于Movenet不多说,一张图来了解:

他会同事输出一张图片里面人的candidate的热力图,同时对于每一个关节点,又可以通过一个argmax的索引来链接到不同人。这种做法应该是我认为更优的方向。
我曾经尝试过用YOLO来做Pose,使用回归的方式,代码可以参考我的仓库:
https://github.com/jinfagang/yolov7_d2
效果其实还不错的,但是离SOTA还是有一些距离,问题并不是在于我们做法不对,而是你能看到的类似方法的paper里面,他们的精度都是在1000x1200这样的大图上得到的结果。这基本上是得不偿失的。
因此,这条路,似乎走不通,实用性并不高。而Movenet这种套路,能够非常好的权衡检测和关键点回归的精度。而同时有不需要2 stage来浪费那么多的算力。
这也是本文尝试部署这个模型的原因。
总结一下Movenet的优点好了:
• 有单人和多人的版本,不管是单人还是多人,都可以做到很好;
• 不是完全基于rgression,有heatmap作为监督,精度很不错;
• 速度快;
• 简单来说,同时兼顾了topdown的精度以及bottomup的速度;
废话不多说,先来转模型!
啪! 打脸!
Google官方并没有放出pytorch的代码。。 没办法,网上找一些有没有人用pytorch复现的。 但是找了一圈,要么就是结果不对,要么就是没有办法复现官方原版(复用权重),无解,我只能自己动手捣鼓了一下,于是一个pytorch版本就有了:
https://github.com/jinfagang/movenet
网上至少有不下10个movenet,请认准我的版本,开箱即用,其他的基本上都跑不起来的。
谷歌的MoveNet应该是目前最为SOTA的轻量级姿态检测模型。他既不是bottomup,也算是topdown的结构,而是结合了centernet的思想,真正做到端到端,但又不是dense类直接回归的方式,因此被称为下一代姿态检测。我认为这个路线还是非常有前景的。既能保证坚持的精度,又能让关键点得到各种heatmap的裨益。
在实际尝试中,对于非刚体的关键点,用直接回归的方式还是差一点,而dense类的架构天然不适用于heatmap,否则内存占用会很高。MoveNet可以说是解决了这样一系列的问题。在轻量级的姿态检测里面,也算是跻身前列。
谷歌给Movenet加了6个回归头来进行监督训练,除了使用coco以外,还是用了许多额外数据来训练,最终的姿态检测效果非常不错。但是也有问题:
• 基于tensorflow,似乎没有开源整体训练代码;
• 没有pytorch的版本;
关于movenet的部署,其实已经有一些人做过一些类似的工作,但是我们今天的题目是一种“新型的部署方式”,肯定不同于已有的方案。我们的方式也很简单,直接:
直接将模型从pytorch转到我们自定义格式,同时使用我们完全自建的推理引擎进行推理,这里面,不会用到任何第三方库。(包括ONNX,主要目的就是通过这篇文章告诉你,不用ONNX,你的模型也可以跑的飞起)。
ONNX对比自定义模式可视化
我们自建的模型格式,有很多优点啊。简单列举几个:
• 简单;
• 出奇的简单;
• 算子集精简;
• 完全与pytorch的算子贴合。
这里展示一个案例。MoveNet举个例子。我们把MoveNet的模型转到我们自己的格式,同时我们也道出了onnx,来对比一下:

这是onnx。
然后这是我们自定义的:

看看onnx的算子集合:
Conv,Clip,Add,Resize,Relu,Squeeze,Transpose,Sigmoid,Cast,Mul,Reshape,ArgMax,Div,Less,Xor,Mod,Equal,Not,And,Sub,Where,Unsqueeze,Expand,GatherElements,Concat,Gather,Sqrt这还是精简之后的。而我们自己的算子集合只有:
conv2,relu6,interpolate,permute,suqueeze,expand_dims,gather,concat,reshape,binary,unary,pad没了。
看看MoveNet的输入,在onnx里面的样子;

再看看我们自定义的:

简单很多。而且我们的算子更加贴合pytorch。(我们一开始就不打算适配多个框架的),凡事都要有取舍,什么都想要的结果可能就是什么都达不到最好。
特别是算子转换,我们的解析方式更加贴合 网络原始定义。比如这里的激活函数本来就是relu6,我们会解析为relu6,而ONNX会解析为Clip。虽然计算结果一样,但是着实没有必要,可能还会让别人看不懂。
这是我们转换出来的自定义模型的后处理:
整体来看还是很清晰的。虽然比较难简化更多,但至少比onnx还要简单不少,并且整个的算子集合其实更少。
运行!
既然我们已经道出了模型,接下来,先来对一下结果:
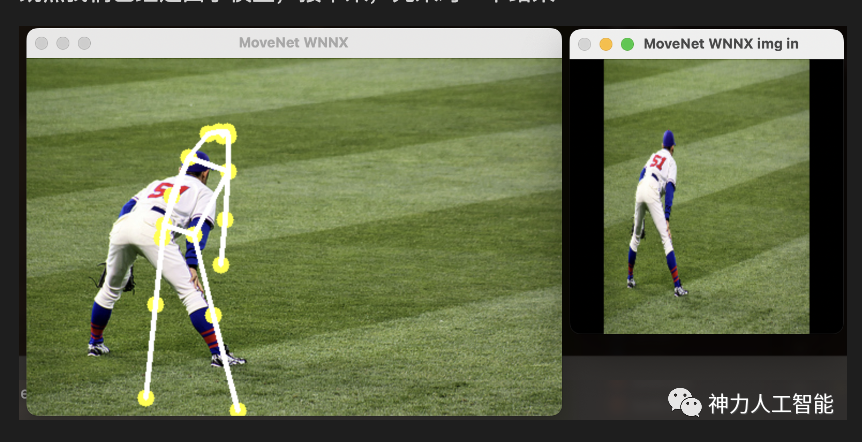
啪!打脸!
看起来大概对了,但是好像有没有完全对。
更改预处理之后结果:

这下舒服多了。
可以看到结果完全正确! 我们用自建框架推理了一个后处理非常复杂、充满了Gather,各种Int与float转换的模型!!
上面的速度是实时的效果,基本上可以做到实时,请注意,官方的SinglePerson测试的输入是192,我们的是256. 稍微大一些。
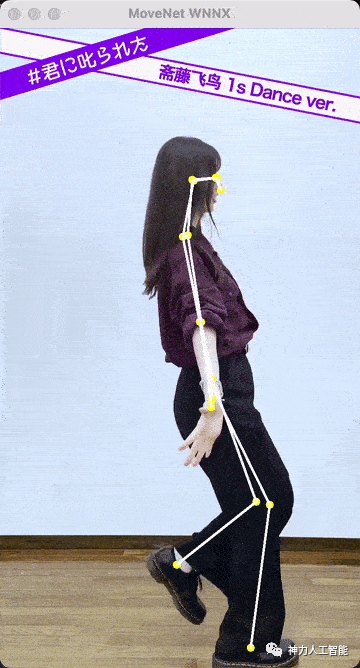
感觉效果还不错。不愧是谷歌爸爸出品,这个速度,这个精度,已经很不错了。
这里是使用自定义框架的全部推理代码:
int main(int argc, char **argv) {
if (argc < 2) {
std::cout << "Usage: nanodet wnnx_model_f image_f\n";
}
std::string model_f = argv[1];
std::string data_f = argv[2];
const std::vector<float> means = {127.5f, 127.5f, 127.5f};
const std::vector<float> stds = {127.5f, 127.5f, 127.5f};
auto wnn_model = NNForward(1, 2);
LOG(INFO) << "nnforward initiated.";
if (wnn_model.load_from_file(model_f)) {
LOG(INFO) << "model loaded.";
auto in_names = wnn_model.get_input_names();
auto out_names = wnn_model.get_output_names();
} else {
LOG(INFO) << "model might load failed.";
}
mjolnir::iter::ImageSourceIter<cv::Mat> sourceIter(data_f);
while (sourceIter.ok) {
cv::Mat img = sourceIter.next();
auto img_in = preprocess(img);
int raw_width = img.cols;
int raw_height = img.rows;
CHECK(img_in.rows == 256) << "inputs must resized to 256!!";
Tensor input_tensor;
input_tensor.Create({1, 3, img_in.rows, img_in.cols}, wnn::DT_FLOAT);
input_tensor.from_pixels(img_in.data, means, stds, wnn::PIXEL_BGR2RGB);
std::vector<Tensor> inputs;
inputs.push_back(input_tensor);
std::vector<Tensor> outputs;
auto res = wnn_model.infer(inputs, outputs);
auto poses = postprocess(outputs[0], raw_width, raw_height);
mjolnir::vis::renderPoseCoco17(poses, img);
cv::imshow("MoveNet WNNX", img);
sourceIter.waitKey();
}
}没有错,就是这么简单!
总结
通过对Movenet的部署,我们进一步验证了上一次自建框架的通用性。 同时,我们也可以在CPU上一非常快的速度得到一个2D姿态检测模型。请注意,这不依赖于NCNN或者MNN。
请注意,这个模型并不是二阶段的,但却能得到一个比较精准的姿态检测结果!
这个可以用来做什么?
比如俯卧撑计数器:
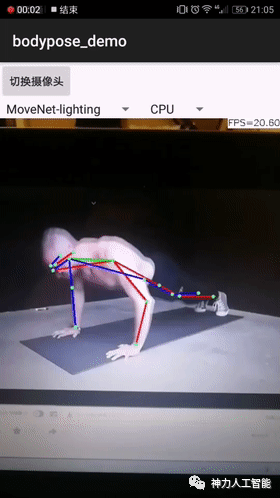
等等。总是你需要用姿态检测都可以用它作为底层驱动。
 关注公众号
关注公众号
 计算机视觉研究院
计算机视觉研究院
 集智书童
集智书童
 极市平台
极市平台

 Jack Cui
Jack Cui